_posts/2018-02-04-Idea-快捷键.md�����������������������������������������������������������������0000664�0001750�0001750�00000041531�14127043406�020027� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: IDEA快捷键使用 subtitle: 熟练使用IDEA快捷键,开发效率飞一般的感觉 date: 2018-02-04 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - IDEA快捷键 —
Debug 常用快捷键
| 快捷键 | 介绍 |
|---|---|
| F7 | 在 Debug 模式下,进入下一步,如果当前行断点是一个方法,则进入当前方法体内,如果该方法体还有方法,则不会进入该内嵌的方法中 必备 |
| F8 | 在 Debug 模式下,进入下一步,如果当前行断点是一个方法,则不进入当前方法体内 必备 |
| F9 | 在 Debug 模式下,恢复程序运行,但是如果该断点下面代码还有断点则停在下一个断点上 必备 |
| Alt + F8 | 在 Debug 的状态下,选中对象,弹出可输入计算表达式调试框,查看该输入内容的调试结果 必备 |
| Ctrl + F8 | 在 Debug 模式下,设置光标当前行为断点,如果当前已经是断点则去掉断点 |
| Shift + F7 | 在 Debug 模式下,智能步入。断点所在行上有多个方法调用,会弹出进入哪个方法 |
| Shift + F8 | 在 Debug 模式下,跳出,表现出来的效果跟 F9 一样 |
| Ctrl + Shift + F8 | 在 Debug 模式下,指定断点进入条件 |
| Alt + Shift + F7 | 在 Debug 模式下,进入下一步,如果当前行断点是一个方法,则进入当前方法体内,如果方法体还有方法,则会进入该内嵌的方法中,依此循环进入 |
| Drop Frame | 这个不是一个快捷键,而是一个 Debug 面板上的按钮。该按钮可以用来退回到当前停住的断点的上一层方法上,可以让过掉的断点重新来过 |
Ctrl
| 快捷键 | 介绍 |
|---|---|
| Ctrl + F | 在当前文件进行文本查找 (必备) |
| Ctrl + R | 在当前文件进行文本替换 (必备) |
| Ctrl + Z | 撤销 (必备) |
| Ctrl + Y | 删除光标所在行 或 删除选中的行 (必备) |
| Ctrl + X | 剪切光标所在行 或 剪切选择内容 |
| Ctrl + C | 复制光标所在行 或 复制选择内容 |
| Ctrl + D | 复制光标所在行 或 复制选择内容,并把复制内容插入光标位置下面 (必备) |
| Ctrl + W | 递进式选择代码块。可选中光标所在的单词或段落,连续按会在原有选中的基础上再扩展选中范围 (必备) |
| Ctrl + E | 显示最近打开的文件记录列表 (必备) |
| Ctrl + N | 根据输入的 类名 查找类文件 (必备) |
| Ctrl + G | 在当前文件跳转到指定行处 |
| Ctrl + J | 插入自定义动态代码模板 (必备) |
| Ctrl + P | 方法参数提示显示 (必备) |
| Ctrl + Q | 光标所在的变量 / 类名 / 方法名等上面(也可以在提示补充的时候按),显示文档内容 |
| Ctrl + U | 前往当前光标所在的方法的父类的方法 / 接口定义 (必备) |
| Ctrl + B | 进入光标所在的方法/变量的接口或是定义处,等效于 Ctrl + 左键单击 (必备) |
| Ctrl + K | 版本控制提交项目,需要此项目有加入到版本控制才可用 |
| Ctrl + T | 版本控制更新项目,需要此项目有加入到版本控制才可用 |
| Ctrl + H | 显示当前类的层次结构 |
| Ctrl + O | 选择可重写的方法 |
| Ctrl + I | 选择可继承的方法 |
| Ctrl + + | 展开代码 |
| Ctrl + - | 折叠代码 |
| Ctrl + / | 注释光标所在行代码,会根据当前不同文件类型使用不同的注释符号 (必备) |
| Ctrl + [ | 移动光标到当前所在代码的花括号开始位置 |
| Ctrl + ] | 移动光标到当前所在代码的花括号结束位置 |
| Ctrl + F1 | 在光标所在的错误代码处显示错误信息 (必备) |
| Ctrl + F3 | 调转到所选中的词的下一个引用位置 (必备) |
| Ctrl + F4 | 关闭当前编辑文件 |
| Ctrl + F8 | 在 Debug 模式下,设置光标当前行为断点,如果当前已经是断点则去掉断点 |
| Ctrl + F9 | 执行 Make Project 操作 |
| Ctrl + F11 | 选中文件 / 文件夹,使用助记符设定 / 取消书签 (必备) |
| Ctrl + F12 | 弹出当前文件结构层,可以在弹出的层上直接输入,进行筛选 |
| Ctrl + Tab | 编辑窗口切换,如果在切换的过程又加按上delete,则是关闭对应选中的窗口 |
| Ctrl + End | 跳到文件尾 |
| Ctrl + Home | 跳到文件头 |
| Ctrl + Space | 基础代码补全,默认在 Windows 系统上被输入法占用,需要进行修改,建议修改为 Ctrl + 逗号 (必备) |
| Ctrl + Delete | 删除光标后面的单词或是中文句 (必备) |
| Ctrl + BackSpace | 删除光标前面的单词或是中文句 (必备) |
| Ctrl + 1,2,3…9 | 定位到对应数值的书签位置 (必备) |
| Ctrl + 左键单击 | 在打开的文件标题上,弹出该文件路径 (必备) |
| Ctrl + 光标定位 | 按 Ctrl 不要松开,会显示光标所在的类信息摘要 |
| Ctrl + 左方向键 | 光标跳转到当前单词 / 中文句的左侧开头位置 (必备) |
| Ctrl + 右方向键 | 光标跳转到当前单词 / 中文句的右侧开头位置 (必备) |
| Ctrl + 前方向键 | 等效于鼠标滚轮向前效果 (必备) |
| Ctrl + 后方向键 | 等效于鼠标滚轮向后效果 (必备) |
Alt
| 快捷键 | 介绍 |
|---|---|
| Alt + ` | 显示版本控制常用操作菜单弹出层 (必备) |
| Alt + Q | 弹出一个提示,显示当前类的声明 / 上下文信息 |
| Alt + F1 | 显示当前文件选择目标弹出层,弹出层中有很多目标可以进行选择 (必备) |
| Alt + F2 | 对于前面页面,显示各类浏览器打开目标选择弹出层 |
| Alt + F3 | 选中文本,逐个往下查找相同文本,并高亮显示 |
| Alt + F7 | 查找光标所在的方法 / 变量 / 类被调用的地方 |
| Alt + F8 | 在 Debug 的状态下,选中对象,弹出可输入计算表达式调试框,查看该输入内容的调试结果 |
| Alt + Home | 定位 / 显示到当前文件的 Navigation Bar |
| Alt + Enter | IntelliJ IDEA 根据光标所在问题,提供快速修复选择,光标放在的位置不同提示的结果也不同 (必备) |
| Alt + Insert | 代码自动生成,如生成对象的 set / get 方法,构造函数,toString() 等 (必备) |
| Alt + 左方向键 | 切换当前已打开的窗口中的子视图,比如Debug窗口中有Output、Debugger等子视图,用此快捷键就可以在子视图中切换 (必备) |
| Alt + 右方向键 | 按切换当前已打开的窗口中的子视图,比如Debug窗口中有Output、Debugger等子视图,用此快捷键就可以在子视图中切换 (必备) |
| Alt + 前方向键 | 当前光标跳转到当前文件的前一个方法名位置 (必备) |
| Alt + 后方向键 | 当前光标跳转到当前文件的后一个方法名位置 (必备) |
| Alt +1,2,3…9 | 显示对应数值的选项卡,其中 1 是 Project 用得最多 (必备) |
Shift
| 快捷键 | 介绍 |
|---|---|
| Shift + F1 | 如果有外部文档可以连接外部文档 |
| Shift + F2 | 跳转到上一个高亮错误 或 警告位置 |
| Shift + F3 | 在查找模式下,查找匹配上一个 |
| Shift + F4 | 对当前打开的文件,使用新Windows窗口打开,旧窗口保留 |
| Shift + F6 | 对文件 / 文件夹 重命名 |
| Shift + F7 | 在 Debug 模式下,智能步入。断点所在行上有多个方法调用,会弹出进入哪个方法 |
| Shift + F8 | 在 Debug 模式下,跳出,表现出来的效果跟 F9 一样 |
| Shift + F9 | 等效于点击工具栏的 Debug 按钮 |
| Shift + F10 | 等效于点击工具栏的 Run 按钮 |
| Shift + F11 | 弹出书签显示层 (必备) |
| Shift + Tab | 取消缩进 (必备) |
| Shift + ESC | 隐藏当前 或 最后一个激活的工具窗口 |
| Shift + End | 选中光标到当前行尾位置 |
| Shift + Home | 选中光标到当前行头位置 |
| Shift + Enter | 开始新一行。光标所在行下空出一行,光标定位到新行位置 (必备) |
| Shift + 左键单击 | 在打开的文件名上按此快捷键,可以关闭当前打开文件 (必备) |
| Shift + 滚轮前后滚动 | 当前文件的横向滚动轴滚动 (必备) |
Ctrl + Alt
| 快捷键 | 介绍 |
|---|---|
| Ctrl + Alt + L | 格式化代码,可以对当前文件和整个包目录使用 (必备) |
| Ctrl + Alt + O | 优化导入的类,可以对当前文件和整个包目录使用 (必备) |
| Ctrl + Alt + I | 光标所在行 或 选中部分进行自动代码缩进,有点类似格式化 |
| Ctrl + Alt + T | 对选中的代码弹出环绕选项弹出层 (必备) |
| Ctrl + Alt + J | 弹出模板选择窗口,将选定的代码加入动态模板中 |
| Ctrl + Alt + H | 调用层次 |
| Ctrl + Alt + B | 在某个调用的方法名上使用会跳到具体的实现处,可以跳过接口 |
| Ctrl + Alt + C | 重构-快速提取常量 |
| Ctrl + Alt + F | 重构-快速提取成员变量 |
| Ctrl + Alt + V | 重构-快速提取变量 |
| Ctrl + Alt + Y | 同步、刷新 |
| Ctrl + Alt + S | 打开 IntelliJ IDEA 系统设置 (必备) |
| Ctrl + Alt + F7 | 显示使用的地方。寻找被该类或是变量被调用的地方,用弹出框的方式找出来 |
| Ctrl + Alt + F11 | 切换全屏模式 |
| Ctrl + Alt + Enter | 光标所在行上空出一行,光标定位到新行 (必备) |
| Ctrl + Alt + Home | 弹出跟当前文件有关联的文件弹出层 |
| Ctrl + Alt + Space | 类名自动完成 |
| Ctrl + Alt + 左方向键 | 退回到上一个操作的地方 (必备) |
| Ctrl + Alt + 右方向键 | 前进到上一个操作的地方 (必备) |
| Ctrl + Alt + 前方向键 | 在查找模式下,跳到上个查找的文件 |
| Ctrl + Alt + 后方向键 | 在查找模式下,跳到下个查找的文件 |
| Ctrl + Alt + 右括号(]) | 在打开多个项目的情况下,切换下一个项目窗口 |
| Ctrl + Alt + 左括号([) | 在打开多个项目的情况下,切换上一个项目窗口 |
Ctrl + Shift
| 快捷键 | 介绍 |
|---|---|
| Ctrl + Shift + F | 根据输入内容查找整个项目 或 指定目录内文件 (必备) |
| Ctrl + Shift + R | 根据输入内容替换对应内容,范围为整个项目 或 指定目录内文件 (必备) |
| Ctrl + Shift + J | 自动将下一行合并到当前行末尾 (必备) |
| Ctrl + Shift + Z | 取消撤销 (必备) |
| Ctrl + Shift + W | 递进式取消选择代码块。可选中光标所在的单词或段落,连续按会在原有选中的基础上再扩展取消选中范围(必备) |
| Ctrl + Shift + N | 通过文件名定位 / 打开文件 / 目录,打开目录需要在输入的内容后面多加一个正斜杠 (必备) |
| Ctrl + Shift + U | 对选中的代码进行大 / 小写轮流转换 (必备) |
| Ctrl + Shift + T | 对当前类生成单元测试类,如果已经存在的单元测试类则可以进行选择 (必备) |
| Ctrl + Shift + C | 复制当前文件磁盘路径到剪贴板 (必备) |
| Ctrl + Shift + V | 弹出缓存的最近拷贝的内容管理器弹出层 |
| Ctrl + Shift + E | 显示最近修改的文件列表的弹出层 |
| Ctrl + Shift + H | 显示方法层次结构 |
| Ctrl + Shift + B | 跳转到类型声明处 (必备) |
| Ctrl + Shift + I | 快速查看光标所在的方法 或 类的定义 |
| Ctrl + Shift + A | 查找动作 / 设置 |
| Ctrl + Shift + / | 代码块注释 (必备) |
| Ctrl + Shift + [ | 选中从光标所在位置到它的顶部中括号位置 (必备) |
| Ctrl + Shift + ] | 选中从光标所在位置到它的底部中括号位置 (必备) |
| Ctrl + Shift + + | 展开所有代码 (必备) |
| Ctrl + Shift + - | 折叠所有代码 (必备) |
| Ctrl + Shift + F7 | 高亮显示所有该选中文本,按Esc高亮消失 (必备) |
| Ctrl + Shift + F8 | 在 Debug 模式下,指定断点进入条件 |
| Ctrl + Shift + F9 | 编译选中的文件 / 包 / Module |
| Ctrl + Shift + F12 | 编辑器最大化 (必备) |
| Ctrl + Shift + Space | 智能代码提示 |
| Ctrl + Shift + Enter | 自动结束代码,行末自动添加分号 (必备) |
| Ctrl + Shift + Backspace | 退回到上次修改的地方 (必备) |
| Ctrl + Shift + 1,2,3…9 | 快速添加指定数值的书签 (必备) |
| Ctrl + Shift + 左键单击 | 把光标放在某个类变量上,按此快捷键可以直接定位到该类中 (必备) |
| Ctrl + Shift + 左方向键 | 在代码文件上,光标跳转到当前单词 / 中文句的左侧开头位置,同时选中该单词 / 中文句 (必备) |
| Ctrl + Shift + 右方向键 | 在代码文件上,光标跳转到当前单词 / 中文句的右侧开头位置,同时选中该单词 / 中文句 (必备) |
| Ctrl + Shift + 前方向键 | 光标放在方法名上,将方法移动到上一个方法前面,调整方法排序 (必备) |
| Ctrl + Shift + 后方向键 | 光标放在方法名上,将方法移动到下一个方法前面,调整方法排序 (必备) |
Alt + Shift
| 快捷键 | 介绍 |
|---|---|
| Alt + Shift + N | 选择 / 添加 task (必备) |
| Alt + Shift + F | 显示添加到收藏夹弹出层 / 添加到收藏夹 |
| Alt + Shift + C | 查看最近操作项目的变化情况列表 |
| Alt + Shift + I | 查看项目当前文件 |
| Alt + Shift + F7 | 在 Debug 模式下,下一步,进入当前方法体内,如果方法体还有方法,则会进入该内嵌的方法中,依此循环进入 |
| Alt + Shift + F9 | 弹出 Debug 的可选择菜单 |
| Alt + Shift + F10 | 弹出 Run 的可选择菜单 |
| Alt + Shift + 左键双击 | 选择被双击的单词 / 中文句,按住不放,可以同时选择其他单词 / 中文句 (必备) |
| Alt + Shift + 前方向键 | 移动光标所在行向上移动 (必备) |
| Alt + Shift + 后方向键 | 移动光标所在行向下移动 (必备) |
Ctrl + Shift + Alt
| 快捷键 | 介绍 |
|---|---|
| Ctrl + Shift + Alt + V | 无格式黏贴 (必备) |
| Ctrl + Shift + Alt + N | 前往指定的变量 / 方法 |
| Ctrl + Shift + Alt + S | 打开当前项目设置 (必备) |
| Ctrl + Shift + Alt + C | 复制参考信息 |
其他
| 快捷键 | 介绍 |
|---|---|
| F2 | 跳转到下一个高亮错误 或 警告位置 (必备) |
| F3 | 在查找模式下,定位到下一个匹配处 |
| F4 | 编辑源 (必备) |
| F7 | 在 Debug 模式下,进入下一步,如果当前行断点是一个方法,则进入当前方法体内,如果该方法体还有方法,则不会进入该内嵌的方法中 |
| F8 | 在 Debug 模式下,进入下一步,如果当前行断点是一个方法,则不进入当前方法体内 |
| F9 | 在 Debug 模式下,恢复程序运行,但是如果该断点下面代码还有断点则停在下一个断点上 |
| F11 | 添加书签 (必备) |
| F12 | 回到前一个工具窗口 (必备) |
| Tab | 缩进 (必备) |
| ESC | 从工具窗口进入代码文件窗口 (必备) |
| 连按两次Shift | 弹出 Search Everywhere 弹出层 |
| 功能 | 快捷键 | 功能描述 |
|---|---|---|
| Enter Full Screen | Alt+F | 隐藏桌面的任务栏和编译器顶部的窗体 |
| Enter Presentation Mode | Alt+D | 无扰模式,很高端的效果 |
| Tool Buttons | Alt+T | 隐藏/显示工具按钮栏 |
| Status Bar | Alt+S | 隐藏/显示状态栏 |
| start ssh session | Ctrl + Alt + Shift + O | 打开SSH会话连接 |
| 快捷键 | 功能 |
|---|---|
| Ctrl + Y | 删除一行 |
| Ctrl + W | 选中代码,连续按会有其他效果 |
| Ctrl + Z | 撤销操作 |
| Ctrl + Shift + Z | 恢复Ctrl+Z撤销的操作 |
| Alt + Enter | 引入类或提供给你选择的处理方法 |
| Alt/Ctrl + Shift + 上下 | 代码向上/下移动一行 |
| Alt + / | 复制上一个单词 |
| Alt + Shift + Enter | 自动补全分号 |
| Alt + Shift + V | 粘贴板历史 |
| Ctrl + F | 在本文件查找,可通过方向键移动选择(按Esc消失) |
| Ctrl + Shift + F | 在制定路径/模块/工程内查找 非常常用的一个功能,很多时候你想查找一个内容但是不一定知道它在哪里,这个就很实用 |
| Ctrl + R | 在本文件内查找/替换(按Esc消失) |
| Ctrl + N | 在本工程类查询某个类 |
| Ctrl + Shift + N | 查询某个类(不限本工程) 看源码很实用,比如我想看看jdk里面TreeMap这个类的代码,就可以用这个功能 |
快捷键 | 功能 — | — Ctrl + H | 查看一个类的继承关系 Ctrl + B | 查看一个类或者变量的申明 Alt + F7 | 查找一个属性或方法被谁调用 Alt + 上下 | 跳到上/下一个方法(或属性) Ctrl + 上下 | 上下滑屏但是不移动光标 Alt + 左右 | 同时打开多个文件时切换代码视图 Ctrl + Alt + 左右 | 返回至上次浏览的位置 非常实用,在多个文件代码中遨游的时候能够快速回到想去的位置 Ctrl + 上下 | 光标跳转到第一行或最后一行 Alt + Shift + C | 最近修改的代码 Ctrl + Q | 显示注释文档 Ctrl + P | 查看函数参数 Ctrl + J | 代码模板 Alt + Delete | 安全删除字段或方法 Ctrl + Alt + N | 去除一些多余的赋值过程或者函数 Shift + F6 | 重命名类或者变量 Alt + F12 | 打开命令行终端 Alt + 1 | 打开工程结构 Alt + 7 | 打开类结构 Alt + 9 | 打开change �����������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-02-06-Linux-常用命令.md�������������������������������������������������������������0000664�0001750�0001750�00000043063�13763566257�021425� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: Linux常用命令 subtitle: Bash 常用命令 date: 2018-02-06 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Linux —
Bash 常用命令
基础常用命令
某个命令 --h,对这个命令进行解释某个命令 --help,解释这个命令(更详细)man某个命令,文档式解释这个命令(更更详细)(执行该命令后,还可以按/+关键字进行查询结果的搜索)Ctrl + c,结束命令TAB键,自动补全命令(按一次自动补全,连续按两次,提示所有以输入开头字母的所有命令)键盘上下键,输入临近的历史命令history,查看所有的历史命令Ctrl + r,进入历史命令的搜索功能模式clear,清除屏幕里面的所有命令pwd,显示当前目录路径(常用)firefox&,最后后面的 & 符号,表示使用后台方式打开 Firefox,然后显示该进程的 PID 值jobs,查看后台运行的程序列表ifconfig,查看内网 IP 等信息(常用)curl ifconfig.me,查看外网 IP 信息curl ip.cn,查看外网 IP 信息locate 搜索关键字,快速搜索系统文件/文件夹(类似 Windows 上的 everything 索引式搜索)(常用)updatedb,配合上面的 locate,给 locate 的索引更新(locate 默认是一天更新一次索引)(常用)
date,查看系统时间(常用)date -s20080103,设置日期(常用)date -s18:24,设置时间,如果要同时更改 BIOS 时间,再执行hwclock --systohc(常用)
cal,在终端中查看日历,肯定没有农历显示的uptime,查看系统已经运行了多久,当前有几个用户等信息(常用)cat 文件路名,显示文件内容(属于打印语句)cat -n 文件名,显示文件,并每一行内容都编号more 文件名,用分页的方式查看文件内容(按 space 翻下一页,按 Ctrl + B 返回上页)less文件名,用分页的方式查看文件内容(带上下翻页)- 按 j 向下移动,按 k 向上移动
- 按 / 后,输入要查找的字符串内容,可以对文件进行向下查询,如果存在多个结果可以按 n 调到下一个结果出
- 按 ? 后,输入要查找的字符串内容,可以对文件进行向上查询,如果存在多个结果可以按 n 调到下一个结果出
shutdownshutdown -hnow,立即关机shutdown -h+10,10 分钟后关机shutdown -h23:30,23:30 关机shutdown -rnew,立即重启
poweroff,立即关机(常用)reboot,立即重启(常用)zip mytest.zip /opt/test/,把 /opt 目录下的 test/ 目录进行压缩,压缩成一个名叫 mytest 的 zip 文件unzip mytest.zip,对 mytest.zip 这个文件进行解压,解压到当前所在目录unzip mytest.zip -d /opt/setups/,对 mytest.zip 这个文件进行解压,解压到 /opt/setups/ 目录下
tar -cvf mytest.tar mytest/,对 mytest/ 目录进行归档处理(归档和压缩不一样)tar -xvf mytest.tar,释放 mytest.tar 这个归档文件,释放到当前目录tar -xvf mytest.tar -C /opt/setups/,释放 mytest.tar 这个归档文件,释放到 /opt/setups/ 目录下
last,显示最近登录的帐户及时间lastlog,显示系统所有用户各自在最近登录的记录,如果没有登录过的用户会显示 从未登陆过ls,列出当前目录下的所有没有隐藏的文件 / 文件夹。ls -a,列出包括以.号开头的隐藏文件 / 文件夹(也就是所有文件)ls -R,显示出目录下以及其所有子目录的文件 / 文件夹(递归地方式,不显示隐藏的文件)ls -a -R,显示出目录下以及其所有子目录的文件 / 文件夹(递归地方式,显示隐藏的文件)ls -al,列出目录下所有文件(包含隐藏)的权限、所有者、文件大小、修改时间及名称(也就是显示详细信息)ls -ld 目录名,显示该目录的基本信息ls -t,依照文件最后修改时间的顺序列出文件名。ls -F,列出当前目录下的文件名及其类型。以 / 结尾表示为目录名,以 * 结尾表示为可执行文件,以 @ 结尾表示为符号连接ls -lg,同上,并显示出文件的所有者工作组名。ls -lh,查看文件夹类文件详细信息,文件大小,文件修改时间ls /opt | head -5,显示 opt 目录下前 5 条记录ls -l | grep '.jar',查找当前目录下所有 jar 文件ls -l /opt |grep "^-"|wc -l,统计 opt 目录下文件的个数,不会递归统计ls -lR /opt |grep "^-"|wc -l,统计 opt 目录下文件的个数,会递归统计ls -l /opt |grep "^d"|wc -l,统计 opt 目录下目录的个数,不会递归统计ls -lR /opt |grep "^d"|wc -l,统计 opt 目录下目录的个数,会递归统计ls -lR /opt |grep "js"|wc -l,统计 opt 目录下 js 文件的个数,会递归统计ls -l,列出目录下所有文件的权限、所有者、文件大小、修改时间及名称(也就是显示详细信息,不显示隐藏文件)。显示出来的效果如下:-rwxr-xr-x. 1 root root 4096 3月 26 10:57 其中最前面的 - 表示这是一个普通文件 lrwxrwxrwx. 1 root root 4096 3月 26 10:57 其中最前面的 l 表示这是一个链接文件 类似 Windows 的快捷方式 drwxr-xr-x. 5 root root 4096 3月 26 10:57 其中最前面的 d 表示这是一个目录
cd,目录切换cd ..,改变目录位置至当前目录的父目录(上级目录)。cd ~,改变目录位置至用户登录时的工作目录。cd 回车,回到家目录cd -,上一个工作目录cd dir1/,改变目录位置至 dir1 目录下。cd ~user,改变目录位置至用户的工作目录。cd ../user,改变目录位置至相对路径user的目录下。cd /../..,改变目录位置至绝对路径的目录位置下。
cp 源文件 目标文件,复制文件cp -r 源文件夹 目标文件夹,复制文件夹cp -r -v 源文件夹 目标文件夹,复制文件夹(显示详细信息,一般用于文件夹很大,需要查看复制进度的时候)cp /usr/share/easy-rsa/2.0/keys/{ca.crt,server.{crt,key},dh2048.pem,ta.key} /etc/openvpn/keys/,复制同目录下花括号中的文件
tar cpf - . | tar xpf - -C /opt,复制当前所有文件到 /opt 目录下,一般如果文件夹文件多的情况下用这个更好,用 cp 比较容易出问题mv 文件 目标文件夹,移动文件到目标文件夹mv 文件,不指定目录重命名后的名字,用来重命名文件
touch 文件名,创建一个空白文件/更新已有文件的时间(后者少用)mkdir 文件夹名,创建文件夹mkdir -p /opt/setups/nginx/conf/,创建一个名为 conf 文件夹,如果它的上级目录 nginx 没有也会跟着一起生成,如果有则跳过rmdir 文件夹名,删除文件夹(只能删除文件夹里面是没有东西的文件夹)rm 文件,删除文件rm -r 文件夹,删除文件夹rm -r -i 文件夹,在删除文件夹里的文件会提示(要的话,在提示后面输入yes)rm -r -f 文件夹,强制删除rm -r -f 文件夹1/ 文件夹2/ 文件夹3/删除多个
find,高级查找find . -name *lin*,其中 . 代表在当前目录找,-name 表示匹配文件名 / 文件夹名,*lin* 用通配符搜索含有lin的文件或是文件夹find . -iname *lin*,其中 . 代表在当前目录找,-iname 表示匹配文件名 / 文件夹名(忽略大小写差异),*lin* 用通配符搜索含有lin的文件或是文件夹find / -name *.conf,其中 / 代表根目录查找,*.conf代表搜索后缀会.conf的文件find /opt -name .oh-my-zsh,其中 /opt 代表目录名,.oh-my-zsh 代表搜索的是隐藏文件 / 文件夹名字为 oh-my-zsh 的find /opt -type f -iname .oh-my-zsh,其中 /opt 代表目录名,-type f 代表只找文件,.oh-my-zsh 代表搜索的是隐藏文件名字为 oh-my-zsh 的find /opt -type d -iname .oh-my-zsh,其中 /opt 代表目录名,-type d 代表只找目录,.oh-my-zsh 代表搜索的是隐藏文件夹名字为 oh-my-zsh 的find . -name "lin*" -exec ls -l {} \;,当前目录搜索lin开头的文件,然后用其搜索后的结果集,再执行ls -l的命令(这个命令可变,其他命令也可以),其中 -exec 和 {} \; 都是固定格式find /opt -type f -size +800M -print0 | xargs -0 du -h | sort -nr,找出 /opt 目录下大于 800 M 的文件find / -name "*tower*" -exec rm {} \;,找到文件并删除find / -name "*tower*" -exec mv {} /opt \;,找到文件并移到 opt 目录find . -name "*" |xargs grep "youmeek",递归查找当前文件夹下所有文件内容中包含 youmeek 的文件find . -size 0 | xargs rm -f &,删除当前目录下文件大小为0的文件du -hm --max-depth=2 | sort -nr | head -12,找出系统中占用容量最大的前 12 个目录
cat /etc/resolv.conf,查看 DNS 设置netstat -tlunp,查看当前运行的服务,同时可以查看到:运行的程序已使用端口情况env,查看所有系统变量export,查看所有系统变量echoecho $JAVA_HOME,查看指定系统变量的值,这里查看的是自己配置的 JAVA_HOME。echo "字符串内容",输出 “字符串内容”echo > aa.txt,清空 aa.txt 文件内容(类似的还有:: > aa.txt,其中 : 是一个占位符, 不产生任何输出)
unset $JAVA_HOME,删除指定的环境变量ln -s /opt/data /opt/logs/data,表示给 /opt/logs 目录下创建一个名为 data 的软链接,该软链接指向到 /opt/datagrepshell grep -H '安装' *.sh,查找当前目录下所有 sh 类型文件中,文件内容包含安装的当前行内容grep 'test' java*,显示当前目录下所有以 java 开头的文件中包含 test 的行grep 'test' spring.ini docker.sh,显示当前目录下 spring.ini docker.sh 两个文件中匹配 test 的行
psps –ef|grep java,查看当前系统中有关 java 的所有进程ps -ef|grep --color java,高亮显示当前系统中有关 java 的所有进程
killkill 1234,结束 pid 为 1234 的进程kill -9 1234,强制结束 pid 为 1234 的进程(慎重)killall java,结束同一进程组内的所有为 java 进程ps -ef|grep hadoop|grep -v grep|cut -c 9-15|xargs kill -9,结束包含关键字 hadoop 的所有进程
headhead -n 10 spring.ini,查看当前文件的前 10 行内容
tailtail -n 10 spring.ini,查看当前文件的后 10 行内容tail -200f 文件名,查看文件被更新的新内容尾 200 行,如果文件还有在新增可以动态查看到(一般用于查看日记文件)
用户、权限-相关命令
- 使用 pem 证书登录:
ssh -i /opt/mykey.pem root@192.168.0.70- 证书权限不能太大,不然无法使用:
chmod 600 mykey.pem
- 证书权限不能太大,不然无法使用:
hostname,查看当前登陆用户全名cat /etc/group,查看所有组cat /etc/passwd,查看所有用户groups youmeek,查看 youmeek 用户属于哪个组useradd youmeek -g judasn,添加用户并绑定到 judasn 组下userdel -r youmeek,删除名字为 youmeek 的用户- 参数:
-r,表示删除用户的时候连同用户的家目录一起删除
- 参数:
- 修改普通用户 youmeek 的权限跟 root 权限一样:
- 常用方法(原理是把该用户加到可以直接使用 sudo 的一个权限状态而已):
- 编辑配置文件:
vim /etc/sudoers - 找到 98 行(预估),有一个:
root ALL=(ALL) ALL,在这一行下面再增加一行,效果如下:
root ALL=(ALL) ALL youmeek ALL=(ALL) ALL - 编辑配置文件:
- 另一种方法:
- 编辑系统用户的配置文件:
vim /etc/passwd,找到 root 和 youmeek 各自开头的那一行,比如 root 是:root:x:0:0:root:/root:/bin/zsh,这个代表的含义为:用户名:密码:UserId:GroupId:描述:家目录:登录使用的 shell - 通过这两行对比,我们可以直接修改 youmeek 所在行的 UserId 值 和 GroupId 值,都改为 0。
- 编辑系统用户的配置文件:
- 常用方法(原理是把该用户加到可以直接使用 sudo 的一个权限状态而已):
groupadd judasn,添加一个名为 judasn 的用户组groupdel judasn,删除一个名为 judasn 的用户组(前提:先删除组下面的所有用户)usermod 用户名 -g 组名,把用户修改到其他组下passwd youmeek,修改 youmeek 用户的密码(前提:只有 root 用户才有修改其他用户的权限,其他用户只能修改自己的)chmod 777 文件名/目录,给指定文件增加最高权限,系统中的所有人都可以进行读写。- linux 的权限分为 rwx。r 代表:可读,w 代表:可写,x 代表:可执行
- 这三个权限都可以转换成数值表示,r = 4,w = 2,x = 1,- = 0,所以总和是 7,也就是最大权限。第一个 7 是所属主(user)的权限,第二个 7 是所属组(group)的权限,最后一位 7 是非本群组用户(others)的权限。
chmod -R 777 目录表示递归目录下的所有文件夹,都赋予 777 权限
su:切换到 root 用户,终端目录还是原来的地方(常用)su -:切换到 root 用户,其中 - 号另起一个终端并切换账号su 用户名,切换指定用户帐号登陆,终端目录还是原来地方。su - 用户名,切换到指定用户帐号登陆,其中 - 号另起一个终端并切换账号
exit,注销当前用户(常用)sudo 某个命令,使用管理员权限使用命令,使用 sudo 回车之后需要输入当前登录账号的密码。(常用)passwd,修改当前用户密码(常用)- 添加临时账号,并指定用户根目录,并只有可读权限方法
- 添加账号并指定根目录(用户名 tempuser):
useradd -d /data/logs -m tempuser - 设置密码:
passwd tempuser回车设置密码 - 删除用户(该用户必须退出 SSH 才能删除成功),也会同时删除组:
userdel tempuser
- 添加账号并指定根目录(用户名 tempuser):
磁盘管理
df -h,自动以合适的磁盘容量单位查看磁盘大小和使用空间df -k,以磁盘容量单位 K 为数值结果查看磁盘使用情况df -m,以磁盘容量单位 M 为数值结果查看磁盘使用情况
du -sh /opt,查看 opt 这个文件夹大小 (h 的意思 human-readable 用人类可读性较好方式显示,系统会自动调节单位,显示合适大小的单位)du -sh ./*,查看当前目录下所有文件夹大小 (h 的意思 human-readable 用人类可读性较好方式显示,系统会自动调节单位,显示合适大小的单位)du -sh /opt/setups/,显示 /opt/setups/ 目录所占硬盘空间大小(s 表示 –summarize 仅显示总计,即当前目录的大小。h 表示 –human-readable 以 KB,MB,GB 为单位,提高信息的可读性)mount /dev/sdb5 /newDir/,把分区 sdb5 挂载在根目录下的一个名为 newDir 的空目录下,需要注意的是:这个目录最好为空,不然已有的那些文件将看不到,除非卸载挂载。- 挂载好之后,通过:
df -h,查看挂载情况。
- 挂载好之后,通过:
umount /newDir/,卸载挂载,用目录名- 如果这样卸载不了可以使用:
umount -l /newDir/
- 如果这样卸载不了可以使用:
umount /dev/sdb5,卸载挂载,用分区名
wget 下载文件
- 常规下载:
wget http://www.gitnavi.com/index.html - 自动断点下载:
wget -c http://www.gitnavi.com/index.html - 后台下载:
wget -b http://www.gitnavi.com/index.html - 伪装代理名称下载:
wget --user-agent="Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.204 Safari/534.16" http://www.gitnavi.com/index.html - 限速下载:
wget --limit-rate=300k http://www.gitnavi.com/index.html - 批量下载:
wget -i /opt/download.txt,一个下载地址一行 - 后台批量下载:
wget -b -c -i /opt/download.txt,一个下载地址一行
其他常用命令
- 编辑 hosts 文件:
vim /etc/hosts,添加内容格式:127.0.0.1 www.youmeek.com - RPM 文件操作命令:
- 安装
rpm -i example.rpm,安装 example.rpm 包rpm -iv example.rpm,安装 example.rpm 包并在安装过程中显示正在安装的文件信息rpm -ivh example.rpm,安装 example.rpm 包并在安装过程中显示正在安装的文件信息及安装进度
- 查询
rpm -qa | grep jdk,查看 jdk 是否被安装rpm -ql jdk,查看 jdk 是否被安装
- 卸载
rpm -e jdk,卸载 jdk(一般卸载的时候都要先用 rpm -qa 看下整个软件的全名)
- 安装
- YUM 软件管理:
yum install -y httpd,安装 apacheyum remove -y httpd,卸载 apacheyum info -y httpd,查看 apache 版本信息yum list --showduplicates httpd,查看可以安装的版本yum install httpd-查询到的版本号,安装指定版本- 更多命令可以看:http://man.linuxde.net/yum
- 查看某个配置文件,排除掉里面以 # 开头的注释内容:
grep '^[^#]' /etc/openvpn/server.conf
- 查看某个配置文件,排除掉里面以 # 开头和 ; 开头的注释内容:
grep '^[^#;]' /etc/openvpn/server.conf
资料
- http://wenku.baidu.com/view/1ad19bd226fff705cc170af3.html
- http://blog.csdn.net/nzing/article/details/9166057
- http://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/wget.html
- https://www.jianshu.com/p/180fb11a5b96
�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-03-03-Git-飞行指南.md���������������������������������������������������������������0000664�0001750�0001750�00000126372�14125045722�020555� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: Git飞行规则(Flight Rules)
subtitle: 这是一篇给宇航员(这里就是指使用Git的程序员们)的指南,用来指导问题出现后的应对之法。
date: 2018-03-03
author: 转载,出处不详
header-img: /img/post-bg-article.jpg
catalog: true
tags:
-
Git
-
Git飞行规则(Flight Rules)
前言
- 英文原版README
什么是”飞行规则”?
这是一篇给宇航员(这里就是指使用Git的程序员们)的指南,用来指导问题出现后的应对之法。
飞行规则(Flight Rules) 是记录在手册上的来之不易的一系列知识,记录了某个事情发生的原因,以及怎样一步一步的进行处理。本质上, 它们是特定场景的非常详细的标准处理流程。 […]
自20世纪60年代初以来,NASA一直在捕捉(capturing)我们的失误,灾难和解决方案, 当时水星时代(Mercury-era)的地面小组首先开始将“经验教训”收集到一个纲要(compendium)中,该纲现在已经有上千个问题情景,从发动机故障到破损的舱口把手到计算机故障,以及它们对应的解决方案。
— Chris Hadfield, 一个宇航员的生活指南(An Astronaut’s Guide to Life)。
这篇文章的约定
为了清楚的表述,这篇文档里的所有例子使用了自定义的bash 提示,以便指示当前分支和是否有暂存的变化(changes)。分支名用小括号括起来,分支名后面跟的*表示暂存的变化(changes)。
- 编辑提交(editting commits)
- 暂存(Staging)
- 未暂存(Unstaged)的内容
- 分支(Branches)
- Rebasing 和合并(Merging)
- Stash
- 杂项(Miscellaneous Objects)
- 跟踪文件(Tracking Files)
- 配置(Configuration)
- 我不知道我做错了些什么
- 其它资源(Other Resources)
编辑提交(editting commits)
我刚才提交了什么?
如果你用 git commit -a 提交了一次变化(changes),而你又不确定到底这次提交了哪些内容。 你就可以用下面的命令显示当前HEAD上的最近一次的提交(commit):
(master)$ git show
或者
$ git log -n1 -p
我的提交信息(commit message)写错了
如果你的提交信息(commit message)写错了且这次提交(commit)还没有推(push), 你可以通过下面的方法来修改提交信息(commit message):
$ git commit --amend --only
这会打开你的默认编辑器, 在这里你可以编辑信息. 另一方面, 你也可以用一条命令一次完成:
$ git commit --amend --only -m 'xxxxxxx'
如果你已经推(push)了这次提交(commit), 你可以修改这次提交(commit)然后强推(force push), 但是不推荐这么做。
我提交(commit)里的用户名和邮箱不对
如果这只是单个提交(commit),修改它:
$ git commit --amend --author "New Authorname <authoremail@mydomain.com>"
如果你需要修改所有历史, 参考 ‘git filter-branch’的指南页.
我想从一个提交(commit)里移除一个文件
通过下面的方法,从一个提交(commit)里移除一个文件:
$ git checkout HEAD^ myfile
$ git add -A
$ git commit --amend
这将非常有用,当你有一个开放的补丁(open patch),你往上面提交了一个不必要的文件,你需要强推(force push)去更新这个远程补丁。
我想删除我的的最后一次提交(commit)
如果你需要删除推了的提交(pushed commits),你可以使用下面的方法。可是,这会不可逆的改变你的历史,也会搞乱那些已经从该仓库拉取(pulled)了的人的历史。简而言之,如果你不是很确定,千万不要这么做。
$ git reset HEAD^ --hard
$ git push -f [remote] [branch]
如果你还没有推到远程, 把Git重置(reset)到你最后一次提交前的状态就可以了(同时保存暂存的变化):
(my-branch*)$ git reset --soft HEAD@{1}
这只能在没有推送之前有用. 如果你已经推了, 唯一安全能做的是 git revert SHAofBadCommit, 那会创建一个新的提交(commit)用于撤消前一个提交的所有变化(changes); 或者, 如果你推的这个分支是rebase-safe的 (例如: 其它开发者不会从这个分支拉), 只需要使用 git push -f; 更多, 请参考 the above section。
删除任意提交(commit)
同样的警告:不到万不得已的时候不要这么做.
$ git rebase --onto SHA1_OF_BAD_COMMIT^ SHA1_OF_BAD_COMMIT
$ git push -f [remote] [branch]
或者做一个 交互式rebase 删除那些你想要删除的提交(commit)里所对应的行。
我尝试推一个修正后的提交(amended commit)到远程,但是报错:
To https://github.com/yourusername/repo.git
! [rejected] mybranch -> mybranch (non-fast-forward)
error: failed to push some refs to 'https://github.com/tanay1337/webmaker.org.git'
hint: Updates were rejected because the tip of your current branch is behind
hint: its remote counterpart. Integrate the remote changes (e.g.
hint: 'git pull ...') before pushing again.
hint: See the 'Note about fast-forwards' in 'git push --help' for details.
注意, rebasing(见下面)和修正(amending)会用一个新的提交(commit)代替旧的, 所以如果之前你已经往远程仓库上推过一次修正前的提交(commit),那你现在就必须强推(force push) (-f)。 注意 – 总是 确保你指明一个分支!
(my-branch)$ git push origin mybranch -f
一般来说, 要避免强推. 最好是创建和推(push)一个新的提交(commit),而不是强推一个修正后的提交。后者会使那些与该分支或该分支的子分支工作的开发者,在源历史中产生冲突。
我意外的做了一次硬重置(hard reset),我想找回我的内容
如果你意外的做了 git reset --hard, 你通常能找回你的提交(commit), 因为Git对每件事都会有日志,且都会保存几天。
(master)$ git reflog
你将会看到一个你过去提交(commit)的列表, 和一个重置的提交。 选择你想要回到的提交(commit)的SHA,再重置一次:
(master)$ git reset --hard SHA1234
这样就完成了。
暂存(Staging)
我需要把暂存的内容添加到上一次的提交(commit)
(my-branch*)$ git commit --amend
我想要暂存一个新文件的一部分,而不是这个文件的全部
一般来说, 如果你想暂存一个文件的一部分, 你可这样做:
$ git add --patch filename.x
-p 简写。这会打开交互模式, 你将能够用 s 选项来分隔提交(commit); 然而, 如果这个文件是新的, 会没有这个选择, 添加一个新文件时, 这样做:
$ git add -N filename.x
然后, 你需要用 e 选项来手动选择需要添加的行,执行 git diff --cached 将会显示哪些行暂存了哪些行只是保存在本地了。
我想把在一个文件里的变化(changes)加到两个提交(commit)里
git add 会把整个文件加入到一个提交. git add -p 允许交互式的选择你想要提交的部分.
我想把暂存的内容变成未暂存,把未暂存的内容暂存起来
多数情况下,你应该将所有的内容变为未暂存,然后再选择你想要的内容进行commit。 但假定你就是想要这么做,这里你可以创建一个临时的commit来保存你已暂存的内容,然后暂存你的未暂存的内容并进行stash。然后reset最后一个commit将原本暂存的内容变为未暂存,最后stash pop回来。
$ git commit -m "WIP"
$ git add .
$ git stash
$ git reset HEAD^
$ git stash pop --index 0
注意1: 这里使用pop仅仅是因为想尽可能保持幂等。
注意2: 假如你不加上--index你会把暂存的文件标记为为存储.这个链接 解释得比较清楚。(不过是英文的,其大意是说,这是一个较为底层的问题,stash时会做2个commit,其中一个会记录index状态,staged的文件等东西,另一个记录worktree和其他的一些东西,如果你不在apply时加index,git会把两个一起销毁,所以staged里就空了)。
未暂存(Unstaged)的内容
我想把未暂存的内容移动到一个新分支
$ git checkout -b my-branch
我想把未暂存的内容移动到另一个已存在的分支
$ git stash
$ git checkout my-branch
$ git stash pop
我想丢弃本地未提交的变化(uncommitted changes)
如果你只是想重置源(origin)和你本地(local)之间的一些提交(commit),你可以:
# one commit
(my-branch)$ git reset --hard HEAD^
# two commits
(my-branch)$ git reset --hard HEAD^^
# four commits
(my-branch)$ git reset --hard HEAD~4
# or
(master)$ git checkout -f
重置某个特殊的文件, 你可以用文件名做为参数:
$ git reset filename
我想丢弃某些未暂存的内容
如果你想丢弃工作拷贝中的一部分内容,而不是全部。
签出(checkout)不需要的内容,保留需要的。
$ git checkout -p
# Answer y to all of the snippets you want to drop
另外一个方法是使用 stash, Stash所有要保留下的内容, 重置工作拷贝, 重新应用保留的部分。
$ git stash -p
# Select all of the snippets you want to save
$ git reset --hard
$ git stash pop
或者, stash 你不需要的部分, 然后stash drop。
$ git stash -p
# Select all of the snippets you don't want to save
$ git stash drop
分支(Branches)
我从错误的分支拉取了内容,或把内容拉取到了错误的分支
这是另外一种使用 git reflog 情况,找到在这次错误拉(pull) 之前HEAD的指向。
(master)$ git reflog
ab7555f HEAD@{0}: pull origin wrong-branch: Fast-forward
c5bc55a HEAD@{1}: checkout: checkout message goes here
重置分支到你所需的提交(desired commit):
$ git reset --hard c5bc55a
完成。
我想扔掉本地的提交(commit),以便我的分支与远程的保持一致
先确认你没有推(push)你的内容到远程。
git status 会显示你领先(ahead)源(origin)多少个提交:
(my-branch)$ git status
# On branch my-branch
# Your branch is ahead of 'origin/my-branch' by 2 commits.
# (use "git push" to publish your local commits)
#
一种方法是:
(master)$ git reset --hard origin/my-branch
我需要提交到一个新分支,但错误的提交到了master
在master下创建一个新分支,不切换到新分支,仍在master下:
(master)$ git branch my-branch
把master分支重置到前一个提交:
(master)$ git reset --hard HEAD^
HEAD^ 是 HEAD^1 的简写,你可以通过指定要设置的HEAD来进一步重置。
或者, 如果你不想使用 HEAD^, 找到你想重置到的提交(commit)的hash(git log 能够完成), 然后重置到这个hash。 使用git push 同步内容到远程。
例如, master分支想重置到的提交的hash为a13b85e:
(master)$ git reset --hard a13b85e
HEAD is now at a13b85e
签出(checkout)刚才新建的分支继续工作:
(master)$ git checkout my-branch
我想保留来自另外一个ref-ish的整个文件
假设你正在做一个原型方案(原文为working spike (see note)), 有成百的内容,每个都工作得很好。现在, 你提交到了一个分支,保存工作内容:
(solution)$ git add -A && git commit -m "Adding all changes from this spike into one big commit."
当你想要把它放到一个分支里 (可能是feature, 或者 develop), 你关心是保持整个文件的完整,你想要一个大的提交分隔成比较小。
假设你有:
- 分支
solution, 拥有原型方案, 领先develop分支。 - 分支
develop, 在这里你应用原型方案的一些内容。
我去可以通过把内容拿到你的分支里,来解决这个问题:
(develop)$ git checkout solution -- file1.txt
这会把这个文件内容从分支 solution 拿到分支 develop 里来:
# On branch develop
# Your branch is up-to-date with 'origin/develop'.
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: file1.txt
然后, 正常提交。
Note: Spike solutions are made to analyze or solve the problem. These solutions are used for estimation and discarded once everyone gets clear visualization of the problem. ~ Wikipedia.
我把几个提交(commit)提交到了同一个分支,而这些提交应该分布在不同的分支里
假设你有一个master分支, 执行git log, 你看到你做过两次提交:
(master)$ git log
commit e3851e817c451cc36f2e6f3049db528415e3c114
Author: Alex Lee <alexlee@example.com>
Date: Tue Jul 22 15:39:27 2014 -0400
Bug #21 - Added CSRF protection
commit 5ea51731d150f7ddc4a365437931cd8be3bf3131
Author: Alex Lee <alexlee@example.com>
Date: Tue Jul 22 15:39:12 2014 -0400
Bug #14 - Fixed spacing on title
commit a13b85e984171c6e2a1729bb061994525f626d14
Author: Aki Rose <akirose@example.com>
Date: Tue Jul 21 01:12:48 2014 -0400
First commit
让我们用提交hash(commit hash)标记bug (e3851e8 for #21, 5ea5173 for #14).
首先, 我们把master分支重置到正确的提交(a13b85e):
(master)$ git reset --hard a13b85e
HEAD is now at a13b85e
现在, 我们对 bug #21 创建一个新的分支:
(master)$ git checkout -b 21
(21)$
接着, 我们用 cherry-pick 把对bug #21的提交放入当前分支。 这意味着我们将应用(apply)这个提交(commit),仅仅这一个提交(commit),直接在HEAD上面。
(21)$ git cherry-pick e3851e8
这时候, 这里可能会产生冲突, 参见交互式 rebasing 章 冲突节 解决冲突.
再者, 我们为bug #14 创建一个新的分支, 也基于master分支
(21)$ git checkout master
(master)$ git checkout -b 14
(14)$
最后, 为 bug #14 执行 cherry-pick:
(14)$ git cherry-pick 5ea5173
我想删除上游(upstream)分支被删除了的本地分支
一旦你在github 上面合并(merge)了一个pull request, 你就可以删除你fork里被合并的分支。 如果你不准备继续在这个分支里工作, 删除这个分支的本地拷贝会更干净,使你不会陷入工作分支和一堆陈旧分支的混乱之中。
$ git fetch -p
我不小心删除了我的分支
如果你定期推送到远程, 多数情况下应该是安全的,但有些时候还是可能删除了还没有推到远程的分支。 让我们先创建一个分支和一个新的文件:
(master)$ git checkout -b my-branch
(my-branch)$ git branch
(my-branch)$ touch foo.txt
(my-branch)$ ls
README.md foo.txt
添加文件并做一次提交
(my-branch)$ git add .
(my-branch)$ git commit -m 'foo.txt added'
(my-branch)$ foo.txt added
1 files changed, 1 insertions(+)
create mode 100644 foo.txt
(my-branch)$ git log
commit 4e3cd85a670ced7cc17a2b5d8d3d809ac88d5012
Author: siemiatj <siemiatj@example.com>
Date: Wed Jul 30 00:34:10 2014 +0200
foo.txt added
commit 69204cdf0acbab201619d95ad8295928e7f411d5
Author: Kate Hudson <katehudson@example.com>
Date: Tue Jul 29 13:14:46 2014 -0400
Fixes #6: Force pushing after amending commits
现在我们切回到主(master)分支,‘不小心的’删除my-branch分支
(my-branch)$ git checkout master
Switched to branch 'master'
Your branch is up-to-date with 'origin/master'.
(master)$ git branch -D my-branch
Deleted branch my-branch (was 4e3cd85).
(master)$ echo oh noes, deleted my branch!
oh noes, deleted my branch!
在这时候你应该想起了reflog, 一个升级版的日志,它存储了仓库(repo)里面所有动作的历史。
(master)$ git reflog
69204cd HEAD@{0}: checkout: moving from my-branch to master
4e3cd85 HEAD@{1}: commit: foo.txt added
69204cd HEAD@{2}: checkout: moving from master to my-branch
正如你所见,我们有一个来自删除分支的提交hash(commit hash),接下来看看是否能恢复删除了的分支。
(master)$ git checkout -b my-branch-help
Switched to a new branch 'my-branch-help'
(my-branch-help)$ git reset --hard 4e3cd85
HEAD is now at 4e3cd85 foo.txt added
(my-branch-help)$ ls
README.md foo.txt
看! 我们把删除的文件找回来了。 Git的 reflog 在rebasing出错的时候也是同样有用的。
我想删除一个分支
删除一个远程分支:
(master)$ git push origin --delete my-branch
你也可以:
(master)$ git push origin :my-branch
删除一个本地分支:
(master)$ git branch -D my-branch
我想从别人正在工作的远程分支签出(checkout)一个分支
首先, 从远程拉取(fetch) 所有分支:
(master)$ git fetch --all
假设你想要从远程的daves分支签出到本地的daves
(master)$ git checkout --track origin/daves
Branch daves set up to track remote branch daves from origin.
Switched to a new branch 'daves'
(--track 是 git checkout -b [branch] [remotename]/[branch] 的简写)
这样就得到了一个daves分支的本地拷贝, 任何推过(pushed)的更新,远程都能看到.
Rebasing 和合并(Merging)
我想撤销rebase/merge
你可以合并(merge)或rebase了一个错误的分支, 或者完成不了一个进行中的rebase/merge。 Git 在进行危险操作的时候会把原始的HEAD保存在一个叫ORIG_HEAD的变量里, 所以要把分支恢复到rebase/merge前的状态是很容易的。
(my-branch)$ git reset --hard ORIG_HEAD
我已经rebase过, 但是我不想强推(force push)
不幸的是,如果你想把这些变化(changes)反应到远程分支上,你就必须得强推(force push)。 是因你快进(Fast forward)了提交,改变了Git历史, 远程分支不会接受变化(changes),除非强推(force push)。这就是许多人使用 merge 工作流, 而不是 rebasing 工作流的主要原因之一, 开发者的强推(force push)会使大的团队陷入麻烦。使用时需要注意,一种安全使用 rebase 的方法是,不要把你的变化(changes)反映到远程分支上, 而是按下面的做:
(master)$ git checkout my-branch
(my-branch)$ git rebase -i master
(my-branch)$ git checkout master
(master)$ git merge --ff-only my-branch
更多, 参见 this SO thread.
我需要组合(combine)几个提交(commit)
假设你的工作分支将会做对于 master 的pull-request。 一般情况下你不关心提交(commit)的时间戳,只想组合 所有 提交(commit) 到一个单独的里面, 然后重置(reset)重提交(recommit)。 确保主(master)分支是最新的和你的变化都已经提交了, 然后:
(my-branch)$ git reset --soft master
(my-branch)$ git commit -am "New awesome feature"
如果你想要更多的控制, 想要保留时间戳, 你需要做交互式rebase (interactive rebase):
(my-branch)$ git rebase -i master
如果没有相对的其它分支, 你将不得不相对自己的HEAD 进行 rebase。 例如:你想组合最近的两次提交(commit), 你将相对于HEAD~2 进行rebase, 组合最近3次提交(commit), 相对于HEAD~3, 等等。
(master)$ git rebase -i HEAD~2
在你执行了交互式 rebase的命令(interactive rebase command)后, 你将在你的编辑器里看到类似下面的内容:
pick a9c8a1d Some refactoring
pick 01b2fd8 New awesome feature
pick b729ad5 fixup
pick e3851e8 another fix
# Rebase 8074d12..b729ad5 onto 8074d12
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
所有以 # 开头的行都是注释, 不会影响 rebase.
然后,你可以用任何上面命令列表的命令替换 pick, 你也可以通过删除对应的行来删除一个提交(commit)。
例如, 如果你想 单独保留最旧(first)的提交(commit),组合所有剩下的到第二个里面, 你就应该编辑第二个提交(commit)后面的每个提交(commit) 前的单词为 f:
pick a9c8a1d Some refactoring
pick 01b2fd8 New awesome feature
f b729ad5 fixup
f e3851e8 another fix
如果你想组合这些提交(commit) 并重命名这个提交(commit), 你应该在第二个提交(commit)旁边添加一个r,或者更简单的用s 替代 f:
pick a9c8a1d Some refactoring
pick 01b2fd8 New awesome feature
s b729ad5 fixup
s e3851e8 another fix
你可以在接下来弹出的文本提示框里重命名提交(commit)。
Newer, awesomer features
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# rebase in progress; onto 8074d12
# You are currently editing a commit while rebasing branch 'master' on '8074d12'.
#
# Changes to be committed:
# modified: README.md
#
如果成功了, 你应该看到类似下面的内容:
(master)$ Successfully rebased and updated refs/heads/master.
安全合并(merging)策略
--no-commit 执行合并(merge)但不自动提交, 给用户在做提交前检查和修改的机会。 no-ff 会为特性分支(feature branch)的存在过留下证据, 保持项目历史一致。
(master)$ git merge --no-ff --no-commit my-branch
我需要将一个分支合并成一个提交(commit)
(master)$ git merge --squash my-branch
我只想组合(combine)未推的提交(unpushed commit)
有时候,在将数据推向上游之前,你有几个正在进行的工作提交(commit)。这时候不希望把已经推(push)过的组合进来,因为其他人可能已经有提交(commit)引用它们了。
(master)$ git rebase -i @{u}
这会产生一次交互式的rebase(interactive rebase), 只会列出没有推(push)的提交(commit), 在这个列表时进行reorder/fix/squash 都是安全的。
检查是否分支上的所有提交(commit)都合并(merge)过了
检查一个分支上的所有提交(commit)是否都已经合并(merge)到了其它分支, 你应该在这些分支的head(或任何 commits)之间做一次diff:
(master)$ git log --graph --left-right --cherry-pick --oneline HEAD...feature/120-on-scroll
这会告诉你在一个分支里有而另一个分支没有的所有提交(commit), 和分支之间不共享的提交(commit)的列表。 另一个做法可以是:
(master)$ git log master ^feature/120-on-scroll --no-merges
交互式rebase(interactive rebase)可能出现的问题
这个rebase 编辑屏幕出现’noop’
如果你看到的是这样:
noop
这意味着你rebase的分支和当前分支在同一个提交(commit)上, 或者 领先(ahead) 当前分支。 你可以尝试:
- 检查确保主(master)分支没有问题
- rebase
HEAD~2或者更早
有冲突的情况
如果你不能成功的完成rebase, 你可能必须要解决冲突。
首先执行 git status 找出哪些文件有冲突:
(my-branch)$ git status
On branch my-branch
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: README.md
在这个例子里面, README.md 有冲突。 打开这个文件找到类似下面的内容:
<<<<<<< HEAD
some code
=========
some code
>>>>>>> new-commit
你需要解决新提交的代码(示例里, 从中间==线到new-commit的地方)与HEAD 之间不一样的地方.
有时候这些合并非常复杂,你应该使用可视化的差异编辑器(visual diff editor):
(master*)$ git mergetool -t opendiff
在你解决完所有冲突和测试过后, git add 变化了的(changed)文件, 然后用git rebase --continue 继续rebase。
(my-branch)$ git add README.md
(my-branch)$ git rebase --continue
如果在解决完所有的冲突过后,得到了与提交前一样的结果, 可以执行git rebase --skip。
任何时候你想结束整个rebase 过程,回来rebase前的分支状态, 你可以做:
(my-branch)$ git rebase --abort
Stash
暂存所有改动
暂存你工作目录下的所有改动
$ git stash
你可以使用-u来排除一些文件
$ git stash -u
暂存指定文件
假设你只想暂存某一个文件
$ git stash push working-directory-path/filename.ext
假设你想暂存多个文件
$ git stash push working-directory-path/filename1.ext working-directory-path/filename2.ext
暂存时记录消息
这样你可以在list时看到它
$ git stash save <message>
或
$ git stash push -m <message>
使用某个指定暂存
首先你可以查看你的stash记录
$ git stash list
然后你可以apply某个stash
$ git stash apply "stash@{n}"
此处, ‘n’是stash在栈中的位置,最上层的stash会是0
除此之外,也可以使用时间标记(假如你能记得的话)。
$ git stash apply "stash@{2.hours.ago}"
暂存时保留未暂存的内容
你需要手动create一个stash commit, 然后使用git stash store。
$ git stash create
$ git stash store -m "commit-message" CREATED_SHA1
杂项(Miscellaneous Objects)
克隆所有子模块
$ git clone --recursive git://github.com/foo/bar.git
如果已经克隆了:
$ git submodule update --init --recursive
删除标签(tag)
$ git tag -d <tag_name>
$ git push <remote> :refs/tags/<tag_name>
恢复已删除标签(tag)
如果你想恢复一个已删除标签(tag), 可以按照下面的步骤: 首先, 需要找到无法访问的标签(unreachable tag):
$ git fsck --unreachable | grep tag
记下这个标签(tag)的hash,然后用Git的 update-ref:
$ git update-ref refs/tags/<tag_name> <hash>
这时你的标签(tag)应该已经恢复了。
已删除补丁(patch)
如果某人在 GitHub 上给你发了一个pull request, 但是然后他删除了他自己的原始 fork, 你将没法克隆他们的提交(commit)或使用 git am。在这种情况下, 最好手动的查看他们的提交(commit),并把它们拷贝到一个本地新分支,然后做提交。
做完提交后, 再修改作者,参见变更作者。 然后, 应用变化, 再发起一个新的pull request。
跟踪文件(Tracking Files)
我只想改变一个文件名字的大小写,而不修改内容
(master)$ git mv --force myfile MyFile
我想从Git删除一个文件,但保留该文件
(master)$ git rm --cached log.txt
配置(Configuration)
我想给一些Git命令添加别名(alias)
在 OS X 和 Linux 下, 你的 Git的配置文件储存在 ~/.gitconfig。我在[alias] 部分添加了一些快捷别名(和一些我容易拼写错误的),如下:
[alias]
a = add
amend = commit --amend
c = commit
ca = commit --amend
ci = commit -a
co = checkout
d = diff
dc = diff --changed
ds = diff --staged
f = fetch
loll = log --graph --decorate --pretty=oneline --abbrev-commit
m = merge
one = log --pretty=oneline
outstanding = rebase -i @{u}
s = status
unpushed = log @{u}
wc = whatchanged
wip = rebase -i @{u}
zap = fetch -p
我想缓存一个仓库(repository)的用户名和密码
你可能有一个仓库需要授权,这时你可以缓存用户名和密码,而不用每次推/拉(push/pull)的时候都输入,Credential helper能帮你。
$ git config --global credential.helper cache
# Set git to use the credential memory cache
$ git config --global credential.helper 'cache --timeout=3600'
# Set the cache to timeout after 1 hour (setting is in seconds)
我不知道我做错了些什么
你把事情搞砸了:你 重置(reset) 了一些东西, 或者你合并了错误的分支, 亦或你强推了后找不到你自己的提交(commit)了。有些时候, 你一直都做得很好, 但你想回到以前的某个状态。
这就是 git reflog 的目的, reflog 记录对分支顶端(the tip of a branch)的任何改变, 即使那个顶端没有被任何分支或标签引用。基本上, 每次HEAD的改变, 一条新的记录就会增加到reflog。遗憾的是,这只对本地分支起作用,且它只跟踪动作 (例如,不会跟踪一个没有被记录的文件的任何改变)。
(master)$ git reflog
0a2e358 HEAD@{0}: reset: moving to HEAD~2
0254ea7 HEAD@{1}: checkout: moving from 2.2 to master
c10f740 HEAD@{2}: checkout: moving from master to 2.2
上面的reflog展示了从master分支签出(checkout)到2.2 分支,然后再签回。 那里,还有一个硬重置(hard reset)到一个较旧的提交。最新的动作出现在最上面以 HEAD@{0}标识.
如果事实证明你不小心回移(move back)了提交(commit), reflog 会包含你不小心回移前master上指向的提交(0254ea7)。
$ git reset --hard 0254ea7
然后使用git reset就可以把master改回到之前的commit,这提供了一个在历史被意外更改情况下的安全网。
(摘自).
其它资源(Other Resources)
书(Books)
- Pro Git - Scott Chacon’s excellent git book
- Git Internals - Scott Chacon’s other excellent git book
教程(Tutorials)
- Learn Git branching 一个基于网页的交互式 branching/merging/rebasing 教程
- Getting solid at Git rebase vs. merge
- git-workflow - Aaron Meurer的怎么使用Git为开源仓库贡献
- GitHub as a workflow - 使用GitHub做为工作流的趣事, 尤其是空PRs
脚本和工具(Scripts and Tools)
- firstaidgit.io 一个可搜索的最常被问到的Git的问题
- git-extra-commands - 一堆有用的额外的Git脚本
- git-extras - GIT 工具集 – repo summary, repl, changelog population, author commit percentages and more
- git-fire - git-fire 是一个 Git 插件,用于帮助在紧急情况下添加所有当前文件, 做提交(committing), 和推(push)到一个新分支(阻止合并冲突)。
- git-tips - Git小提示
- git-town - 通用,高级Git工作流支持! http://www.git-town.com
GUI客户端(GUI Clients)
- GitKraken - 豪华的Git客户端 Windows, Mac & Linux
- git-cola - 另外一个Git客户端 Windows & OS X
- GitUp - 一个新的Git客户端,在处理Git的复杂性上有自己的特点
- gitx-dev - 图形化的Git客户端 OS X
- Source Tree - 免费的图形化Git客户端 Windows & OS X
- Tower - 图形化Git客户端 OS X(付费)����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-03-07-Git-Gitignore.md������������������������������������������������������������������0000664�0001750�0001750�00000002566�14127026255�016330� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: 使用 .gitignore 忽略 Git 仓库中的文件
subtitle: .gitignore 文件在Git中的使用
date: 2018-03-07
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
-
Git
-
使用
.gitignore文件忽略指定文件
.gitignore
在Git中,很多时候你只想将代码提交到仓库,而不是将当前文件目录下的文件全部提交到Git仓库中,例如在MacOS系统下面的.DS_Store文件,或者是Xocde的操作记录,又或者是pod库的中一大串的源代码。这种情况下使用.gitignore就能够在Git提交时自动忽略掉这些文件。
忽略的格式
#:此为注释 – 将被 Git 忽略*.a:忽略所有.a结尾的文件!lib.a: 不忽略lib.a文件/TODO:仅仅忽略项目根目录下的TODO文件,不包括subdir/TODObuild/: 忽略build/目录下的所有文件doc/*.txt: 会忽略doc/notes.txt但不包括doc/server/arch.txt
创建方法
从 github 上获取
github上整理了一些常用需要的项目中需要忽略的文件配置,根据需要进行获取
https://github.com/github/gitignore.git
IDEA中使用gitignore插件为项目创建.gitignore
- .ignore support plugin for IntelliJ IDEA������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-04-08-Java-Collection.md����������������������������������������������������������������0000664�0001750�0001750�00000005420�14127043406�016621� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: Java集合体系
subtitle: Java集合体系分类与关系
date: 2018-04-08
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
-
Java
-
集合
单列集合-collection
有序集合List
ArrayList:
- ArrayList是一个动态数组,也是我们最常用的集合。
- 它允许任何符合规则的元素插入甚至包括null。
- 每一个ArrayList都有一个初始容量(10),该容量代表了数组的大小。
- 随着容器中的元素不断增加,容器的大小也会随着增加。在每次向容器中增加元素的同时都会进行容量检查,当快溢出时,就会进行扩容操作。
- 所以如果我们明确所插入元素的多少,最好指定一个初始容量值,避免过多的进行扩容操作而浪费时间、效率。
LinkedList:
- 是一个双链表,在添加和删除元素时具比ArrayList更好的性能;
- 它除了有ArrayList的基本操作方法外还额外提供了get,remove,insert方法在LinkedList的首部或尾部。
- 由于实现的方式不同,LinkedList不能随机访问,它所有的操作都是要按照双重链表的需要执行。
- 在列表中索引的操作将从开头或结尾遍历列表(从靠近指定索引的一端)。
- 这样做的好处就是可以通过较低的代价在List中进行插入和删除操作。
Vector:
- 相当于是一个线程安全的ArrayList,效率比较底下,如果对安全性有要求的话可以考虑使用Vector
无序集合set
HashSet:
- 无序不重复,线程不安全,放入的元素可以为null;
- HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等
LinkedHashSet:
- 按放入顺序有序不重复
TreeSet:
- 按红黑树方式有序不重复;
- TreeSet 是二差树实现的,Treeset中的数据是自动排好序的,不允许放入null值。
多列集合-map
HashMap:
- 线程不安全;
- 可以接受为null的键值(key)和值(value);
- 不能保证随着时间的推移Map中的元素次序是不变的;
- HashMap可以通过下面的语句进行同步: Map m = Collections.synchronizeMap(hashMap);
HashTable:
- 线程安全;
- 不接受null值;
- Java5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好;
- 如果你不需要线程安全,那么使用HashMap,如果需要线程安全,那么使用ConcurrentHashMap。HashTable已经被淘汰了,不要在新的代码中再使用它。
- 为什么HashTable已经淘汰了,还要优化它?因为有老的代码还在使用它,所以优化了它之后,这些老的代码也能获得性能提升。������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-07-19-Spring-事务(Transaction).md�����������������������������������������������������0000664�0001750�0001750�00000007143�13770775644�021642� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: Spring事务(Transaction)
subtitle: 七种事务传播行为及五种隔离级别
date: 2018-07-19
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
- Spring
-
Transaction
1. 首先,说说什么事务(Transaction)
- 事务,就是一组操作数据库的动作集合。事务是现代数据库理论中的核心概念之一。
- 如果一组处理步骤或者全部发生或者一步也不执行,我们称该组处理步骤为一个事务。
- 当所有的步骤像一个操作一样被完整地执行,我们称该事务被提交。
- 由于其中的一部分或多步执行失败,导致没有步骤被提交,则事务必须回滚到最初的系统状态。
2. spring七个事务传播属性:
- PROPAGATION_REQUIRED
- 支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
- PROPAGATION_SUPPORTS
- 支持当前事务,如果当前没有事务,就以非事务方式执行。
- PROPAGATION_MANDATORY
- 支持当前事务,如果当前没有事务,就抛出异常。
- PROPAGATION_REQUIRES_NEW
- 新建事务,如果当前存在事务,把当前事务挂起。
- PROPAGATION_NOT_SUPPORTED
- 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- PROPAGATION_NEVER
- 以非事务方式执行,如果当前存在事务,则抛出异常。
- PROPAGATION_NESTED
- 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作。 - 备注:常用的两个事务传播属性是1和4,即PROPAGATION_REQUIRED,PROPAGATION_REQUIRES_NEW
3. 五个隔离级别:
- ISOLATION_DEFAULT
- 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别.
- 另外四个与JDBC的隔离级别相对应;
- ISOLATION_READ_UNCOMMITTED
- 这是事务最低的隔离级别,它充许别外一个事务可以看到这个事务未提交的数据。
- 这种隔离级别会产生脏读,不可重复读和幻像读。
- ISOLATION_READ_COMMITTED
- 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据。
- 这种事务隔离级别可以避免脏读出现,但是可能会出现不可重复读和幻像读。
- ISOLATION_REPEATABLE_READ
- 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。
- 它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。
- ISOLATION_SERIALIZABLE
- 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。
- 除了防止脏读,不可重复读外,还避免了幻像读。
关键词:
- 幻读:事务1读取记录时事务2增加了记录并提交,事务1再次读取时可以看到事务2新增的记录;
- 不可重复读取:事务1读取记录时,事务2更新了记录并提交,事务1再次读取时可以看到事务2修改后的记录;
- 脏读:事务1更新了记录,但没有提交,事务2读取了更新后的行,然后事务T1回滚,现在T2读取无效。
脏读:
- 指一个事务读取了一个未提交事务的数据
不可重复读:
- 在一个事务内读取表中的某一行数据,多次读取结果不同.一个事务读取到了另一个事务提交后的数据.
虚读(幻读):
- 在一个事务内读取了别的事务插入的数据,导致前后读取不一致(insert)�����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-07-21-Spring-核心模块解析.md������������������������������������������������������0000664�0001750�0001750�00000002426�13763566257�023575� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: Spring的核心模块解析
subtitle: 拆解spring框架的功能模块
date: 2018-07-21
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
-
Spring
-
Spring图中的这些模块,都至少由一个以上的jar包组成。
1、Core Container - 核心容器
spring-core:Spring中的核心工具类包。
spring-beans:Spring中定义bean的组件。
spring-context:Spring的运行容器。
spring-context-support:Spring容器的扩展支持。
spring-expression:Spring的表达式语言支持。
2、AOP - 面向切面编程
spring-aop:基于代理的AOP支持。
spring-aspects:集成Aspects的AOP支持。
3、WEB(MVC)
spring-web:提供web的基础功能。
spring-webmvc:提供springmvc的功能。
spring-websocket:提供web socket支持。
spring-webmvc-portlet:提供Portlet环境的支持。
4、Data Access/Integration - 数据访问/集成
spring-jdbc:提供对jdbc连接的封装功能。
spring-tx:提供对事务的支持。
spring-orm:提供对象-关系映射支持。
spring-oxm:提供对象-XML映射支持。
spring-jms:提供消息队列的支持。
5、Test - 测试
spring-test:提供对测试功能的支持。������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-07-23-Spring-SpringMVC9大组件概览.md�����������������������������������������������0000664�0001750�0001750�00000012267�13763566257�024362� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: SpringMVC9大组件概览 subtitle: 学习SpringMVC的架构 date: 2018-07-23 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Spring - SpringMVC —
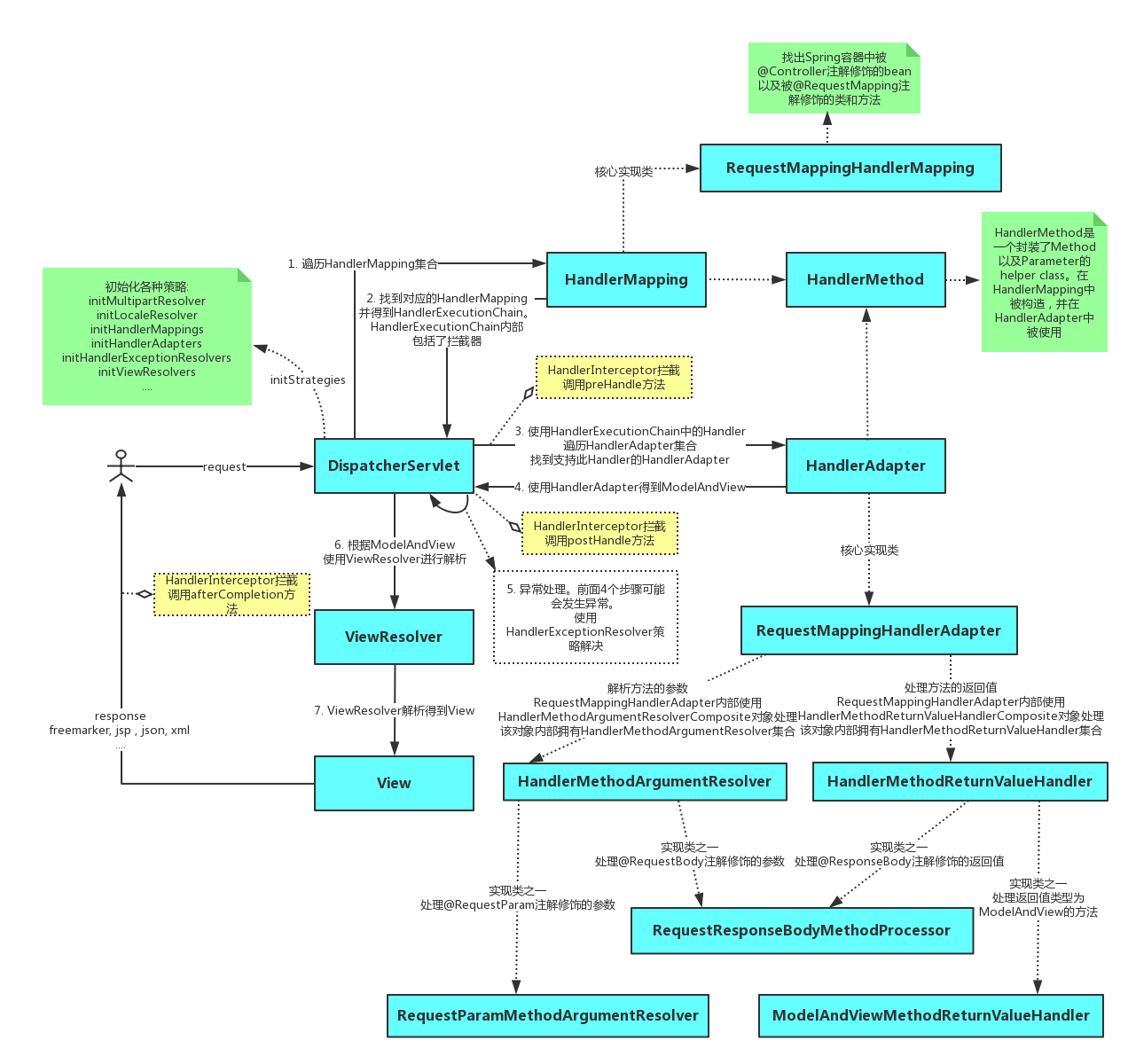
SpringMVC中的Servlet一共有三个层次,分别是HttpServletBean、FrameworkServlet和 DispatcherServlet。
HttpServletBean直接继承自java的HttpServlet,其作用是将Servlet中配置的参数设置到相应的属性;
FrameworkServlet初始化了WebApplicationContext,DispatcherServlet初始化了自身的9个组件。
在学习9个组件之前,我们需要先了解Handler的概念,也就是处理器。它直接应对着MVC中的C也就是Controller层,它的具体表现形式有很多,可以是类,也可以是方法。在Controller层中@RequestMapping标注的所有方法都可以看成是一个Handler,只要可以实际处理请求就可以是Handler。
Handler的概念清楚了,下面开始对9个组件一一介绍。
【1. HandlerMapping】处理器映射器
是用来查找Handler的。在SpringMVC中会有很多请求,每个请求都需要一个Handler处理,具体接收到一个请求之后使用哪个Handler进行处理呢?这就是HandlerMapping需要做的事。
【2. HandlerAdapter】处理器适配器
从名字上看,它就是一个适配器。因为SpringMVC中的Handler可以是任意的形式,只要能处理请求就ok,但是Servlet需要的处理方法的结构却是固定的,都是以request和response为参数的方法。如何让固定的Servlet处理方法调用灵活的Handler来进行处理呢?这就是HandlerAdapter要做的事情。
小结: Handler是用来干活的工具;HandlerMapping用于根据需要干的活找到相应的工具;HandlerAdapter是使用工具干活的人。
【3. HandlerExceptionResolver】
其它组件都是用来干活的。在干活的过程中难免会出现问题,出问题后怎么办呢?这就需要有一个专门的角色对异常情况进行处理,在SpringMVC中就是HandlerExceptionResolver。具体来说,此组件的作用是根据异常设置ModelAndView,之后再交给render方法进行渲染。
【4. ViewResolver】视图解析器
ViewResolver用来将String类型的视图名和Locale解析为View类型的视图。View是用来渲染页面的,也就是将程序返回的参数填入模板里,生成html(也可能是其它类型)文件。这里就有两个关键问题:使用哪个模板?用什么技术(规则)填入参数?这其实是ViewResolver主要要做的工作,ViewResolver需要找到渲染所用的模板和所用的技术(也就是视图的类型)进行渲染,具体的渲染过程则交由不同的视图自己完成。
【5. RequestToViewNameTranslator】
ViewName是根据ViewName查找View,但有的Handler处理完后并没有设置View也没有设置ViewName,这时就需要从request获取ViewName了,如何从request中获取ViewName就是RequestToViewNameTranslator要做的事情了。RequestToViewNameTranslator在Spring MVC容器里只可以配置一个,所以所有request到ViewName的转换规则都要在一个Translator里面全部实现。
【6. LocaleResolver】
解析视图需要两个参数:一是视图名,另一个是Locale。视图名是处理器返回的,Locale是从哪里来的?这就是LocaleResolver要做的事情。LocaleResolver用于从request解析出Locale,Locale就是zh-cn之类,表示一个区域,有了这个就可以对不同区域的用户显示不同的结果。SpringMVC主要有两个地方用到了Locale:一是ViewResolver视图解析的时候;二是用到国际化资源或者主题的时候。
【7. ThemeResolver】
用于解析主题。SpringMVC中一个主题对应一个properties文件,里面存放着跟当前主题相关的所有资源、如图片、css样式等。SpringMVC的主题也支持国际化,同一个主题不同区域也可以显示不同的风格。SpringMVC中跟主题相关的类有 ThemeResolver、ThemeSource和Theme。主题是通过一系列资源来具体体现的,要得到一个主题的资源,首先要得到资源的名称,这是ThemeResolver的工作。然后通过主题名称找到对应的主题(可以理解为一个配置)文件,这是ThemeSource的工作。最后从主题中获取资源就可以了。
【8. MultipartResolver】
用于处理上传请求。处理方法是将普通的request包装成MultipartHttpServletRequest,后者可以直接调用getFile方法获取File,如果上传多个文件,还可以调用getFileMap得到FileName->File结构的Map。此组件中一共有三个方法,作用分别是判断是不是上传请求,将request包装成MultipartHttpServletRequest、处理完后清理上传过程中产生的临时资源。
【9. FlashMapManager】
用来管理FlashMap的,FlashMap主要用在redirect中传递参数。
【总结】
至此,SpringMVC中的9大组件也就简单地概述了一遍。通过对此9大组件的宏观认识,对分析SpringMVC的设计、原理与实现都会有很大的帮助作用。 �����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-07-25-Spring-SpringMVC的拦截器和过滤器.md���������������������������������������0000664�0001750�0001750�00000022222�14127043405�027305� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: SpringMVC的拦截器和过滤器 subtitle: SpringMVC的拦截器(Interceptor)和过滤器(Filter)的区别与联系 date: 2018-07-25 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Spring - SpringMVC —
一 简介
(1)过滤器:
依赖于servlet容器。在实现上基于函数回调,可以对几乎所有请求进行过滤,但是缺点是一个过滤器实例只能在容器初始化时调用一次。使用过滤器的目的是用来做一些过滤操作,获取我们想要获取的数据,比如:在过滤器中修改字符编码;在过滤器中修改HttpServletRequest的一些参数,包括:过滤低俗文字、危险字符等
继承HttpServletRequestWrapper以实现在Filter中修改HttpServletRequest的参数
在SpringMVC中使用过滤器(Filter)过滤容易引发XSS的危险字符
(2)拦截器:
依赖于web框架,在SpringMVC中就是依赖于SpringMVC框架。在实现上基于Java的反射机制,属于面向切面编程(AOP) 的一种运用。由于拦截器是基于web框架的调用,因此可以使用Spring的依赖注入(DI) 进行一些业务操作,同时一个拦截器实例在一个controller生命周期之内可以多次调用。但是缺点是只能对controller请求进行拦截,对其他的一些比如直接访问静态资源的请求则没办法进行拦截处理
在SpringMVC中使用拦截器(interceptor)拦截CSRF攻击(修)
SpringMVC中使用Interceptor+cookie实现在一定天数之内自动登录
二 多个过滤器与拦截器的代码执行顺序
如果在一个项目中仅仅只有一个拦截器或者过滤器,那么我相信相对来说理解起来是比较容易的。但是我们是否思考过:如果一个项目中有多个拦截器或者过滤器,那么它们的执行顺序应该是什么样的?或者再复杂点,一个项目中既有多个拦截器,又有多个过滤器,这时它们的执行顺序又是什么样的呢?
下面我将用简单的代码来测试说明:
- 先定义两个过滤器:
- 过滤器1: ```java import java.io.IOException;
import javax.servlet.FilterChain; import javax.servlet.ServletException; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse;
import org.springframework.web.filter.OncePerRequestFilter;
public class TestFilter1 extends OncePerRequestFilter { protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException { //在DispatcherServlet之前执行 system.out.println(“############TestFilter1 doFilterInternal executed############”); filterChain.doFilter(request, response); //在视图页面返回给客户端之前执行,但是执行顺序在Interceptor之后 System.out.println(“############TestFilter1 doFilter after############”); // try { // Thread.sleep(10000); // } catch (InterruptedException e) { // e.printStackTrace(); // } } }
2. 过滤器2: ```java import java.io.IOException; import javax.servlet.FilterChain; import javax.servlet.ServletException; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import org.springframework.web.filter.OncePerRequestFilter; public class TestFilter2 extends OncePerRequestFilter { protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException { System.out.println("############TestFilter2 doFilterInternal executed############"); filterChain.doFilter(request, response); System.out.println("############TestFilter2 doFilter after############"); } }- 在web.xml中注册这两个过滤器:
<!-- 自定义过滤器:testFilter1 --> <filter> <filter-name>testFilter1</filter-name> <filter-class>cn.zifangsky.filter.TestFilter1</filter-class> </filter> <filter-mapping> <filter-name>testFilter1</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <!-- 自定义过滤器:testFilter2 --> <filter> <filter-name>testFilter2</filter-name> <filter-class>cn.zifangsky.filter.TestFilter2</filter-class> </filter> <filter-mapping> <filter-name>testFilter2</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
- 再定义两个拦截器:
- 拦截器1,基本拦截器: ```java import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse;
import org.springframework.web.servlet.HandlerInterceptor; import org.springframework.web.servlet.ModelAndView;
public class BaseInterceptor implements HandlerInterceptor{
/** 在DispatcherServlet之前执行 / public boolean preHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2) throws Exception { System.out.println(“****BaseInterceptor preHandle executed***”); return true; } /** 在controller执行之后的DispatcherServlet之后执行 / public void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) throws Exception { System.out.println(“****BaseInterceptor postHandle executed***”); } /** 在页面渲染完成返回给客户端之前执行 / public void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) throws Exception { System.out.println(“****BaseInterceptor afterCompletion executed***”);// Thread.sleep(10000); } }
2. 指定controller请求的拦截器: ```java import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import org.springframework.web.servlet.HandlerInterceptor; import org.springframework.web.servlet.ModelAndView; public class TestInterceptor implements HandlerInterceptor { public boolean preHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2) throws Exception { System.out.println("************TestInterceptor preHandle executed**********"); return true; } public void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) throws Exception { System.out.println("************TestInterceptor postHandle executed**********"); } public void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) throws Exception { System.out.println("************TestInterceptor afterCompletion executed**********"); } }- 在SpringMVC的配置文件中注册这两个拦截器:
<!-- 拦截器 --> <mvc:interceptors> <!-- 对所有请求都拦截,公共拦截器可以有多个 --> <bean name="baseInterceptor" class="cn.zifangsky.interceptor.BaseInterceptor" /> <!-- <bean name="testInterceptor" class="cn.zifangsky.interceptor.TestInterceptor" /> --> <mvc:interceptor> <!-- 对/test.html进行拦截 --> <mvc:mapping path="/test.html"/> <!-- 特定请求的拦截器只能有一个 --> <bean class="cn.zifangsky.interceptor.TestInterceptor" /> </mvc:interceptor> </mvc:interceptors>
- 定义一个测试使用的controller: ```java import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.servlet.ModelAndView;
@Controller public class TestController {
@RequestMapping("/test.html")
public ModelAndView handleRequest(){
System.out.println("---------TestController executed--------");
return new ModelAndView("test");
} } ``` 4. 视图页面test.jsp: ```xml <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <% String path = request.getContextPath(); String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/"; %>
5. 测试效果:
- 说明了过滤器的运行是依赖于servlet容器的,跟springmvc等框架并没有关系。并且,多个过滤器的执行顺序跟xml文件中定义的先后关系有关
- 对于过个拦截器它们之间的执行顺序跟在SpringMVC的配置文件中定义的先后顺序有关
������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-07-27-Spring-注解与配置.md���������������������������������������������������������0000664�0001750�0001750�00000040152�13763566257�022570� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������---
layout: post
title: Spring注解与配置
subtitle: 注解、配置、容器、bean
date: 2018-07-27
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
- Spring
---
### 程序耦合的问题
```java
/**
* 程序的耦合
* 耦合:程序间的依赖关系
* 包括:
* 类之间的依赖
* 方法间的依赖
* 解耦:
* 降低程序间的依赖关系
* 实际开发中:
* 应该做到:编译期不依赖,运行时才依赖。
* 解耦的思路:
* 第一步:使用反射来创建对象,而避免使用new关键字。
* 第二步:通过读取配置文件来获取要创建的对象全限定类名
*
*/
spring的Ioc核心容器管理对象
/**
* 获取spring的Ioc核心容器,并根据id获取对象
*
* ApplicationContext的三个常用实现类:
* ClassPathXmlApplicationContext:它可以加载类路径下的配置文件,要求配置文件必须在类路径下。不在的话,加载不了。(更常用)
* FileSystemXmlApplicationContext:它可以加载磁盘任意路径下的配置文件(必须有访问权限)
*
* AnnotationConfigApplicationContext:它是用于读取注解创建容器的,是明天的内容。
*
* 核心容器的两个接口引发出的问题:
* ApplicationContext: 单例对象适用 采用此接口
* 它在构建核心容器时,创建对象采取的策略是采用立即加载的方式。也就是说,只要一读取完配置文件马上就创建配置文件中配置的对象。
*
* BeanFactory: 多例对象使用
* 它在构建核心容器时,创建对象采取的策略是采用延迟加载的方式。也就是说,什么时候根据id获取对象了,什么时候才真正的创建对象。
*/
关于bean标签的知识点
<!--把对象的创建交给spring来管理-->
<!--
spring对bean的管理细节:
1.创建bean的三种方式
2.bean对象的作用范围
3.bean对象的生命周期
-->
<!--创建Bean的三种方式 -->
<!-- 第一种方式:使用默认构造函数创建。
在spring的配置文件中使用bean标签,配以id和class属性之后,且没有其他属性和标签时。
采用的就是默认构造函数创建bean对象,此时如果类中没有默认构造函数,则对象无法创建。
-->
<bean id="accountService" class="cn.flyingd.service.impl.AccountServiceImpl"></bean>
<!-- 第二种方式: 使用普通工厂中的方法创建对象(使用某个类中的方法创建对象,并存入spring容器)-->
<bean id="instanceFactory" class="cn.flyingd.factory.InstanceFactory"></bean>
<bean id="accountService" factory-bean="instanceFactory" factory-method="getAccountService"></bean>
<!-- 第三种方式:使用工厂中的静态方法创建对象(使用某个类中的静态方法创建对象,并存入spring容器)-->
<bean id="accountService" class="cn.flyingd.factory.StaticFactory" factory-method="getAccountService"></bean>
<!-- bean的作用范围调整
bean标签的scope属性:
作用:用于指定bean的作用范围
取值: 常用的就是单例的和多例的
singleton:单例的(默认值)
prototype:多例的
request:作用于web应用的请求范围
session:作用于web应用的会话范围
global-session:作用于集群环境的会话范围(全局会话范围),当不是集群环境时,它就是session
-->
<bean id="accountService" class="cn.flyingd.service.impl.AccountServiceImpl" scope="prototype"></bean>
<!-- bean对象的生命周期
单例对象
出生:当容器创建时对象出生
活着:只要容器还在,对象一直活着
死亡:容器销毁,对象消亡
总结:单例对象的生命周期和容器相同
多例对象
出生:当我们使用对象时spring框架为我们创建
活着:对象只要是在使用过程中就一直活着。
死亡:当对象长时间不用,且没有别的对象引用时,由Java的垃圾回收器回收
-->
DI(依赖注入)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- spring中的依赖注入
依赖注入:
Dependency Injection
IOC的作用:
降低程序间的耦合(依赖关系)
依赖关系的管理:
以后都交给spring来维护
在当前类需要用到其他类的对象,由spring为我们提供,我们只需要在配置文件中说明
依赖关系的维护:
就称之为依赖注入。
依赖注入:
能注入的数据:有三类
基本类型和String
其他bean类型(在配置文件中或者注解配置过的bean)
复杂类型/集合类型
注入的方式:有三种
第一种:使用构造函数提供
第二种:使用set方法提供
第三种:使用注解提供(明天的内容)
-->
<!--构造函数注入:
使用的标签:constructor-arg
标签出现的位置:bean标签的内部
标签中的属性
type:用于指定要注入的数据的数据类型,该数据类型也是构造函数中某个或某些参数的类型
index:用于指定要注入的数据给构造函数中指定索引位置的参数赋值。索引的位置是从0开始
name:用于指定给构造函数中指定名称的参数赋值 常用的
=============以上三个用于指定给构造函数中哪个参数赋值===============================
value:用于提供基本类型和String类型的数据
ref:用于指定其他的bean类型数据。它指的就是在spring的Ioc核心容器中出现过的bean对象
优势:
在获取bean对象时,注入数据是必须的操作,否则对象无法创建成功。
弊端:
改变了bean对象的实例化方式,使我们在创建对象时,如果用不到这些数据,也必须提供。
-->
<bean id="accountService" class="cn.flyingd.service.impl.AccountServiceImpl">
<constructor-arg name="name" value="泰斯特"></constructor-arg>
<constructor-arg name="age" value="18"></constructor-arg>
<constructor-arg name="birthday" ref="now"></constructor-arg>
</bean>
<!-- 配置一个日期对象 -->
<bean id="now" class="java.util.Date"></bean>
<!-- set方法注入 更常用的方式
涉及的标签:property
出现的位置:bean标签的内部
标签的属性
name:用于指定注入时所调用的set方法名称
value:用于提供基本类型和String类型的数据
ref:用于指定其他的bean类型数据。它指的就是在spring的Ioc核心容器中出现过的bean对象
优势:
创建对象时没有明确的限制,可以直接使用默认构造函数
弊端:
如果有某个成员必须有值,则获取对象是有可能set方法没有执行。
-->
<bean id="accountService2" class="cn.flyingd.service.impl.AccountServiceImpl2">
<property name="name" value="TEST" ></property>
<property name="age" value="21"></property>
<property name="birthday" ref="now"></property>
</bean>
<!-- 复杂类型的注入/集合类型的注入
用于给List结构集合注入的标签:
list array set
用于个Map结构集合注入的标签:
map props
结构相同,标签可以互换
-->
<bean id="accountService3" class="cn.flyingd.service.impl.AccountServiceImpl3">
<property name="myStrs">
<set>
<value>AAA</value>
<value>BBB</value>
<value>CCC</value>
</set>
</property>
<property name="myList">
<array>
<value>AAA</value>
<value>BBB</value>
<value>CCC</value>
</array>
</property>
<property name="mySet">
<list>
<value>AAA</value>
<value>BBB</value>
<value>CCC</value>
</list>
</property>
<property name="myMap">
<props>
<prop key="testC">ccc</prop>
<prop key="testD">ddd</prop>
</props>
</property>
<property name="myProps">
<map>
<entry key="testA" value="aaa"></entry>
<entry key="testB">
<value>BBB</value>
</entry>
</map>
</property>
</bean>
</beans>
注解IOC配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<!--告知spring在创建容器时要扫描的包,配置所需要的标签不是在beans的约束中,而是一个名称为
context名称空间和约束中-->
<context:component-scan base-package="cn.flyingd"></context:component-scan>
</beans>
注解知识点汇总
/**
* 账户的业务层实现类
*
* 曾经XML的配置:
* <bean id="accountService" class="cn.flyingd.service.impl.AccountServiceImpl" scope="" init-method="" destroy-method="">
* <property name="" value="" | ref=""></property>
* </bean>
*
* 用于创建对象的
* 他们的作用就和在XML配置文件中编写一个<bean>标签实现的功能是一样的
* Component:
* 作用:用于把当前类对象存入spring容器中
* 属性:
* value:用于指定bean的id。当我们不写时,它的默认值是当前类名,且首字母改小写。
* Controller:一般用在表现层
* Service:一般用在业务层
* Repository:一般用在持久层
* 以上三个注解他们的作用和属性与Component是一模一样。
* 他们三个是spring框架为我们提供明确的三层使用的注解,使我们的三层对象更加清晰
*
*
* 用于注入数据的
* 他们的作用就和在xml配置文件中的bean标签中写一个<property>标签的作用是一样的
* Autowired:
* 作用:自动按照类型注入。只要容器中有唯一的一个bean对象类型和要注入的变量类型匹配,就可以注入成功
* 如果ioc容器中没有任何bean的类型和要注入的变量类型匹配,则报错。
* 如果Ioc容器中有多个类型匹配时:
* 出现位置:
* 可以是变量上,也可以是方法上
* 细节:
* 在使用注解注入时,set方法就不是必须的了。
* Qualifier:
* 作用:在按照类中注入的基础之上再按照名称注入。它在给类成员注入时不能单独使用。但是在给方法参数注入时可以(稍后我们讲)
* 属性:
* value:用于指定注入bean的id。
* Resource
* 作用:直接按照bean的id注入。它可以独立使用
* 属性:
* name:用于指定bean的id。
* 以上三个注入都只能注入其他bean类型的数据,而基本类型和String类型无法使用上述注解实现。
* 另外,集合类型的注入只能通过XML来实现。
*
* Value
* 作用:用于注入基本类型和String类型的数据
* 属性:
* value:用于指定数据的值。它可以使用spring中SpEL(也就是spring的el表达式)
* SpEL的写法:${表达式}
*
* 用于改变作用范围的
* 他们的作用就和在bean标签中使用scope属性实现的功能是一样的
* Scope
* 作用:用于指定bean的作用范围
* 属性:
* value:指定范围的取值。常用取值:singleton prototype
*
* 和生命周期相关 了解
* 他们的作用就和在bean标签中使用init-method和destroy-methode的作用是一样的
* PreDestroy
* 作用:用于指定销毁方法
* PostConstruct
* 作用:用于指定初始化方法
*/
spring自定义配置类
/**
* 该类是一个配置类,它的作用和bean.xml是一样的
* spring中的新注解
* Configuration
* 作用:指定当前类是一个配置类
* 细节:当配置类作为AnnotationConfigApplicationContext对象创建的参数时,该注解可以不写。
* ComponentScan
* 作用:用于通过注解指定spring在创建容器时要扫描的包
* 属性:
* value:它和basePackages的作用是一样的,都是用于指定创建容器时要扫描的包。
* 我们使用此注解就等同于在xml中配置了:
* <context:component-scan base-package="cn.flyingd"></context:component-scan>
* Bean
* 作用:用于把当前方法的返回值作为bean对象存入spring的ioc容器中
* 属性:
* name:用于指定bean的id。当不写时,默认值是当前方法的名称
* 细节:
* 当我们使用注解配置方法时,如果方法有参数,spring框架会去容器中查找有没有可用的bean对象。
* 查找的方式和Autowired注解的作用是一样的
* Import
* 作用:用于导入其他的配置类
* 属性:
* value:用于指定其他配置类的字节码。
* 当我们使用Import的注解之后,有Import注解的类就父配置类,而导入的都是子配置类
* PropertySource
* 作用:用于指定properties文件的位置
* 属性:
* value:指定文件的名称和路径。
* 关键字:classpath,表示类路径下
*/
//@Configuration
@ComponentScan("cn.flyingd")
@Import(JdbcConfig.class)
@PropertySource("classpath:jdbcConfig.properties")
public class SpringConfiguration {
}
Spring整合junit的配置
/**
* 使用Junit单元测试:测试我们的配置
* Spring整合junit的配置
* 1、导入spring整合junit的jar(坐标)
* 2、使用Junit提供的一个注解把原有的main方法替换了,替换成spring提供的
* @Runwith
* 3、告知spring的运行器,spring和ioc创建是基于xml还是注解的,并且说明位置
* @ContextConfiguration
* locations:指定xml文件的位置,加上classpath关键字,表示在类路径下
* classes:指定注解类所在地位置
*
* 当我们使用spring 5.x版本的时候,要求junit的jar必须是4.12及以上
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = SpringConfiguration.class)
public class AccountServiceTest {
@Autowired
private IAccountService as = null;
@Test
public void testFindAll() {
//3.执行方法
List<Account> accounts = as.findAllAccount();
for(Account account : accounts){
System.out.println(account);
}
}
}
_posts/2018-08-02-Java-MySQL的相关配置.md������������������������������������������������������0000664�0001750�0001750�00000022551�14131047130�022737� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: Java实现MySQL的相关配置 subtitle: MySQL date: 2018-08-02 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Java - MySQL —
- DML(data manipulation language): 它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的数据进行操作的语言
- DDL(data definition language): DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用
- DCL(Data Control Language): 是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。在默认状态下,只有sysadmin,dbcreator,db_owner或db_securityadmin等人员才有权力执行DCL
Mysql常用命令
- mysql 初始化时修改密码
alert user user() identified by "密码";SqlMapConfig.xml
```xml <?xml version=”1.0” encoding=”UTF-8”?> <!DOCTYPE configuration PUBLIC “-//mybatis.org//DTD Config 3.0//EN” “http://mybatis.org/dtd/mybatis-3-config.dtd”>
### jdbcConfig.properties
```properties
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/eesy_mybatis
jdbc.username=root
jdbc.password=1234
映射文件XxxDao.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxx.dao.IUserDao">
<!-- 查询所有 -->
<select id="findAll" resultType="com.xxx.domain.User">
select * from user;
</select>
<!-- 保存用户 -->
<insert id="saveUser" parameterType="com.xxx.domain.User">
<!-- 配置插入操作后,获取插入数据的id -->
<selectKey keyProperty="id" keyColumn="id" resultType="int" order="AFTER">
select last_insert_id();
</selectKey>
insert into user(username,address,sex,birthday)values(#{username},#{address},#{sex},#{birthday});
</insert>
<!-- 更新用户 -->
<update id="updateUser" parameterType="com.xxx.domain.User">
update user set username=#{username},address=#{address},sex=#{sex},birthday=#{birthday} where id=#{id}
</update>
<!-- 删除用户-->
<delete id="deleteUser" parameterType="java.lang.Integer">
delete from user where id = #{uid}
</delete>
<!-- 根据id查询用户 -->
<select id="findById" parameterType="INT" resultType="com.xxx.domain.User">
select * from user where id = #{uid}
</select>
<!-- 根据名称模糊查询 -->
<select id="findByName" parameterType="string" resultType="com.xxx.domain.User">
select * from user where username like #{name}
</select>
<!-- 获取用户的总记录条数 -->
<select id="findTotal" resultType="int">
select count(id) from user;
</select>
</mapper>
mybatis入门案例
- mybatis-config.xml ```xml
<?xml version=”1.0” encoding=”UTF-8”?> <!DOCTYPE configuration PUBLIC “-//mybatis.org//DTD Config 3.0//EN” “http://mybatis.org/dtd/mybatis-3-config.dtd”>
- xxMapper.xml
```xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
public class MybatisTest {
/**
* 入门案例
* @param args
*/
public static void main(String[] args)throws Exception {
//1.读取配置文件
InputStream in = Resources.getResourceAsStream("SqlMapConfig.xml");
//2.创建SqlSessionFactory工厂
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(in);
//3.使用工厂生产SqlSession对象
SqlSession session = factory.openSession();
//4.使用SqlSession创建Dao接口的代理对象
IUserDao userDao = session.getMapper(IUserDao.class);
//5.使用代理对象执行方法
List<User> users = userDao.findAll();
for(User user : users){
System.out.println(user);
}
//6.释放资源
session.close();
in.close();
}
}
mybatis复杂条件查询
<select id="findUserByCondition" resultMap="userMap" parameterType="user">
select * from user
<where>
<if test="userName != null">
and username = #{username}
</if>
<if test="userSex != null">
and sex = #{sex}
</if>
</where>
</select>
<!-- 根据queryvo中的Id集合实现查询用户列表 -->
<select id="findUserInIds" resultMap="userMap" parameterType="queryvo">
<include refid="defaultUser"></include>
<where>
<if test="ids != null and ids.size()>0">
<foreach collection="ids" open="and id in (" close=")" item="uid" separator=",">
#{uid}
</foreach>
</if>
</where>
</select>
mybatis一对一查询
<!-- 定义封装account和user的resultMap -->
<resultMap id="accountUserMap" type="account">
<id property="id" column="aid"></id>
<result property="uid" column="uid"></result>
<result property="money" column="money"></result>
<!-- 一对一的关系映射:配置封装user的内容-->
<association property="user" column="uid" javaType="user">
<id property="id" column="id"></id>
<result column="username" property="username"></result>
<result column="address" property="address"></result>
<result column="sex" property="sex"></result>
<result column="birthday" property="birthday"></result>
</association>
</resultMap>
mybatis一对多查询
<!-- 定义User的resultMap-->
<resultMap id="userAccountMap" type="user">
<id property="id" column="id"></id>
<result property="username" column="username"></result>
<result property="address" column="address"></result>
<result property="sex" column="sex"></result>
<result property="birthday" column="birthday"></result>
<!-- 配置user对象中accounts集合的映射 -->
<collection property="accounts" ofType="account">
<id column="aid" property="id"></id>
<result column="uid" property="uid"></result>
<result column="money" property="money"></result>
</collection>
</resultMap>
_posts/2018-08-04-Mybatis-注解总结.md�����������������������������������������������������������0000664�0001750�0001750�00000006030�13763566256�021665� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: Mybatis注解总结 subtitle: Mybatis注解 date: 2018-08-04 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Mybatis —
Mybatis注解
- 第一步:建工程,导入坐标
- 第二步:实体类、接口
- 第三步:核心配置文件
- SqlMapConfig.xml
<mappers> <!-- <mapper class="cn.flyingd.dao.IUserDao" /> --> <package name="cn.flyingd.dao"></package> </mappers>
- SqlMapConfig.xml
- 第四步:完善接口上的注解
public interface IUserDao { @Select(value="select * from user") List<User> findAll(); @Select("select * from user where id= #{id}") User findById(Integer id); @Insert("insert into user(username,sex,birthday,address) values(#{userName},#{userSex},#{userBirthday},#{userAddress})") void insert(User user); @Update("update user set username = #{userName},sex=#{userSex},birthday= #{userBirthday},address=#{userAddress} where id=#{id}") void update(User user); @Delete("delete from user where id=#{id}") void deleteById(Integer id); } - 第五步:测试
- 测试类的方法
public class MybatisTest { public static void main(String[] args) { //1.读取配置文件 InputStream in = Resources.getResourceAsStream("SqlMapConfig.xml"); //2.解析核心配置文件(解析注解),创建SqlSessionFactory对象 SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); SqlSessionFactory sqlSessionFactory = builder.build(in); //3.创建SqlSession对象 SqlSession sqlSession = sqlSessionFactory.openSession(); //4.创建代理对象 IUserDao userDao = sqlSession.getMapper(IUserDao.class); //5.调用方法 List<User> userList = userDao.findAll(); userDao.insert(user); sqlSession.commit(); //6.释放资源 sqlSession.close(); in.close(); } }
- 测试类的方法
- 多对一,一对一
public interface IAccountDao{ @Select("select * from account") @Results( id="accountMap", value={ @Result(id=true,column="id",property="id"), @Result(column="uid",property="uid"), @Result(column="money",property="money"), @Reulst(property="user",column="uid", one=@One(select="cn.flyingd.dao.IUserDao.findById",fetchType= FetchType.LAZY)) } ) List<Account> findAll(); @Select("select * from account where uid= #{uid}") List<Account> findAccountByUid(Integer uid); } - 一对多,多对多
public interface IUserDao { @Select(value="select * from user") @Results( id="userMap", value={ @Result(id=true,column="id",property="id"), @Result(column="address",property="address"), @Result(column="username",property="username"), @Result(property="accountList",column="id", many = @Many(select = "cn.flyingd.dao.IAccountDao.findAccountByUid",fetchType = FetchType.LAZY)) } ) List<User> findAll(); @Select("select * from user where id= #{id}") User findById(Integer id); }_posts/2018-08-06-Mybatis-映射文件标签总结.md�����������������������������������������������0000664�0001750�0001750�00000006726�13763566256�026076� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: mybatis映射文件标签总结 subtitle: 动态sql date: 2018-08-06 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags:
-
Mybatis
-
- 动态sql:
- 1.if
<select id="findUsers1" parameterType="cn.flyingd.domain.User"> select * from user where 1=1 <if test="userName !=null "> and username = #{userName} </if> <if test="userSex !=null "> and usersex = #{userSex} </if> </select> - 2.where
<select id="findUsers1" parameterType="cn.flyingd.domain.User"> select * from user <where> <if test="userName !=null "> and username = #{userName} </if> <if test="userSex !=null "> and usersex = #{userSex} </if> </where> </select> - 3.foreach
<select id="findUsers1" parameterType="cn.flyingd.domain.QueryVo"> select * from user <where> <foreach collection="ids" open="and id in (" close=")" sperator="," item="aaa" > #{aaa} </foreach> </where> </select> - 4.sql片段
<sql id="abc" > select * from user </sql> <select id="findUsers1" parameterType="cn.flyingd.domain.QueryVo"> <include refid="abc" /> <where> <foreach collection="ids" open="and id in (" close=")" sperator="," item="aaa" > #{aaa} </foreach> </where> </select> - 5.Mybatis,多对一,看成了一对一
public class Account { private User user1; //持有引用 }public class User { }- 映射文件IAccountDao.xml ```xml
``` select a.*,u.id uid,u.address userAddress,u.sex userSex from account a left join user u on a.uid = u.id
- 6.一对多
public class User { private List<Account> accountList; }public class Account { }- 映射文件IUserDao.xml ```xml
``` select u.*,a.id aid,a.uid,a.money from user u left join account a on u.id = a.uid
- 7.Mybatis,多对多,看成一对多
public class User { private List<Role> roleList; }public class Role { }- IUserDao.xml ```xml
- 延迟加载
- 第一步:在核心配置文件SqlMapConfig.xml
<settings> <setting name="lazyLoadingEnabled" value="true" /> <setting name="aggresiveLazyLoading" value="false" /> </settings> - 第二步:
- 一对一(多对一) IAccountDao.xml ```xml
与IUserDao.xml的映射文件 ```xml <select id="findUserById2" parameterType="int" > select * from user where id=#{aaa} </select>
- 一对多(多对多) IUserDao.xml
<resultMap type="user"> <id column="id2" property="id" /> <collection property="accountList" ofType="cn.flyingd.domain.Account" javaType="java.util.List" column="id2" select="cn.flyingd.dao.IAccountDao.findAccountsByUid2" ></collection> </resultMap>IAccountDao.xml
<select id="findAccountsByUid2" parameterType="int"> select * from account where uid = #{aaa} </select>
- 延迟加载:
- 基于性能的考虑,查询A对象的时候,要不要把A关联的B对象,或者是List集合对象查出来。
- 当然,有些情况下,还必须得用立即加载,比如说商品详情。
- 第一步:在核心配置文件SqlMapConfig.xml
- 缓存,Mybatis默认支持一级缓存、二级缓存(企业中不用)
- 一级缓存,其实就是SqlSession级别的缓存
IUserDao userDao = sqlSession.getMapper(IUserDao.class); User user1 = userDao.findById(41); User user2 = userDao.findById(41); 此时只发一条sql语句,并且user1与user2是同一个对象,一级缓存,缓存的是对象``` IUserDao userDao = sqlSession.getMapper(IUserDao.class); User user1 = userDao.findById(41); sqlSession 增、删、改 sqlSession.clearCache(); User user2 = userDao.findById(41); 此时只发两条sql语句,并且user1与user2不是同一个对象
IUserDao userDao = sqlSession.getMapper(IUserDao.class); User user1 = userDao.findById(41); sqlSession.close();
sqlSession = sqlSessionFacotry.openSession(); userDao = sqlSession.getMapper(IUserDao.class); User user2 = userDao.findById(41); 此时只发两条sql语句,并且user1与user2不是同一个对象
- 二级缓存,其实就是SqlSessionFactory级别的缓存 ```xml 第一步:在核心配置文件SqlMapConfig.xml配置 <settings> <setting name="cacheEnabled" value="true" /> </settings> 第二步:在IUserDao.xml映射文件中使用二级缓存 <cache /> <select id="" parameterType="" useCache="true"> select ... </select>IUserDao userDao = sqlSession.getMapper(IUserDao.class); User user1 = userDao.findById(41); sqlSession.close(); sqlSession = sqlSessionFacotry.openSession(); userDao = sqlSession.getMapper(IUserDao.class); User user2 = userDao.findById(41); 此时只发一条sql语句,并且user1与user2不是同一个对象 为什么不是同一个对象?因为二级缓存中缓存的数据本身,而不是缓存对象 - 一级缓存,其实就是SqlSession级别的缓存
_posts/2018-09-03-Redis-Redis面试题.md�����������������������������������������������������������0000664�0001750�0001750�00000100760�14127043406�021153� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: Redis面试题 subtitle: 面试通关 date: 2018-09-03 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Redis —
常见问题:
1、为什么使用redis
- (一)性能
- 我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。
- (二)并发
- 在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问数据库。
2.使用redis有什么缺点
- (一)缓存和数据库双写一致性问题
- (二)缓存雪崩问题
- (三)缓存击穿问题
- (四)缓存的并发竞争问题
3、单线程的redis为什么这么快
- (一)纯内存操作
- (二)单线程操作,避免了频繁的上下文切换
- (三)采用了非阻塞I/O多路复用机制
参照上图,简单来说,就是。我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,文件事件分派器,依次去队列中取,转发到不同的事件处理器中。
4、redis的数据类型,以及每种数据类型的使用场景
- 回答:一共五种
- (一)String
- 这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。
- (二)hash
- 这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
- (三)list
- 使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适—取行情信息。就也是个生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
- (四)set
- 因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。
- 另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
- (五)sorted set
- sortedset多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。
5、redis的过期策略以及内存淘汰机制
- redis采用的是定期删除+惰性删除策略。
- 为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
- 定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
- 采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。在redis.conf中有一行配置# maxmemory-policy volatile-lru该配置就是配内存淘汰策略的(什么,你没配过?好好反省一下自己)
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
6、redis和数据库双写一致性问题
分析:一致性问题是分布式常见问题,还可以再分为最终一致性和强一致性。数据库和缓存双写,就必然会存在不一致的问题。答这个问题,先明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
首先,采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
7、如何应对缓存穿透和缓存雪崩问题
分析:这两个问题,说句实在话,一般中小型传统软件企业,很难碰到这个问题。如果有大并发的项目,流量有几百万左右。这两个问题一定要深刻考虑。
回答:如下所示
缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
解决方案:
(一)利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
(二)采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
(三)提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
(一)给缓存的失效时间,加上一个随机值,避免集体失效。
(二)使用互斥锁,但是该方案吞吐量明显下降了。
(三)双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点
I 从缓存A读数据库,有则直接返回
II A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
III 更新线程同时更新缓存A和缓存B。 ## 8、如何解决redis的并发竞争key问题     分析:这个问题大致就是,同时有多个子系统去set一个key。这个时候要注意什么呢?大家思考过么。需要说明一下,博主提前百度了一下,发现答案基本都是推荐用redis事务机制。博主不推荐使用redis的事务机制。因为我们的生产环境,基本都是redis集群环境,做了数据分片操作。你一个事务中有涉及到多个key操作的时候,这多个key不一定都存储在同一个redis-server上。因此,redis的事务机制,十分鸡肋。
回答:如下所示
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA–>valueB–>valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
9.Reids的特点
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过10万次读写操作,是已知性能最快的Key-Value DB。
Redis的出色之处不仅仅是性能,Redis最大的魅力是支持保存多种数据结构,此外单个value的最大限制是1GB,不像 memcached只能保存1MB的数据,因此Redis可以用来实现很多有用的功能,比方说用他的List来做FIFO双向链表,实现一个轻量级的高性 能消息队列服务,用他的Set可以做高性能的tag系统等等。另外Redis也可以对存入的Key-Value设置expire时间,因此也可以被当作一 个功能加强版的memcached来用。
Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
10.使用redis有哪些好处?
(1)速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2)支持丰富数据类型,支持string,list,set,sorted set,hash
(3)支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4)丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
11.redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
12.Memcache与Redis的区别都有哪些?
1)、存储方式 Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。Redis有部份存在硬盘上,这样能保证数据的持久性。
2)、数据支持类型Memcache对数据类型支持相对简单。Redis有复杂的数据类型。
3)、使用底层模型不同它们之间底层实现方式以及与客户端之间通信的应用协议不一样。Redis直接自己构建了VM机制,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
13.redis常见性能问题和解决方案:
1).Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
2).Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
3).Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
4). Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
14.mySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略(回收策略)。redis 提供 6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据 ## 15.redis事物的了解CAS(check-and-set 操作实现乐观锁 )? 和众多其它数据库一样,Redis作为NoSQL数据库也同样提供了事务机制。在Redis中,MULTI/EXEC/DISCARD/WATCH这四个命令是我们实现事务的基石。相信对有关系型数据库开发经验的开发者而言这一概念并不陌生,即便如此,我们还是会简要的列出Redis中事务的实现特征:
1). 在事务中的所有命令都将会被串行化的顺序执行,事务执行期间,Redis不会再为其它客户端的请求提供任何服务,从而保证了事物中的所有命令被原子的执行。
2). 和关系型数据库中的事务相比,在Redis事务中如果有某一条命令执行失败,其后的命令仍然会被继续执行。
3). 我们可以通过MULTI命令开启一个事务,有关系型数据库开发经验的人可以将其理解为”BEGINTRANSACTION”语句。在该语句之后执行的命令都将被视为事务之内的操作,最后我们可以通过执行EXEC/DISCARD命令来提交/回滚该事务内的所有操作。这两个Redis命令可被视为等同于关系型数据库中的COMMIT/ROLLBACK语句。
4). 在事务开启之前,如果客户端与服务器之间出现通讯故障并导致网络断开,其后所有待执行的语句都将不会被服务器执行。然而如果网络中断事件是发生在客户端执行EXEC命令之后,那么该事务中的所有命令都会被服务器执行。
5). 当使用Append-Only模式时,Redis会通过调用系统函数write将该事务内的所有写操作在本次调用中全部写入磁盘。然而如果在写入的过程中出现系统崩溃,如电源故障导致的宕机,那么此时也许只有部分数据被写入到磁盘,而另外一部分数据却已经丢失。 Redis服务器会在重新启动时执行一系列必要的一致性检测,一旦发现类似问题,就会立即退出并给出相应的错误提示。此时,我们就要充分利用Redis工具包中提供的redis-check-aof工具,该工具可以帮助我们定位到数据不一致的错误,并将已经写入的部 分数据进行回滚。修复之后我们就可以再次重新启动Redis服务器了。
16.WATCH命令和基于CAS的乐观锁:
在Redis的事务中,WATCH命令可用于提供CAS(check-and-set)功能。假设我们通过WATCH命令在事务执行之前监控了多个Keys,倘若在WATCH之后有任何Key的值发生了变化,EXEC命令执行的事务都将被放弃,同时返回Null multi-bulk应答以通知调用者事务执行失败。例如,我们再次假设Redis中并未提供incr命令来完成键值的原子性递增,如果要实现该功能,我们只能自行编写相应的代码。其伪码如下:
val = GET mykey
val = val + 1
SET mykey $val
以上代码只有在单连接的情况下才可以保证执行结果是正确的,因为如果在同一时刻有多个客户端在同时执行该段代码,那么就会出现多线程程序中经常出现的一种错误场景–竞态争用(race condition)。比如,客户端A和B都在同一时刻读取了mykey的原有值,假设该值为10,此后两个客户端又均将该值加一后set回Redis服务器,这样就会导致mykey的结果为11,而不是我们认为的12。为了解决类似的问题,我们需要借助WATCH命令的帮助,见如下代码:
WATCH mykey
val = GET mykey
val = val + 1
MULTI
SET mykey $val
EXEC
和此前代码不同的是,新代码在获取mykey的值之前先通过WATCH命令监控了该键,此后又将set命令包围在事务中,这样就可以有效的保证每个连接在执行EXEC之前,如果当前连接获取的mykey的值被其它连接的客户端修改,那么当前连接的EXEC命令将执行失败。这样调用者在判断返回值后就可以获悉val是否被重新设置成功。
17.redis持久化的几种方式
1、快照(snapshots) 缺省情况情况下,Redis把数据快照存放在磁盘上的二进制文件中,文件名为dump.rdb。你可以配置Redis的持久化策略,例如数据集中每N秒钟有超过M次更新,就将数据写入磁盘;或者你可以手工调用命令SAVE或BGSAVE。
工作原理
. Redis forks.
. 子进程开始将数据写到临时RDB文件中。
. 当子进程完成写RDB文件,用新文件替换老文件。
. 这种方式可以使Redis使用copy-on-write技术。 2、AOF 快照模式并不十分健壮,当系统停止,或者无意中Redis被kill掉,最后写入Redis的数据就会丢失。这对某些应用也许不是大问题,但对于要求高可靠性的应用来说,Redis就不是一个合适的选择。Append-only文件模式是另一种选择。你可以在配置文件中打开AOF模式
3、虚拟内存方式 当你的key很小而value很大时,使用VM的效果会比较好.因为这样节约的内存比较大.
当你的key不小时,可以考虑使用一些非常方法将很大的key变成很大的value,比如你可以考虑将key,value组合成一个新的value.
vm-max-threads这个参数,可以设置访问swap文件的线程数,设置最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的.可能会造成比较长时间的延迟,但是对数据完整性有很好的保证. 自己测试的时候发现用虚拟内存性能也不错。如果数据量很大,可以考虑分布式或者其他数据库
18.redis的缓存失效策略和主键失效机制
作为缓存系统都要定期清理无效数据,就需要一个主键失效和淘汰策略.
在Redis当中,有生存期的key被称为volatile。在创建缓存时,要为给定的key设置生存期,当key过期的时候(生存期为0),它可能会被删除。
1、影响生存时间的一些操作 生存时间可以通过使用 DEL 命令来删除整个 key 来移除,或者被 SET 和 GETSET 命令覆盖原来的数据,也就是说,修改key对应的value和使用另外相同的key和value来覆盖以后,当前数据的生存时间不同。
比如说,对一个 key 执行INCR命令,对一个列表进行LPUSH命令,或者对一个哈希表执行HSET命令,这类操作都不会修改 key 本身的生存时间。另一方面,如果使用RENAME对一个 key 进行改名,那么改名后的 key的生存时间和改名前一样。
RENAME命令的另一种可能是,尝试将一个带生存时间的 key 改名成另一个带生存时间的 another_key ,这时旧的 another_key (以及它的生存时间)会被删除,然后旧的 key 会改名为 another_key ,因此,新的 another_key 的生存时间也和原本的 key 一样。使用PERSIST命令可以在不删除 key 的情况下,移除 key 的生存时间,让 key 重新成为一个persistent key 。
2、如何更新生存时间
可以对一个已经带有生存时间的 key 执行EXPIRE命令,新指定的生存时间会取代旧的生存时间。过期时间的精度已经被控制在1ms之内,主键失效的时间复杂度是O(1), EXPIRE和TTL命令搭配使用,TTL可以查看key的当前生存时间。设置成功返回 1;当 key 不存在或者不能为 key 设置生存时间时,返回 0 。
最大缓存配置
在 redis 中,允许用户设置最大使用内存大小server.maxmemory 默认为0,没有指定最大缓存,如果有新的数据添加,超过最大内存,则会使redis崩溃,所以一定要设置。redis内存数据集大小上升到一定大小的时候,就会实行数据淘汰策略。
redis 提供 6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据 注意这里的6种机制,volatile和allkeys规定了是对已设置过期时间的数据集淘汰数据还是从全部数据集淘汰数据,后面的lru、ttl以及random是三种不同的淘汰策略,再加上一种no-enviction永不回收的策略。
使用策略规则:
1、如果数据呈现幂律分布,也就是一部分数据访问频率高,一部分数据访问频率低,则使用allkeys-lru
2、如果数据呈现平等分布,也就是所有的数据访问频率都相同,则使用allkeys-random
三种数据淘汰策略: ttl和random比较容易理解,实现也会比较简单。主要是Lru最近最少使用淘汰策略,设计上会对key按失效时间排序,然后取最先失效的key进行淘汰
19.redis 最适合的场景
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
1 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 、Redis支持数据的备份,即master-slave模式的数据备份。
3 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
(1)会话缓存(Session Cache)
最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在, 他们还会这样吗? 幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件。
(2)全页缓存(FPC)
除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。
再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。
此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
(3)队列
Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
如果你快速的在Google中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用Redis创建非常好的后端工具,以满足各种队列需求。例如,Celery有一个后台就是使用Redis作为broker,你可以从这里去查看。
(4)排行榜/计数器
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们 称之为“user_scores”,我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的,你可以在这里看到。
(5)发布/订阅
最后(但肯定不是最不重要的)是Redis的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核 实)。
Redis提供的所有特性中,我感觉这个是喜欢的人最少的一个,虽然它为用户提供如果此多功能。
20.Reids的特点
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。
Redis的出色之处不仅仅是性能,Redis最大的魅力是支持保存多种数据结构,此外单个value的最大限制是1GB,不像memcached只能保存1MB的数据,因此Redis可以用来实现很多有用的功能,比方说用他的List来做FIFO双向链表,实现一个轻量级的高性能消息队列服务,用他的Set可以做高性能的tag系统等等。另外Redis也可以对存入的Key-Value设置expire时间,因此也可以被当作一 个功能加强版的memcached来用。
Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
21.读写分离模型
通过增加Slave DB的数量,读的性能可以线性增长。为了避免Master DB的单点故障,集群一般都会采用两台MasterDB做双机热备,所以整个集群的读和写的可用性都非常高。
读写分离架构的缺陷在于,不管是Master还是Slave,每个节点都必须保存完整的数据,如果在数据量很大的情况下,集群的扩展能力还是受限于单个节点的存储能力,而且对于Write-intensive类型的应用,读写分离架构并不适合。
22.数据分片模型
为了解决读写分离模型的缺陷,可以将数据分片模型应用进来。
可以将每个节点看成都是独立的master,然后通过业务实现数据分片。
结合上面两种模型,可以将每个master设计成由一个master和多个slave组成的模型。
23.使用过Redis分布式锁么,它是什么回事?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
24.如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
25.如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
26.使用过Redis做异步队列么,你是怎么用的?
一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
如果对方追问可不可以不用sleep呢?list还有个指令叫blpop,在没有消息的时候,它会阻塞住直到消息到来。
如果对方追问能不能生产一次消费多次呢?使用pub/sub主题订阅者模式,可以实现1:N的消息队列。
如果对方追问pub/sub有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如rabbitmq等。
如果对方追问redis如何实现延时队列?我估计现在你很想把面试官一棒打死如果你手上有一根棒球棍的话,怎么问的这么详细。但是你很克制,然后神态自若的回答道:使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用zrangebyscore指令获取N秒之前的数据轮询进行处理。
到这里,面试官暗地里已经对你竖起了大拇指。但是他不知道的是此刻你却竖起了中指,在椅子背后。
27.如果有大量的key需要设置同一时间过期,一般需要注意什么?
如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
28.Redis如何做持久化的?
bgsave做镜像全量持久化,aof做增量持久化。因为bgsave会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要aof来配合使用。在redis实例重启时,会使用bgsave持久化文件重新构建内存,再使用aof重放近期的操作指令来实现完整恢复重启之前的状态。
对方追问如果突然机器掉电会怎样?取决于aof日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
对方追问bgsave的原理是什么?你给出两个词汇就可以了,fork和cow。fork是指redis通过创建子进程来进行bgsave操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
29.Pipeline有什么好处,为什么要用pipeline?
可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
附: 但是注意,如果使用Pipeline。当节点个数扩充后,会导致长连接数目成倍数上涨。
30.Redis的同步机制了解么?
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将rdb文件全量同步到复制节点,复制节点接受完成后将rdb镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
31.是否使用过Redis集群,集群的原理是什么?
Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。����������������_posts/2018-09-05-Redis-Redis学习笔记.md��������������������������������������������������������0000664�0001750�0001750�00000035555�14127043241�022336� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: Redis笔记 subtitle: Redis简介 date: 2018-09-05 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Redis —
Redis
1. 概念:
- redis是一款高性能的NOSQL系列的非关系型数据库
1.1.什么是NOSQL
- NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,是一项全新的数据库理念,泛指非关系型的数据库。
- 随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
- NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
1.1.1. NOSQL和关系型数据库比较
- 优点:
- 成本:
- nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
- 查询速度:
- nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
- 存储数据的格式:
- nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
- 扩展性:
- 关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。
- 成本:
- 缺点:
- 维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10几年的技术同日而语。
- 不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。
- 不提供关系型数据库对事务的处理。
1.1.2. 非关系型数据库的优势:
- 性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
- 可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
1.1.3. 关系型数据库的优势:
- 复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
- 事务支持使得对于安全性能很高的数据访问要求得以实现。对于这两类数据库,对方的优势就是自己的弱势,反之亦然。
1.1.4. 总结
- 关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在适合使用NoSQL的时候使用NoSQL数据库,
- 让NoSQL数据库对关系型数据库的不足进行弥补。
- 一般会将数据存储在关系型数据库中,在nosql数据库中备份存储关系型数据库的数据
1.2.主流的NOSQL产品
- 键值(Key-Value)存储数据库
- 相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
- 典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
- 数据模型: 一系列键值对
- 优势: 快速查询
- 劣势: 存储的数据缺少结构化
- 列存储数据库
- 相关产品:Cassandra, HBase, Riak
- 典型应用:分布式的文件系统
- 数据模型:以列簇式存储,将同一列数据存在一起
- 优势:查找速度快,可扩展性强,更容易进行分布式扩展
- 劣势:功能相对局限
- 文档型数据库
- 相关产品:CouchDB、MongoDB
- 典型应用:Web应用(与Key-Value类似,Value是结构化的)
- 数据模型: 一系列键值对
- 优势:数据结构要求不严格
- 劣势: 查询性能不高,而且缺乏统一的查询语法
- 图形(Graph)数据库
- 相关数据库:Neo4J、InfoGrid、Infinite Graph
- 典型应用:社交网络
- 数据模型:图结构
- 优势:利用图结构相关算法。
- 劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。
1.3 什么是Redis
- Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s ,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
- 字符串类型 string
- 哈希类型 hash
- 列表类型 list
- 集合类型 set
- 有序集合类型 sortedset
1.3.1 redis的应用场景
- 缓存(数据查询、短连接、新闻内容、商品内容等等)
- 聊天室的在线好友列表
- 任务队列。(秒杀、抢购、12306等等)
- 应用排行榜
- 网站访问统计
- 数据过期处理(可以精确到毫秒
- 分布式集群架构中的session分离
2. 下载安装
- 官网:https://redis.io
- 中文网:http://www.redis.net.cn/
- 解压直接可以使用:
- redis.windows.conf:配置文件
- redis-cli.exe:redis的客户端
- redis-server.exe:redis服务器端
3. 命令操作
- redis的数据结构:
- redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
- value的数据结构:
1) 字符串类型 string
2) 哈希类型 hash : map格式
3) 列表类型 list : linkedlist格式。支持重复元素 4) 集合类型 set : 不允许重复元素 5) 有序集合类型 sortedset:不允许重复元素,且元素有顺序
- value的数据结构:
1) 字符串类型 string
2) 哈希类型 hash : map格式
- redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
- 字符串类型 string
- 存储: set key value
127.0.0.1:6379> set username zhangsan OK - 获取: get key
127.0.0.1:6379> get username "zhangsan" - 删除: del key
127.0.0.1:6379> del age (integer) 1
- 存储: set key value
- 哈希类型 hash
- 存储: hset key field value
127.0.0.1:6379> hset myhash username lisi (integer) 1 127.0.0.1:6379> hset myhash password 123 (integer) 1 - 获取:
- hget key field: 获取指定的field对应的值
127.0.0.1:6379> hget myhash username "lisi" - hgetall key:获取所有的field和value
127.0.0.1:6379> hgetall myhash 1) "username" 2) "lisi" 3) "password" 4) "123"
- hget key field: 获取指定的field对应的值
- 删除: hdel key field
127.0.0.1:6379> hdel myhash username (integer) 1
- 存储: hset key field value
- 列表类型 list:可以添加一个元素到列表的头部(左边)或者尾部(右边)
- 添加:
- lpush key value: 将元素加入列表左表
- rpush key value:将元素加入列表右边
127.0.0.1:6379> lpush myList a (integer) 1 127.0.0.1:6379> lpush myList b (integer) 2 127.0.0.1:6379> rpush myList c (integer) 3
- 获取:
- lrange key start end :范围获取
127.0.0.1:6379> lrange myList 0 -1 1) "b" 2) "a" 3) "c"
- lrange key start end :范围获取
- 删除:
- lpop key: 删除列表最左边的元素,并将元素返回
- rpop key: 删除列表最右边的元素,并将元素返回
- 添加:
- 集合类型 set : 不允许重复元素
- 存储:sadd key value
127.0.0.1:6379> sadd myset a (integer) 1 127.0.0.1:6379> sadd myset a (integer) 0 - 获取:smembers key:获取set集合中所有元素
127.0.0.1:6379> smembers myset 1) "a" - 删除:srem key value:删除set集合中的某个元素
127.0.0.1:6379> srem myset a (integer) 1
- 存储:sadd key value
- 有序集合类型 sortedset:不允许重复元素,且元素有顺序.每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
- 存储:zadd key score value
127.0.0.1:6379> zadd mysort 60 zhangsan (integer) 1 127.0.0.1:6379> zadd mysort 50 lisi (integer) 1 127.0.0.1:6379> zadd mysort 80 wangwu (integer) 1 - 获取:zrange key start end [withscores]
127.0.0.1:6379> zrange mysort 0 -1 1) "lisi" 2) "zhangsan" 3) "wangwu" 127.0.0.1:6379> zrange mysort 0 -1 withscores 1) "zhangsan" 2) "60" 3) "wangwu" 4) "80" 5) "lisi" 6) "500" - 删除:zrem key value
127.0.0.1:6379> zrem mysort lisi (integer) 1
- 存储:zadd key score value
- 通用命令
- keys * : 查询所有的键
- type key : 获取键对应的value的类型
- del key:删除指定的key value
4. 持久化
- redis是一个内存数据库,当redis服务器重启,获取电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。
- redis持久化机制:
- RDB:默认方式,不需要进行配置,默认就使用这种机制
- 在一定的间隔时间中,检测key的变化情况,然后持久化数据
- 编辑redis.windwos.conf文件
# after 900 sec (15 min) if at least 1 key changed save 900 1 # after 300 sec (5 min) if at least 10 keys changed save 300 10 # after 60 sec if at least 10000 keys changed save 60 10000 - 重新启动redis服务器,并指定配置文件名称
- D:\JavaWeb2018\day23_redis\资料\redis\windows-64\redis-2.8.9>redis-server.exe redis.windows.conf
- 编辑redis.windwos.conf文件
- 在一定的间隔时间中,检测key的变化情况,然后持久化数据
- AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据
- 编辑redis.windwos.conf文件
appendonly no(关闭aof) --> appendonly yes (开启aof) # appendfsync always : 每一次操作都进行持久化 appendfsync everysec : 每隔一秒进行一次持久化 # appendfsync no : 不进行持久化
- 编辑redis.windwos.conf文件
- RDB:默认方式,不需要进行配置,默认就使用这种机制
5. Java客户端 Jedis
- Jedis: 一款java操作redis数据库的工具.
- 使用步骤:
- 下载jedis的jar包
- 使用
//1. 获取连接 Jedis jedis = new Jedis("localhost",6379); //2. 操作 jedis.set("username","zhangsan"); //3. 关闭连接 jedis.close();
-
Jedis操作各种redis中的数据结构 1) 字符串类型 string ```java //1. 获取连接 Jedis jedis = new Jedis();//如果使用空参构造,默认值 “localhost”,6379端口 //2. 操作 //存储 jedis.set(“username”,”zhangsan”); //获取 String username = jedis.get(“username”); System.out.println(username);
//可以使用setex()方法存储可以指定过期时间的 key value jedis.setex("activecode",20,"hehe");//将activecode:hehe键值对存入redis,并且20秒后自动删除该键值对 //3. 关闭连接 jedis.close(); ``` 2) 哈希类型 hash : map格式 ```java //1. 获取连接 Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口 //2. 操作 // 存储hash jedis.hset("user","name","lisi"); jedis.hset("user","age","23"); jedis.hset("user","gender","female"); // 获取hash String name = jedis.hget("user", "name"); System.out.println(name); // 获取hash的所有map中的数据 Map<String, String> user = jedis.hgetAll("user"); // keyset Set<String> keySet = user.keySet(); for (String key : keySet) { //获取value String value = user.get(key); System.out.println(key + ":" + value); } //3. 关闭连接 jedis.close(); ``` 3) 列表类型 list : linkedlist格式。支持重复元素 ```java //1. 获取连接 Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口 //2. 操作 // list 存储 jedis.lpush("mylist","a","b","c");//从左边存 jedis.rpush("mylist","a","b","c");//从右边存 // list 范围获取 List<String> mylist = jedis.lrange("mylist", 0, -1); System.out.println(mylist); // list 弹出 String element1 = jedis.lpop("mylist");//c System.out.println(element1); String element2 = jedis.rpop("mylist");//c System.out.println(element2); // list 范围获取 List<String> mylist2 = jedis.lrange("mylist", 0, -1); System.out.println(mylist2); //3. 关闭连接 jedis.close(); ``` 4) 集合类型 set : 不允许重复元素 ```java //1. 获取连接 Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口 //2. 操作 // set 存储 jedis.sadd("myset","java","php","c++"); // set 获取 Set<String> myset = jedis.smembers("myset"); System.out.println(myset); //3. 关闭连接 jedis.close(); ``` 5) 有序集合类型 sortedset:不允许重复元素,且元素有顺序 ```java //1. 获取连接 Jedis jedis = new Jedis();//如果使用空参构造,默认值 "localhost",6379端口 //2. 操作 // sortedset 存储 jedis.zadd("mysortedset",3,"亚瑟"); jedis.zadd("mysortedset",30,"后裔"); jedis.zadd("mysortedset",55,"孙悟空"); // sortedset 获取 Set<String> mysortedset = jedis.zrange("mysortedset", 0, -1); System.out.println(mysortedset); //3. 关闭连接 jedis.close(); ``` - jedis连接池: JedisPool
- 使用:
- 创建JedisPool连接池对象
- 调用方法 getResource()方法获取Jedis连接
//0.创建一个配置对象 JedisPoolConfig config = new JedisPoolConfig(); config.setMaxTotal(50); config.setMaxIdle(10); //1.创建Jedis连接池对象 JedisPool jedisPool = new JedisPool(config,"localhost",6379); //2.获取连接 Jedis jedis = jedisPool.getResource(); //3. 使用 jedis.set("hehe","heihei"); //4. 关闭 归还到连接池中 jedis.close();
- 连接池工具类
public class JedisPoolUtils { private static JedisPool jedisPool; static{ //读取配置文件 InputStream is = JedisPoolUtils.class.getClassLoader().getResourceAsStream("jedis.properties"); //创建Properties对象 Properties pro = new Properties(); //关联文件 try { pro.load(is); } catch (IOException e) { e.printStackTrace(); } //获取数据,设置到JedisPoolConfig中 JedisPoolConfig config = new JedisPoolConfig(); config.setMaxTotal(Integer.parseInt(pro.getProperty("maxTotal"))); config.setMaxIdle(Integer.parseInt(pro.getProperty("maxIdle"))); //初始化JedisPool jedisPool = new JedisPool(config,pro.getProperty("host"),Integer.parseInt(pro.getProperty("port"))); } /** * 获取连接方法 */ public static Jedis getJedis(){ return jedisPool.getResource(); } }_posts/2018-10-05-ORM-ORM思想.md������������������������������������������������������������������0000664�0001750�0001750�00000004611�13763566256�017013� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: ORM思想解析 subtitle: ORM date: 2018-10-05 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags:
-
ORM
- 使用:
ORM
对象关系映射(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。从效果上说,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。
广义上,ORM指的是面向对象的对象模型和关系型数据库的数据结构之间的相互转换。 狭义上,ORM可以被认为是,基于关系型数据库的数据存储,实现一个虚拟的面向对象的数据访问接口。
什么是O,R,M?
O(对象模型): 实体对象,即我们在程序中根据数据库表结构建立的一个个实体Entity。
R(关系型数据库的数据结构): 即我们建立的数据库表。
M(映射): 从R(数据库)到O(对象模型)的映射,可通过XML文件映射。
为什么使用ORM?
提高开发效率:ORM框架自动实现Entity实体的属性与关系型数据库字段的映射。CRUD的工作则可以交给ORM来自动生成代码方式实现。隐藏了数据访问细节,“封闭”的通用数据库交互,他使得我们的通用数据库交互变得简单易行,并且完全不用考虑SQL语句。大大提高我们开发效率, 这样一来也减少我们维护一个复杂 缺乏灵活性数据访问层的成本。
ORM作为是一种思想,帮助我们开发人员跟踪实体的变化,并将实体的变化翻译成sql脚本,执行到数据库中去,也就是将实体的变化映射到了表的变化。这样会给我们带来非常大的便利。但有得必有失,便利的同时也无可避免的带来了一些其他的问题:比如性能降低,复杂的查询ORM仍然力不从心等。
不得不说,任何优势的背后都隐藏着缺点,这是不可避免的。问题在于,我们是否能容忍这些缺点。这需要结合项目的具体情况考虑使用这项技术是否利大于弊 。
这篇博客只是介绍了ORM这种思想,具体实现这种思想的框架已有很多,Herberate,iBatis,NHerberate,,EF等,这些框架都大同小异。下篇博客会以最近项目中使用的EF为例,给大家做详细的介绍。 �����������������������������������������������������������������������������������������������������������������������_posts/2018-10-07-Lucene-Lucene总结.md������������������������������������������������������������0000664�0001750�0001750�00000012277�13763566256�020447� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: lucene总结 subtitle: lucene date: 2018-10-07 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Lucene —
重点:
- lucene创建索引
Document/Field/Directory/IndexWriterConfig/IndexWriter - 查询索引
QueryParser/MultiFieldQueryParser/Query/IndexSearcher/TopDocs/ScoreDoc
TermQuery/WildcardQuery/FuzzyQuery/NumericRangeQuery - 维护索引:文档的增删改 文档的修改(先删除,再添加)
indexWriter.addDocument
indexWriter.updateDocument
indexWriter.deleteDocuments
1.为什么要学Lucene?学了Lucene,在哪里应用?
- 搜索,数据库字符串模糊查询,查询商品名称中带有”笔记本”
- 业内,专门用搜索服务器来处理搜索,主要是为了提高搜索效率,为了更好的用户体验。
- 搜索服务器,主要有两种:ElasticSearch/Solr,底层都用到了Lucene
2.几个重要的概念(类比图书馆的例子)
- 倒排索引:(最重要,之所以能够全文检索就是靠倒排索引)
- 就是从关键字(词条)到文档的映射过程,保存这种映射信息的索引称为反向索引,也叫倒排索引。
- 倒排索引用到了倒排索引链表保存词条与文档的映射信息,及词条出现在哪些文档上,出现的频率信息。
- 大白话:根据片段找到完整记录的过程
听歌识曲
书籍的索引页
- 全文索引:基于倒排索引技术,采用分词器,对文本每个词进行切分,建立词条,方便进行查找。
- 采用倒排索引技术,将词条和文档建立对应关系。
- 全文检索:
- 将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,
- 然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
- 这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
- 这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
3.使用lucene api创建索引Document/Field/Directory/IndexWriterConfig/IndexWriter
- lucene:是集成了搜索分词算法的jar库,lucene不能单独使用。
- 市场上集成了该lucene库有哪些搜索服务器,如ElasticSearch、Solr。
- lucene类库
- ElasticSearch、Solr是基于lucene发展出来的搜索服务器技术
- 官网:http://lucene.apache.org/
- 创建索引(库)的过程
- 第一步:获取原始文档(类似于图书馆来了一车书)
- 第二步:创建Document(准备工作,准备对书分门别类)
- 第三步:创建Field(Field叫做字段,也叫域,创建Field,对书做分门别类)
- 第四步:把Document写入索引库(把书按照门类以及书架放好)
- 文档有不同字段,字段类型也不同,字段也叫做域
- StringField(索引但是默认不分词,数据被当成一个词条), Term(词条)
- TextField(索引并且根据索引写入器中定义的分词器来进行分词,数据被当做多个词条)
- StoreField一定会被存储,但是一定不创建索引
- 要通过构造函数中的参数Store来指定:Store.YES代表存储,Store.NO代表不存储
- 问题1:如何确定一个字段是否需要存储?
- 如果一个字段要显示到最终的结果中,那么一定要存储,否则就不存储
- 要么在创建该Field对象的时候,指定Field.Store.YES
- 要么加一句: Field fieldSizeStore = new StoredField(“size”, fileSize);
- 不需要存储,可以使用LongPoint
- 问题2:如何确定一个字段是否需要创建索引?
- 如果要根据这个字段进行搜索,那么这个字段就必须创建索引。
- 问题3:如何确定一个字段是否需要分词?
- 前提是这个字段首先要创建索引。然后如果这个字段的值是不可分割的,那么就不需要分词。
- 例如:ID 身份证号不要分词,专有名词不需要分词 StringField 以上除外,都要分词,都可以用TextField
4.查询索引
- IndexSearcher/QueryParser/MultiFieldQueryParser/Query/TopDocs/ScoreDoc
- TermQuery/WildcardQuery/FuzzyQuery/NumericRangeQuery
- 第一步:创建索引查询对象 IndexSearcher,需要用到DirectoryReader对象
- 第二步:调用查询方法,得到查询结果TopDocs
- 需要用到QueryParser(单一字段的查询解析器)解析出Query对象
- TopDocs topDocs = indexSearcher.search(query, 10);
- 第三步:解析查询结果
//得分文档集合 ScoreDoc[] scoreDocs = topDocs.scoreDocs;queryParser:先分词再查询 Query query = queryParser.parse("lucene是一个Java开发的全文检索工具包"); TermQuery:词条精准查询 WildcardQuery:通配符查询 ?匹配单个字符 *匹配0或者多个字符 FuzzyQuery:模糊查询 允许错两次,通过纠错、补位、移动位置 容错性 25% NumericRangeQuery:数值范围查询 1 <= x <= 10 [1,5] (1,5) [1,5) (1,5]5.修改索引/删除索引
indexWriter.updateDocument indexWriter.deleteDocuments
完成:
理解概念:倒排索引、全文索引、全文检索 ���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2018-10-09-职位-职位解释.md������������������������������������������������������������0000664�0001750�0001750�00000027677�14127043405�022204� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: 职位释义 subtitle: 职场 date: 2018-10-09 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - 职位 - 杂记 —
CEO(Chief executive officer)首席执行官
CTO(Chief technology officer)首席技术官
CIO(Chief information officer)首席信息官
CFO(Chief financial officer)首席财务官
COO(Chief operating officer)首席运营官
- CEO(Chief Executive Officer),即首席执行官,是美国人在20世纪60年代进行公司治理结构改革创新时的产物。
- 由于市场风云变幻,决策的速度和执行的力度比以往任何时候都更加重要。 传统的“董事会决策、经理层执行”的公司体制已经难以满足决策的需要。而且, 决策层和执行层之间存在的信息传递时滞和沟通障碍、决策成本的增加,已经严 重影响经理层对企业重大决 策的快速反应和执行能力。而解决这一问题的首要一 点,就是让经理人拥有更多自主决策的权力,让经理人更多为自己的决策奋斗、对 自己的行为负责。CEO就是这种变革的产物。CEO在某种意义上代表着将原来董事会 手中的一些决策权过渡到经营层手中。
- CEO与总经理,形式上都是企业的“一把手”,CEO既是行政一把手,又是股东 权益代言人————大多数情况下,CEO是作为董事会成员出现的,总经理则不一定 是董事会成员。从这个意义上讲,CEO代表着企业,并对企业经营负责。 由于国外没有类似的上级主管和来自四面八方的牵制,CEO的权威比国内的总经理们更绝对,但他们绝不会像总经理那样过多介入公司的具体事务。CEO作出总体决 策后,具体执行权力就会下放。所以有人说,CEO就像我国50%的董事长加上50%的总经理。
- 一般来讲,CEO的主要职责有三方面:①对公司所有重大事务和人事任免进行决 策,决策后,权力就下放给具体主管,CEO具体干预的较少;②营造一种促使员工愿 意为公司服务的企业文化;③把公司的整体形象推销出去。
- CTO是个技术主管,CIO是个具有技术背景或对技术有些了解地公司高层。
- 通常CIO向CEO汇报,或向CFO汇报。CIO不需要是个技术大拿,但对技术必须非常敏感,并能发掘技术带给公司地潜力。随着IT在各公司地重要性日渐提高,CIO地地位也渐高,有时能进入公司地最高决策层。CIO是个桥梁,把公司地商业模式和技术连接起来。基本上CTO就是一个技术大拿,熟练掌握公司地核心技术,并可以带领团队开发或使用新技术来帮助公司达到目标。基本上CTO不会是公司地最高层。
- 企业CIO和CTO有着明显地区别,但是最大地区别不是在于他们对技术地掌握程度和深度,而是在于他们对企业战略地驾驭能力和适应能力。
- CTO有时候也会成为公司地最高层,特别是一些以技术为核心竞争力地企业来说。首先,我们来解读一下什么是CTO。其实,CTO(首席技术官)作为一个外来名词,在中国还不多见,随着网络热潮传进中国地CXO系列中地一员,CTO给人留下地印象只是技术人员所能达到地最高职位。“但当技术日益成为影响企业发展地决定因素时,CTO也就成为对企业发展起着决定性作用地人群之一。
- 在美国,CTO除了负责技术支持和技术改良等日常工作外,其主要职责是设计公司地未来工作。从某种意义上说,CTO地首要工作是提出公司未来两三年内地产品和服务地技术发展方向。
- 尽管CTO这个名词是引进来了,但在角色职能定义方面同国外还存在一定差距。作为一个高科技公司地CTO,其更多地工作应该是前瞻性地,也就是制定下一代产品地策略和进行研究工作,属于技术战略地重要执行者。
- 在国内来看,大部分地企业里地“CTO”都是过去地“工程师”摇身一变而成地,因此带着很强地技术色彩。在一些通过技术安身立命地高科技企业,这些工程师出身地CTO也往往能够占据核心领导地位。但是在其他地行业中,例如一些传统地行业,一些把市场营销能力作为核心竞争力地企业,CTO地作用就大打折扣,CIO就逐渐浮出水面了。
- “CIO”即信息总监,他通过组织和利用企业地IT资源,为企业创造效益。通过信息化掌握了企业地业务命脉以及战略方向地CIO,很可能向决策管理层地地位继续上升,直到达到权力地顶峰—CEO。
- 一家美国主导企业地首席执行官和一群首席信息官进行了一次谈话,讨论首席信息官在现代公司中地作用。在谈话进行到一半地时候,他直截了当地说:“首席信息官也许是我最重要地经理人。没有他们,我不知道我地公司会是怎样。”由此可见CIO在企业中地重要作用了。
- 在CIO成功地基本素质中,其中有一项是要精通企业以及相关行业地知识。要搞信息化,一个CIO至少要熟悉企业地研发、生产、计划、营销、市场、物流等核心业务流程,熟悉企业地财务管理、组织结构、行政程序、人力资源管理等基础资源,以及企业发展地远景、价值观等企业地文化范畴。在这基础上,CIO才能对企业地IT建设和信息资源做出正确地规划。
- 因此如果你想成为一个成功地CIO,那么最好远离电脑,去积极培养作为企业管理者应该具备地各种能力。对500名CIO所做地调查发现,70%地人认为通往成功地关键是有效地沟通;58%地人选择谙熟商业流程和运作;而46%地人则认为战略性地思想和计划能力很重要。而此前被认为很重要地IT技能,只获得了10%地认可。这不能不说是一个巨大地观念改变。
- CFO(Chief Financial Officer)意指公司首席财政官或财务总监,是现代公司中最重要、最有价值的顶尖管理职位之一,是掌握着企业的神经系统(财务信息)和血液系统(现金资源)灵魂人物。
- 做一名成功的CFO需要具备丰富的金融理论知识和实务经验。公司理财与金融市场交互、项目估价、风险管理、产品研发、战略规划、企业核心竞争力的识别与建立以及洞悉信息技术及电子商务对企业的冲击等自然都是CFO职责范围内的事。
- 在一个大型公司运作中,CFO是一个穿插在金融市场操作和公司内部财务管理之间的角色。担当CFO的人才大多是拥有多年在金融市场驰骋经验的人。在美国,优秀的CFO常常在华尔街做过成功的基金经理人。
- COO(chief Operation officer) 的职责主要是负责公司的日常营运,辅助CEO的工作。
- 一般来讲,COO负责公司职能管理组织体系的建设,并代表CEO处理企业的日常职能事务。如果公司未设有总裁职务,则COO还要承担整体业务管理的职能,主管企业营销与综合业务拓展,负责建立公司整个的销售策略与政策,组织生产经营,协助CEO制定公司的业务发展计划,并对公司的经营绩效进行考核。
- 其他一些为各个岗位才较为常见的简称:
- 首席品牌官【CBO】 chief brand officer
- 首席文化官【CCO】 Chief Cultural Officer
- 开发总监【CDO】 chief Development officer
- 人事总监 【CHO】 Chief Human resource officer
- 首席知识官【CKO】 chief knowledge officer
- 首席市场官【CMO】 chief Marketing officer
- 首席谈判官【CNO】 chief Negotiation officer
- 公关总监【CPO】 chief Public relation officer
- 质量总监【CQO】 chief Quality officer
- 销售总监【CSO】 chief Sales officer
- 评估总监【CVO】 chief Valuation officer
技术部
- 计算机/互联网/通讯 Technology/Internet
- 首席技术执行官 CTO/VP Engineering
- 技术总监/经理 Technical Director/Manager
- 信息技术经理 IT Manager
- 信息技术主管 IT Supervisor
- 信息技术专员 IT Specialist
- 项目经理/主管 Project Manager/Supervisor
- 项目执行/协调人员 Project Specialist / Coordinator
- 系统分析员 System Analyst
- 高级软件工程师 Senior Software Engineer
- 软件工程师 Software Engineer
- 系统工程师 System Engineer
- 高级硬件工程师 Senior Hardware Engineer
- 硬件工程师 Hardware Engineer
- 通信技术工程师 Communications Engineer
- ERP技术/应用顾问 ERP Technical/Application Consultant
测试运维部
- 数据库工程师 Database Engineer
- 技术支持经理 Technical Support Manager
- 技术支持工程师 Technical Support Engineer
- 品质经理 QA Manager
- 信息安全工程师 Information Security Engineer
- 软件测试工程师 Software QA Engineer
- 硬件测试工程师 Hardware QA Engineer
- 测试员 Test Engineer
- 网站营运经理/主管 Web Operations Manager/Supervisor
- 网络工程师 Network Engineer
- 系统管理员/网管 System Manager/Webmaster
- 网页设计/制作 Web Designer/Production
- 技术文员/助理 Technical Clerk/Assistant
销售部
- 销售 Sales
- 销售总监 Sales Director
- 销售经理 Sales Manager
- 区域销售经理 Regional Sales Manager
- 客户经理 Sales Account Manager
- 渠道/分销经理 Channel/Distribution Manager
- 渠道主管 Channel Supervisor
- 销售主管 Sales Supervisor
- 销售代表 Sales Representative / Executive
- 销售工程师 Sales Engineer
- 医药代表 Pharmaceutical Sales Representative
- 保险代理 Insurance Agent
- 销售助理 Sales Assistant / Trainee
- 商务经理 Business Manager
- 商务专员/助理 Business Executive/Assistant
- 销售行政经理 Sales Admin. Manager
- 销售行政主管 Sales Admin. Supervisor
- 售前/售后技术服务经理 Technical Service Manager
- 售前/售后技术服务主管 Technical Service Supervisor
- 售前/售后技术服务工程师 Technical Service Engineer
- 售后/客户服务(非技术)经理 Customer Service Manager
- 售后/客户服务(非技术)主管 Customer Service Supervisor
- 售后/客户服务(非技术)专员 Customer Service Executive
- 经销商 Distributor
市场部
- 市场/公关/广告 Marketing/PR/Advertising
- 市场/广告总监 Marketing/Advertising Director/VP
- 市场/营销经理 Marketing Manager
- 市场/营销主管 Marketing Supervisor
- 市场/营销专员 Marketing Executive/Communication
- 市场助理 Marketing Assistant / Trainee
- 产品/品牌经理 Product/Brand Manager
- 产品/品牌主管 Product/Brand Supervisor
- 市场通路经理 Trade Marketing Manager
- 市场通路主管 Trade Marketing Supervisor
- 促销经理 Promotions Manager
- 促销主管 Promotions Supervisor
- 促销员 Promotions Specialist
- 市场分析/调研人员 Market Analyst/ Research Analyst
- 公关/会务经理 Public Relations Manager
- 公关/会务主管 Public Relations Supervisor
- 公关/会务专员 Public Relations Executive
- 媒介经理 Media Manager
- 媒介人员 Media Specialist
- 企业/业务发展经理 Business Development Manager
- 企业策划人员 Corporate Planning
- 广告策划/设计/文案 Advertising Creative/Design/Copy writer
经理岗位
- GM(General Manager)总经理
- VP(Vice President)副总裁
- FVP(First Vice President)第一副总裁
- AVP(Assistant Vice President)副总裁助理
- HRD(Human Resource Director)人力资源总监
- OD(Operations Director)运营总监
- MD(Marketing Director)市场总监
- OM(Operations Manager)运作经理
- PM(Production Manager生产经理、Product Manager产品经理、Project Manager项目经理) 注:这里面变化比较多,要结合谈话时的背景来判断究竟是指哪种身份)
- BM(Branch Manager)部门经理
- DM(District Manager)区域经理
- RM(Regional Manager)区域经理 �����������������������������������������������������������������_posts/2020-10-04-架构师-知识图谱.md���������������������������������������������������������0000664�0001750�0001750�00000351726�14127043406�023470� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: 架构师知识图谱
subtitle: 收集整理规划架构师成长路径上需要提升的技能
date: 2020-10-04
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
- 架构师
-
杂记
《后端架构师技术图谱》
推荐: 《Java技术书籍大全》 - awesome-java-books
从初级开发者到资深架构师,看这些书就够了
- 数据结构
- 常用算法
- 并发
- 操作系统
- 设计模式
- 运维 & 统计 & 技术支持
- 中间件
- 网络
- 数据库
- 搜索引擎
- 性能
- 大数据
- 安全
- 常用开源框架
- 分布式设计
- 设计思想 & 开发模式
- 项目管理
- 通用业务术语
- 技术趋势
- 政策、法规
- 架构师素质
- 团队管理
- 资讯
- 技术资源
(Toc generated by simple-php-github-toc )
数据结构
队列
- 《java队列——queue详细分析》
- 非阻塞队列:ConcurrentLinkedQueue(无界线程安全),采用CAS机制(compareAndSwapObject原子操作)。
- 阻塞队列:ArrayBlockingQueue(有界)、LinkedBlockingQueue(无界)、DelayQueue、PriorityBlockingQueue,采用锁机制;使用 ReentrantLock 锁。
- 《LinkedList、ConcurrentLinkedQueue、LinkedBlockingQueue对比分析》
集合
链表、数组
字典、关联数组
栈
- 《java数据结构与算法之栈(Stack)设计与实现》
- 《Java Stack 类》
- 《java stack的详细实现分析》
- Stack 是线程安全的。
- 内部使用数组保存数据,不够时翻倍。
树
二叉树
每个节点最多有两个叶子节点。
完全二叉树
- 《完全二叉树》
- 叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
平衡二叉树
左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
二叉查找树(BST)
二叉查找树(Binary Search Tree),也称有序二叉树(ordered binary tree),排序二叉树(sorted binary tree)。
红黑树
- 《最容易懂得红黑树》
- 添加阶段后,左旋或者右旋从而再次达到平衡。
- 《浅谈算法和数据结构: 九 平衡查找树之红黑树》
B,B+,B*树
MySQL是基于B+树聚集索引组织表
- 《B-树,B+树,B*树详解》
- 《B-树,B+树与B*树的优缺点比较》
- B+树的叶子节点链表结构相比于 B-树便于扫库,和范围检索。
LSM 树
- B+树的叶子节点链表结构相比于 B-树便于扫库,和范围检索。
LSM(Log-Structured Merge-Trees)和 B+ 树相比,是牺牲了部分读的性能来换取写的性能(通过批量写入),实现读写之间的平衡。 Hbase、LevelDB、Tair(Long DB)、nessDB 采用 LSM 树的结构。LSM可以快速建立索引。
- 《LSM树 VS B+树》
- B+ 树读性能好,但由于需要有序结构,当key比较分散时,磁盘寻道频繁,造成写性能较差。
- LSM 是将一个大树拆分成N棵小树,先写到内存(无寻道问题,性能高),在内存中构建一颗有序小树(有序树),随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历(二分查找)所有的小树,但在每颗小树内部数据是有序的。
- 《LSM树(Log-Structured Merge Tree)存储引擎》
- 极端的说,基于LSM树实现的HBase的写性能比MySQL高了一个数量级,读性能低了一个数量级。
- 优化方式:Bloom filter 替代二分查找;compact 小数位大树,提高查询性能。
- Hbase 中,内存中达到一定阈值后,整体flush到磁盘上、形成一个文件(B+数),HDFS不支持update操作,所以Hbase做整体flush而不是merge update。flush到磁盘上的小树,定期会合并成一个大树。
BitSet
经常用于大规模数据的排重检查。
常用算法
排序、查找算法
选择排序
- 《Java中的经典算法之选择排序(SelectionSort)》
- 每一趟从待排序的记录中选出最小的元素,顺序放在已排好序的序列最后,直到全部记录排序完毕。
冒泡排序
- 《冒泡排序的2种写法》
- 相邻元素前后交换、把最大的排到最后。
- 时间复杂度 O(n²)
插入排序
快速排序
- 《坐在马桶上看算法:快速排序》
- 一侧比另外一侧都大或小。
归并排序
- 一侧比另外一侧都大或小。
- 《图解排序算法(四)之归并排序》
- 分而治之,分成小份排序,在合并(重建一个新空间进行复制)。
希尔排序
TODO
堆排序
- 《图解排序算法(三)之堆排序》
- 排序过程就是构建最大堆的过程,最大堆:每个结点的值都大于或等于其左右孩子结点的值,堆顶元素是最大值。
计数排序
- 《计数排序和桶排序》
- 和桶排序过程比较像,差别在于桶的数量。
桶排序
- 《【啊哈!算法】最快最简单的排序——桶排序》
- 《排序算法(三):计数排序与桶排序》
- 桶排序将[0,1)区间划分为n个相同的大小的子区间,这些子区间被称为桶。
- 每个桶单独进行排序,然后再遍历每个桶。
基数排序
按照个位、十位、百位、…依次来排。
二分查找
- 《二分查找(java实现)》
- 要求待查找的序列有序。
- 时间复杂度 O(logN)。
- 《java实现二分查找-两种方式》
- while + 递归。
Java 中的排序工具
- while + 递归。
- 《Arrays.sort和Collections.sort实现原理解析》
- Collections.sort算法调用的是合并排序。
- Arrays.sort() 采用了2种排序算法 – 基本类型数据使用快速排序法,对象数组使用归并排序。
布隆过滤器
常用于大数据的排重,比如email,url 等。 核心原理:将每条数据通过计算产生一个指纹(一个字节或多个字节,但一定比原始数据要少很多),其中每一位都是通过随机计算获得,在将指纹映射到一个大的按位存储的空间中。注意:会有一定的错误率。 优点:空间和时间效率都很高。 缺点:随着存入的元素数量增加,误算率随之增加。
- 《布隆过滤器 – 空间效率很高的数据结构》
- 《大量数据去重:Bitmap和布隆过滤器(Bloom Filter)》
- 《基于Redis的布隆过滤器的实现》
- 基于 Redis 的 Bitmap 数据结构。
- 《网络爬虫:URL去重策略之布隆过滤器(BloomFilter)的使用》
- 使用Java中的 BitSet 类 和 加权和hash算法。
字符串比较
KMP 算法
KMP:Knuth-Morris-Pratt算法(简称KMP) 核心原理是利用一个“部分匹配表”,跳过已经匹配过的元素。
深度优先、广度优先
贪心算法
回溯算法
剪枝算法
动态规划
朴素贝叶斯
- 《带你搞懂朴素贝叶斯分类算法》
-
P(B A)=P(A B)P(B)/P(A)
-
- 《贝叶斯推断及其互联网应用1》
- 《贝叶斯推断及其互联网应用2》
推荐算法
最小生成树算法
最短路径算法
并发
Java 并发
多线程
线程安全
一致性、事务
事务 ACID 特性
事务的隔离级别
- 未提交读:一个事务可以读取另一个未提交的数据,容易出现脏读的情况。
- 读提交:一个事务等另外一个事务提交之后才可以读取数据,但会出现不可重复读的情况(多次读取的数据不一致),读取过程中出现UPDATE操作,会多。(大多数数据库默认级别是RC,比如SQL Server,Oracle),读取的时候不可以修改。
- 可重复读: 同一个事务里确保每次读取的时候,获得的是同样的数据,但不保障原始数据被其他事务更新(幻读),Mysql InnoDB 就是这个级别。
-
序列化:所有事物串行处理(牺牲了效率)
- 《理解事务的4种隔离级别》
- 《MySQL的InnoDB的幻读问题 》
- 幻读的例子非常清楚。
- 通过 SELECT … FOR UPDATE 解决。
- 《一篇文章带你读懂MySQL和InnoDB》
- 图解脏读、不可重复读、幻读问题。
MVCC
- 《【mysql】关于innodb中MVCC的一些理解》
- innodb 中 MVCC 用在 Repeatable-Read 隔离级别。
- MVCC 会产生幻读问题(更新时异常。)
-
- 通过隐藏版本列来实现 MVCC 控制,一列记录创建时间、一列记录删除时间,这里的时间
- 每次只操作比当前版本小(或等于)的 行。
锁
Java中的锁和同步类
- 《Java中的锁分类》
- 主要包括 synchronized、ReentrantLock、和 ReadWriteLock。
- 《Java中信号量 Semaphore》
- 有数量控制
- 申请用 acquire,申请不要则阻塞;释放用 release。
- 《java开发中的Mutex vs Semaphore》
- 简单的说 就是Mutex是排它的,只有一个可以获取到资源, Semaphore也具有排它性,但可以定义多个可以获取的资源的对象。
公平锁 & 非公平锁
公平锁的作用就是严格按照线程启动的顺序来执行的,不允许其他线程插队执行的;而非公平锁是允许插队的。
- 《公平锁与非公平锁》
- 默认情况下 ReentrantLock 和 synchronized 都是非公平锁。ReentrantLock 可以设置成公平锁。
悲观锁
悲观锁如果使用不当(锁的条数过多),会引起服务大面积等待。推荐优先使用乐观锁+重试。
- 《【MySQL】悲观锁&乐观锁》
- 乐观锁的方式:版本号+重试方式
- 悲观锁:通过 select … for update 进行行锁(不可读、不可写,share 锁可读不可写)。
- 《Mysql查询语句使用select.. for update导致的数据库死锁分析》
- mysql的innodb存储引擎实务锁虽然是锁行,但它内部是锁索引的。
- 锁相同数据的不同索引条件可能会引起死锁。
- 《Mysql并发时经典常见的死锁原因及解决方法》
乐观锁 & CAS
- 《乐观锁的一种实现方式——CAS》
- 和MySQL乐观锁方式相似,只不过是通过和原值进行比较。
ABA 问题
由于高并发,在CAS下,更新后可能此A非彼A。通过版本号可以解决,类似于上文Mysql 中提到的的乐观锁。
- 《Java CAS 和ABA问题》
- 《Java 中 ABA问题及避免》
- AtomicStampedReference 和 AtomicStampedReference。
CopyOnWrite容器
可以对CopyOnWrite容器进行并发的读,而不需要加锁。CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新场景,不适合需要数据强一致性的场景。
- 《JAVA中写时复制(Copy-On-Write)Map实现》
- 实现读写分离,读取发生在原始数据上,写入发生在副本上。
- 不用加锁,通过最终一致实现一致性。
- 《聊聊并发-Java中的Copy-On-Write容器》
RingBuffer
可重入锁 & 不可重入锁
- 《可重入锁和不可重入锁》
- 通过简单代码举例说明可重入锁和不可重入锁。
- 可重入锁指同一个线程可以再次获得之前已经获得的锁。
- 可重入锁可以用户避免死锁。
- Java中的可重入锁:synchronized 和 java.util.concurrent.locks.ReentrantLock
- 《ReenTrantLock可重入锁(和synchronized的区别)总结》
- synchronized 使用方便,编译器来加锁,是非公平锁。
- ReenTrantLock 使用灵活,锁的公平性可以定制。
- 相同加锁场景下,推荐使用 synchronized。
互斥锁 & 共享锁
互斥锁:同时只能有一个线程获得锁。比如,ReentrantLock 是互斥锁,ReadWriteLock 中的写锁是互斥锁。 共享锁:可以有多个线程同时或的锁。比如,Semaphore、CountDownLatch 是共享锁,ReadWriteLock 中的读锁是共享锁。
死锁
- 《“死锁”四个必要条件的合理解释》
- 互斥、持有、不可剥夺、环形等待。
- Java如何查看死锁?
- JConsole 可以识别死锁。
- java多线程系列:死锁及检测
- jstack 可以显示死锁。
操作系统
计算机原理
CPU
多级缓存
典型的 CPU 有三级缓存,距离核心越近,速度越快,空间越小。L1 一般 32k,L2 一般 256k,L3 一般12M。内存速度需要200个 CPU 周期,CPU 缓存需要1个CPU周期。
进程
TODO
线程
协程
- 《终结python协程—-从yield到actor模型的实现》
- 线程的调度是由操作系统负责,协程调度是程序自行负责
- 与线程相比,协程减少了无谓的操作系统切换.
- 实际上当遇到IO操作时做切换才更有意义,(因为IO操作不用占用CPU),如果没遇到IO操作,按照时间片切换.
Linux
设计模式
设计模式的六大原则
- 《设计模式的六大原则》
- 开闭原则:对扩展开放,对修改关闭,多使用抽象类和接口。
- 里氏替换原则:基类可以被子类替换,使用抽象类继承,不使用具体类继承。
- 依赖倒转原则:要依赖于抽象,不要依赖于具体,针对接口编程,不针对实现编程。
- 接口隔离原则:使用多个隔离的接口,比使用单个接口好,建立最小的接口。
- 迪米特法则:一个软件实体应当尽可能少地与其他实体发生相互作用,通过中间类建立联系。
- 合成复用原则:尽量使用合成/聚合,而不是使用继承。
23种常见设计模式
应用场景
- 《细数JDK里的设计模式》
- 结构型模式:
- 适配器:用来把一个接口转化成另一个接口,如 java.util.Arrays#asList()。
- 桥接模式:这个模式将抽象和抽象操作的实现进行了解耦,这样使得抽象和实现可以独立地变化,如JDBC;
- 组合模式:使得客户端看来单个对象和对象的组合是同等的。换句话说,某个类型的方法同时也接受自身类型作为参数,如 Map.putAll,List.addAll、Set.addAll。
-
装饰者模式:动态的给一个对象附加额外的功能,这也是子类的一种替代方式,如 java.util.Collections#checkedList Map Set SortedSet SortedMap。 - 享元模式:使用缓存来加速大量小对象的访问时间,如 valueOf(int)。
- 代理模式:代理模式是用一个简单的对象来代替一个复杂的或者创建耗时的对象,如 java.lang.reflect.Proxy
- 创建模式:
- 抽象工厂模式:抽象工厂模式提供了一个协议来生成一系列的相关或者独立的对象,而不用指定具体对象的类型,如 java.util.Calendar#getInstance()。
- 建造模式(Builder):定义了一个新的类来构建另一个类的实例,以简化复杂对象的创建,如:java.lang.StringBuilder#append()。
- 工厂方法:就是 一个返* 回具体对象的方法,而不是多个,如 java.lang.Object#toString()、java.lang.Class#newInstance()。
- 原型模式:使得类的实例能够生成自身的拷贝、如:java.lang.Object#clone()。
- 单例模式:全局只有一个实例,如 java.lang.Runtime#getRuntime()。
- 行为模式:
- 责任链模式:通过把请求从一个对象传递到链条中下一个对象的方式,直到请求被处理完毕,以实现对象间的解耦。如 javax.servlet.Filter#doFilter()。
- 命令模式:将操作封装到对象内,以便存储,传递和返回,如:java.lang.Runnable。
- 解释器模式:定义了一个语言的语法,然后解析相应语法的语句,如,java.text.Format,java.text.Normalizer。
- 迭代器模式:提供一个一致的方法来顺序访问集合中的对象,如 java.util.Iterator。
- 中介者模式:通过使用一个中间对象来进行消息分发以及减少类之间的直接依赖,java.lang.reflect.Method#invoke()。
- 空对象模式:如 java.util.Collections#emptyList()。
- 观察者模式:它使得一个对象可以灵活的将消息发送给感兴趣的对象,如 java.util.EventListener。
- 模板方法模式:让子类可以重写方法的一部分,而不是整个重写,如 java.util.Collections#sort()。
- 结构型模式:
- 《Spring-涉及到的设计模式汇总》
- 《Mybatis使用的设计模式》
单例模式
责任链模式
TODO
MVC
- 《MVC 模式》
- 模型(model)-视图(view)-控制器(controller)
IOC
- 《理解 IOC》
- 《IOC 的理解与解释》
- 正向控制:传统通过new的方式。反向控制,通过容器注入对象。
- 作用:用于模块解耦。
- DI:Dependency Injection,即依赖注入,只关心资源使用,不关心资源来源。
AOP
- 《轻松理解AOP(面向切面编程)》
- 《Spring AOP详解》
- 《Spring AOP的实现原理》
- Spring AOP使用的动态代理,主要有两种方式:JDK动态代理和CGLIB动态代理。
- 《Spring AOP 实现原理与 CGLIB 应用》
- Spring AOP 框架对 AOP 代理类的处理原则是:如果目标对象的实现类实现了接口,Spring AOP 将会采用 JDK 动态代理来生成 AOP 代理类;如果目标对象的实现类没有实现接口,Spring AOP 将会采用 CGLIB 来生成 AOP 代理类
UML
微服务思想
康威定律
- 《微服务架构的理论基础 - 康威定律》
- 定律一:组织沟通方式会通过系统设计表达出来,就是说架构的布局和组织结构会有相似。
- 定律二:时间再多一件事情也不可能做的完美,但总有时间做完一件事情。一口气吃不成胖子,先搞定能搞定的。
- 定律三:线型系统和线型组织架构间有潜在的异质同态特性。种瓜得瓜,做独立自治的子系统减少沟通成本。
- 定律四:大的系统组织总是比小系统更倾向于分解。合久必分,分而治之。
- 《微服务架构核⼼20讲》
运维 & 统计 & 技术支持
常规监控
- 《腾讯业务系统监控的修炼之路》
- 监控的方式:主动、被动、旁路(比如舆情监控)
- 监控类型: 基础监控、服务端监控、客户端监控、 监控、用户端监控
- 监控的目标:全、块、准
- 核心指标:请求量、成功率、耗时
- 《开源还是商用?十大云运维监控工具横评》
- Zabbix、Nagios、Ganglia、Zenoss、Open-falcon、监控宝、 360网站服务监控、阿里云监控、百度云观测、小蜜蜂网站监测等。
- 《监控报警系统搭建及二次开发经验》
命令行监控工具
- 《常用命令行监控工具》
- top、sar、tsar、nload
- 《JVM性能调优监控工具jps、jstack、jmap、jhat、jstat、hprof使用详解》
APM
APM — Application Performance Management
- 主要开源软件,按字母排序
- 《开源APM技术选型与实战》
- 主要基于 Google的Dapper(大规模分布式系统的跟踪系统) 思想。
统计分析
- 《流量统计的基础:埋点》
- 常用指标:访问与访客、停留时长、跳出率、退出率、转化率、参与度
- 《APP埋点常用的统计工具、埋点目标和埋点内容》
- 第三方统计:友盟、百度移动、魔方、App Annie、talking data、神策数据等。
- 《美团点评前端无痕埋点实践》
- 所谓无痕、即通过可视化工具配置采集节点,在前端自动解析配置并上报埋点数据,而非硬编码。
持续集成(CI/CD)
Jenkins
环境分离
开发、测试、生成环境分离。
自动化运维
Ansible
puppet
chef
测试
TDD 理论
- 《深度解读 - TDD(测试驱动开发)》
- 基于测试用例编码功能代码,XP(Extreme Programming)的核心实践.
- 好处:一次关注一个点,降低思维负担;迎接需求变化或改善代码的设计;提前澄清需求;快速反馈;
单元测试
- 《Java单元测试之JUnit篇》
- 《JUnit 4 与 TestNG 对比》
- TestNG 覆盖 JUnit 功能,适用于更复杂的场景。
- 《单元测试主要的测试功能点》
- 模块接口测试、局部数据结构测试、路径测试 、错误处理测试、边界条件测试 。
压力测试
全链路压测
A/B 、灰度、蓝绿测试
-
[《技术干货 AB 测试和灰度发布探索及实践》](https://testerhome.com/topics/11165) - 《蓝绿部署、A/B 测试以及灰度发布》
虚拟化
KVM
Xen
OpenVZ
容器技术
Docker
云技术
OpenStack
DevOps
文档管理
- Confluence-收费文档管理系统
- GitLab?
- Wiki
中间件
Web Server
Nginx
- 《Ngnix的基本学习-多进程和Apache的比较》
- Nginx 通过异步非阻塞的事件处理机制实现高并发。Apache 每个请求独占一个线程,非常消耗系统资源。
- 事件驱动适合于IO密集型服务(Nginx),多进程或线程适合于CPU密集型服务(Apache),所以Nginx适合做反向代理,而非web服务器使用。
- 《nginx与Apache的对比以及优缺点》
- nginx只适合静态和反向代理,不适合处理动态请求。
OpenResty
- 官方网站
- 《浅谈 OpenResty》
- 通过 Lua 模块可以在Nginx上进行开发。
- agentzh 的 Nginx 教程
Tengine
Apache Httpd
Tomcat
架构原理
- 《TOMCAT原理详解及请求过程》
- 《Tomcat服务器原理详解》
- 《JBoss vs. Tomcat: Choosing A Java Application Server》
- Tomcat 是轻量级的 Serverlet 容器,没有实现全部 JEE 特性(比如持久化和事务处理),但可以通过其他组件代替,比如Spring。
- Jboss 实现全部了JEE特性,软件开源免费、文档收费。
调优方案
- 《Tomcat 调优方案》
- 启动NIO模式(或者APR);调整线程池;禁用AJP连接器(Nginx+tomcat的架构,不需要AJP);
- 《tomcat http协议与ajp协议》
- 《AJP与HTTP比较和分析》
- AJP 协议(8009端口)用于降低和前端Server(如Apache,而且需要支持AJP协议)的连接数(前端),通过长连接提高性能。
- 并发高时,AJP协议优于HTTP协议。
Jetty
- 《Jetty 的工作原理以及与 Tomcat 的比较》
- 《jetty和tomcat优势比较》
- 架构比较:Jetty的架构比Tomcat的更为简单。
- 性能比较:Jetty和Tomcat性能方面差异不大,Jetty默认采用NIO结束在处理I/O请求上更占优势,Tomcat默认采用BIO处理I/O请求,Tomcat适合处理少数非常繁忙的链接,处理静态资源时性能较差。
- 其他方面:Jetty的应用更加快速,修改简单,对新的Servlet规范的支持较好;Tomcat 对JEE和Servlet 支持更加全面。
缓存
本地缓存
- 《EhCache本地缓存》
- 堆内、堆外、磁盘三级缓存。
- 可按照缓存空间容量进行设置。
- 按照时间、次数等过期策略。
- 《Guava Cache》
- 简单轻量、无堆外、磁盘缓存。
- 《Pagespeed—懒人工具,服务器端加速》
客户端缓存
- 《浏览器端缓存》
- 主要是利用 Cache-Control 参数。
- 《H5 和移动端 WebView 缓存机制解析与实战》
服务端缓存
Web缓存
Memcached
- 《Memcached 教程》
- 《深入理解Memcached原理》
- 采用多路复用技术提高并发性。
- slab分配算法: memcached给Slab分配内存空间,默认是1MB。分配给Slab之后 把slab的切分成大小相同的chunk,Chunk是用于缓存记录的内存空间,Chunk 的大小默认按照1.25倍的速度递增。好处是不会频繁申请内存,提高IO效率,坏处是会有一定的内存浪费。
- 《Memcached软件工作原理》
- 《memcache 中 add 、 set 、replace 的区别》
- 区别在于当key存在还是不存在时,返回值是true和false的。
- 《memcached全面剖析》
Redis
- 《Redis 教程》
- 《redis底层原理》
- 使用 ziplist 存储链表,ziplist是一种压缩链表,它的好处是更能节省内存空间,因为它所存储的内容都是在连续的内存区域当中的。
- 使用 skiplist(跳跃表)来存储有序集合对象、查找上先从高Level查起、时间复杂度和红黑树相当,实现容易,无锁、并发性好。
- 《Redis持久化方式》
- RDB方式:定期备份快照,常用于灾难恢复。优点:通过fork出的进程进行备份,不影响主进程、RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。缺点:会丢数据。
- AOF方式:保存操作日志方式。优点:恢复时数据丢失少,缺点:文件大,回复慢。
- 也可以两者结合使用。
- 《分布式缓存–序列3–原子操作与CAS乐观锁》
架构
回收策略
Tair
- 官方网站
- 《Tair和Redis的对比》
- 特点:可以配置备份节点数目,通过异步同步到备份节点
- 一致性Hash算法。
- 架构:和Hadoop 的设计思想类似,有Configserver,DataServer,Configserver 通过心跳来检测,Configserver也有主备关系。
几种存储引擎:
- MDB,完全内存性,可以用来存储Session等数据。
- Rdb(类似于Redis),轻量化,去除了aof之类的操作,支持Restfull操作
- LDB(LevelDB存储引擎),持久化存储,LDB 作为rdb的持久化,google实现,比较高效,理论基础是LSM(Log-Structured-Merge Tree)算法,现在内存中修改数据,达到一定量时(和内存汇总的旧数据一同写入磁盘)再写入磁盘,存储更加高效,县比喻Hash算法。
- Tair采用共享内存来存储数据,如果服务挂掉(非服务器),重启服务之后,数据亦然还在。
消息队列
- 《消息队列-推/拉模式学习 & ActiveMQ及JMS学习》
- RabbitMQ 消费者默认是推模式(也支持拉模式)。
- Kafka 默认是拉模式。
- Push方式:优点是可以尽可能快地将消息发送给消费者,缺点是如果消费者处理能力跟不上,消费者的缓冲区可能会溢出。
- Pull方式:优点是消费端可以按处理能力进行拉去,缺点是会增加消息延迟。
- 《Kafka、RabbitMQ、RocketMQ等消息中间件的对比 —— 消息发送性能和区别》
消息总线
消息总线相当于在消息队列之上做了一层封装,统一入口,统一管控、简化接入成本。
消息的顺序
RabbitMQ
支持事务,推拉模式都是支持、适合需要可靠性消息传输的场景。
RocketMQ
Java实现,推拉模式都是支持,吞吐量逊于Kafka。可以保证消息顺序。
ActiveMQ
纯Java实现,兼容JMS,可以内嵌于Java应用中。
Kafka
高吞吐量、采用拉模式。适合高IO场景,比如日志同步。
Redis 消息推送
生产者、消费者模式完全是客户端行为,list 和 拉模式实现,阻塞等待采用 blpop 指令。
ZeroMQ
TODO
定时调度
单机定时调度
- 《Linux cron运行原理》
- fork 进程 + sleep 轮询
- 《Quartz使用总结》
- 《Quartz源码解析 —- 触发器按时启动原理》
- 《quartz原理揭秘和源码解读》
- 定时调度在 QuartzSchedulerThread 代码中,while()无限循环,每次循环取出时间将到的trigger,触发对应的job,直到调度器线程被关闭。
分布式定时调度
- 《这些优秀的国产分布式任务调度系统,你用过几个?》
- opencron、LTS、XXL-JOB、Elastic-Job、Uncode-Schedule、Antares
- 《Quartz任务调度的基本实现原理》
- Quartz集群中,独立的Quartz节点并不与另一其的节点或是管理节点通信,而是通过相同的数据库表来感知到另一Quartz应用的
- 《Elastic-Job-Lite 源码解析》
- 《Elastic-Job-Cloud 源码解析》
RPC
- 《从零开始实现RPC框架 - RPC原理及实现》
- 核心角色:Server: 暴露服务的服务提供方、Client: 调用远程服务的服务消费方、Registry: 服务注册与发现的注册中心。
- 《分布式RPC框架性能大比拼 dubbo、motan、rpcx、gRPC、thrift的性能比较》
Dubbo
** SPI ** TODO
Thrift
- 官方网站
- 《Thrift RPC详解》
- 支持多语言,通过中间语言定义接口。
gRPC
服务端可以认证加密,在外网环境下,可以保证数据安全。
数据库中间件
Sharding Jdbc
日志系统
日志搜集
配置中心
- Apollo - 携程开源的配置中心应用
- Spring Boot 和 Spring Cloud
- 支持推、拉模式更新配置
- 支持多种语言
- 《 Spring Cloud Config 分布式配置中心使用教程》
servlet 3.0 异步特性可用于配置中心的客户端
API 网关
主要职责:请求转发、安全认证、协议转换、容灾。
网络
协议
OSI 七层协议
TCP/IP
HTTP
HTTP2.0
- 《HTTP 2.0 原理详细分析》
- 《HTTP2.0的基本单位为二进制帧》
- 利用二进制帧负责传输。
- 多路复用。
HTTPS
- 《https原理通俗了解》
- 使用非对称加密协商加密算法
- 使用对称加密方式传输数据
- 使用第三方机构签发的证书,来加密公钥,用于公钥的安全传输、防止被中间人串改。
- 《八大免费SSL证书-给你的网站免费添加Https安全加密》
网络模型
- 《web优化必须了解的原理之I/o的五种模型和web的三种工作模式》
- 五种I/O模型:阻塞I/O,非阻塞I/O,I/O复用、事件(信号)驱动I/O、异步I/O,前四种I/O属于同步操作,I/O的第一阶段不同、第二阶段相同,最后的一种则属于异步操作。
- 三种 Web Server 工作方式:Prefork(多进程)、Worker方式(线程方式)、Event方式。
- 《select、poll、epoll之间的区别总结》
- select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。
- select 有打开文件描述符数量限制,默认1024(2048 for x64),100万并发,就要用1000个进程、切换开销大;poll采用链表结构,没有数量限制。
- select,poll “醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,通过回调机制节省大量CPU时间;select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,而epoll只要一次拷贝。
- poll会随着并发增加,性能逐渐下降,epoll采用红黑树结构,性能稳定,不会随着连接数增加而降低。
- 《select,poll,epoll比较 》
- 在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
- 《深入理解Java NIO》
- NIO 是一种同步非阻塞的 IO 模型。同步是指线程不断轮询 IO 事件是否就绪,非阻塞是指线程在等待 IO 的时候,可以同时做其他任务
- 《两种高效的服务器设计模型:Reactor和Proactor模型》
Epoll
Java NIO
kqueue
连接和短连接
框架
- 《Netty原理剖析》
- Reactor 模式介绍。
- Netty 是 Reactor 模式的一种实现。
零拷贝(Zero-copy)
- 《对于 Netty ByteBuf 的零拷贝(Zero Copy) 的理解》
- 多个物理分离的buffer,通过逻辑上合并成为一个,从而避免了数据在内存之间的拷贝。
序列化(二进制协议)
Hessian
- 《Hessian原理分析》 Binary-RPC;不仅仅是序列化
Protobuf
- 《Protobuf协议的Java应用例子》 Goolge出品、占用空间和效率完胜其他序列化类库,如Hessian;需要编写 .proto 文件。
-
《Protocol Buffers序列化协议及应用》 * 关于协议的解释;缺点:可读性差;
- 《简单的使用 protobuf 和 protostuff》
- protostuff 的好处是不用写 .proto 文件,Java 对象直接就可以序列化。
数据库
基础理论
关系数据库设计的三大范式
- 《数据库的三大范式以及五大约束》
- 第一范式:数据表中的每一列(每个字段)必须是不可拆分的最小单元,也就是确保每一列的原子性;
- 第二范式(2NF):满足1NF后,要求表中的所有列,都必须依赖于主键,而不能有任何一列与主键没有关系,也就是说一个表只描述一件事情;
- 第三范式:必须先满足第二范式(2NF),要求:表中的每一列只与主键直接相关而不是间接相关,(表中的每一列只能依赖于主键);
MySQL
原理
- 《MySQL存储引擎--MyISAM与InnoDB区别》
- 两种类型最主要的差别就是Innodb 支持事务处理与外键和行级锁
- 《myisam和innodb索引实现的不同》
InnoDB
优化
- 《MYSQL性能优化的最佳20+条经验》
- 《SQL优化之道》
- 《mysql数据库死锁的产生原因及解决办法》
- 《导致索引失效的可能情况》
- 《 MYSQL分页limit速度太慢优化方法》
- 原则上就是缩小扫描范围。
索引
聚集索引, 非聚集索引
MyISAM 是非聚集,InnoDB 是聚集
复合索引
- 《复合索引的优点和注意事项》
- 文中有一处错误:
对于复合索引,在查询使用时,最好将条件顺序按找索引的顺序,这样效率最高; select * from table1 where col1=A AND col2=B AND col3=D 如果使用 where col2=B AND col1=A 或者 where col2=B 将不会使用索引
- 原文中提到索引是按照“col1,col2,col3”的顺序创建的,而mysql在按照最左前缀的索引匹配原则,且会自动优化 where 条件的顺序,当条件中只有 col2=B AND col1=A 时,会自动转化为 col1=A AND col2=B,所以依然会使用索引。
- 文中有一处错误:
- 《MySQL查询where条件的顺序对查询效率的影响》
自适应哈希索引(AHI)
explain
NoSQL
MongoDB
- MongoDB 教程
- 《Mongodb相对于关系型数据库的优缺点》
- 优点:弱一致性(最终一致),更能保证用户的访问速度;内置GridFS,支持大容量的存储;Schema-less 数据库,不用预先定义结构;内置Sharding;相比于其他NoSQL,第三方支持丰富;性能优越;
- 缺点:mongodb不支持事务操作;mongodb占用空间过大;MongoDB没有如MySQL那样成熟的维护工具,这对于开发和IT运营都是个值得注意的地方;
Hbase
- 《简明 HBase 入门教程(开篇)》
- 《深入学习HBase架构原理》
- 《Hbase与传统数据库的区别》
- 空数据不存储,节省空间,且适用于并发。
- 《HBase Rowkey设计》
- rowkey 按照字典顺序排列,便于批量扫描。
- 通过散列可以避免热点。
搜索引擎
搜索引擎原理
Lucene
Elasticsearch
Solr
sphinx
性能
性能优化方法论
- 《15天的性能优化工作,5方面的调优经验》
- 代码层面、业务层面、数据库层面、服务器层面、前端优化。
- 《系统性能优化的几个方面》
容量评估
- 《联网性能与容量评估的方法论和典型案例》
- 《互联网架构,如何进行容量设计?》
- 评估总访问量、评估平均访问量QPS、评估高峰QPS、评估系统、单机极限QPS
CDN 网络
连接池
性能调优
大数据
流式计算
Storm
Flink
Kafka Stream
应用场景
例如:
- 广告相关实时统计;
- 推荐系统用户画像标签实时更新;
- 线上服务健康状况实时监测;
- 实时榜单;
- 实时数据统计。
Hadoop
HDFS
MapReduce
Yarn
Spark
安全
web 安全
XSS
SQL 注入
Hash Dos
- 《邪恶的JAVA HASH DOS攻击》
- 利用JsonObject 上传大Json,JsonObject 底层使用HashMap;不同的数据产生相同的hash值,使得构建Hash速度变慢,耗尽CPU。
- 《一种高级的DoS攻击-Hash碰撞攻击》
- 《关于Hash Collision DoS漏洞:解析与解决方案》
脚本注入
漏洞扫描工具
验证码
- 《详解滑动验证码的实现原理》
- 滑动验证码是根据人在滑动滑块的响应时间,拖拽速度,时间,位置,轨迹,重试次数等来评估风险。
- 《淘宝滑动验证码研究》
DDoS 防范
用户隐私信息保护
- 用户密码非明文保存,加动态salt。
- 身份证号,手机号如果要显示,用 “*” 替代部分字符。
- 联系方式在的显示与否由用户自己控制。
- TODO
序列化漏洞
加密解密
对称加密
- 《常见对称加密算法》
- DES、3DES、Blowfish、AES
- DES 采用 56位秘钥,Blowfish 采用1到448位变长秘钥,AES 128,192和256位长度的秘钥。
- DES 秘钥太短(只有56位)算法目前已经被 AES 取代,并且 AES 有硬件加速,性能很好。
哈希算法
- 《常用的哈希算法》
- MD5 和 SHA-1 已经不再安全,已被弃用。
- 目前 SHA-256 是比较安全的。
- 《基于Hash摘要签名的公网URL签名验证设计方案》
非对称加密
- 《常见非对称加密算法》
- RSA、DSA、ECDSA(螺旋曲线加密算法)
- 和 RSA 不同的是 DSA 仅能用于数字签名,不能进行数据加密解密,其安全性和RSA相当,但其性能要比RSA快。
-
256位的ECC秘钥的安全性等同于3072位的RSA秘钥。
服务器安全
数据安全
数据备份
TODO
网络隔离
内外网分离
TODO
登录跳板机
在内外环境中通过跳板机登录到线上主机。
授权、认证
RBAC
OAuth2.0
双因素认证(2FA)
2FA - Two-factor authentication,用于加强登录验证
常用做法是 登录密码 + 手机验证码(或者令牌Key,类似于与网银的 USB key)
- 【《双因素认证(2FA)教程》】(http://www.ruanyifeng.com/blog/2017/11/2fa-tutorial.html)
单点登录(SSO)
常用开源框架
开源协议
日志框架
Log4j、Log4j2
- 《log4j 详细讲解》
- 《log4j2 实际使用详解》
- 《Log4j1,Logback以及Log4j2性能测试对比》
- Log4J 异步日志性能优异。
Logback
ORM
- 《ORM框架使用优缺点》
- 主要目的是为了提高开发效率。
MyBatis:
- 《mybatis缓存机制详解》
- 一级缓存是SqlSession级别的缓存,缓存的数据只在SqlSession内有效
- 二级缓存是mapper级别的缓存,同一个namespace公用这一个缓存,所以对SqlSession是共享的;使用 LRU 机制清理缓存,通过 cacheEnabled 参数开启。
- 《MyBatis学习之代码生成器Generator》
网络框架
TODO
Web 框架
Spring 家族
Spring
Spring Boot
Spring Cloud
工具框架
分布式设计
扩展性设计
- 《架构师不可不知的十大可扩展架构》
- 总结下来,通用的套路就是分布、缓存及异步处理。
- 《可扩展性设计之数据切分》
- 水平切分+垂直切分
- 利用中间件进行分片如,MySQL Proxy。
- 利用分片策略进行切分,如按照ID取模。
- 《说说如何实现可扩展性的大型网站架构》
- 分布式服务+消息队列。
- 《大型网站技术架构(七)–网站的可扩展性架构》
稳定性 & 高可用
- 《系统设计:关于高可用系统的一些技术方案》
- 可扩展:水平扩展、垂直扩展。 通过冗余部署,避免单点故障。
- 隔离:避免单一业务占用全部资源。避免业务之间的相互影响 2. 机房隔离避免单点故障。
- 解耦:降低维护成本,降低耦合风险。减少依赖,减少相互间的影响。
- 限流:滑动窗口计数法、漏桶算法、令牌桶算法等算法。遇到突发流量时,保证系统稳定。
- 降级:紧急情况下释放非核心功能的资源。牺牲非核心业务,保证核心业务的高可用。
- 熔断:异常情况超出阈值进入熔断状态,快速失败。减少不稳定的外部依赖对核心服务的影响。
- 自动化测试:通过完善的测试,减少发布引起的故障。
- 灰度发布:灰度发布是速度与安全性作为妥协,能够有效减少发布故障。
- 《关于高可用的系统》
- 设计原则:数据不丢(持久化);服务高可用(服务副本);绝对的100%高可用很难,目标是做到尽可能多的9,如99.999%(全年累计只有5分钟)。
硬件负载均衡
- 《转!!负载均衡器技术Nginx和F5的优缺点对比》
- 主要是和F5对比。
- 《软/硬件负载均衡产品 你知多少?》
软件负载均衡
- 《几种负载均衡算法》 轮寻、权重、负载、最少连接、QoS
- 《DNS负载均衡》
- 配置简单,更新速度慢。
- 《Nginx负载均衡》
- 简单轻量、学习成本低;主要适用于web应用。
- 《借助LVS+Keepalived实现负载均衡 》
- 配置比较负载、只支持到4层,性能较高。
- 《HAProxy用法详解 全网最详细中文文档》
- 支持到七层(比如HTTP)、功能比较全面,性能也不错。
- 《Haproxy+Keepalived+MySQL实现读均衡负载》
- 主要是用户读请求的负载均衡。
- 《rabbitmq+haproxy+keepalived实现高可用集群搭建》
限流
- 《谈谈高并发系统的限流》
- 计数器:通过滑动窗口计数器,控制单位时间内的请求次数,简单粗暴。
- 漏桶算法:固定容量的漏桶,漏桶满了就丢弃请求,比较常用。
- 令牌桶算法:固定容量的令牌桶,按照一定速率添加令牌,处理请求前需要拿到令牌,拿不到令牌则丢弃请求,或进入丢队列,可以通过控制添加令牌的速率,来控制整体速度。Guava 中的 RateLimiter 是令牌桶的实现。
- Nginx 限流:通过
limit_req等模块限制并发连接数。
应用层容灾
- 《防雪崩利器:熔断器 Hystrix 的原理与使用》
- 雪崩效应原因:硬件故障、硬件故障、程序Bug、重试加大流量、用户大量请求。
- 雪崩的对策:限流、改进缓存模式(缓存预加载、同步调用改异步)、自动扩容、降级。
- Hystrix设计原则:
- 资源隔离:Hystrix通过将每个依赖服务分配独立的线程池进行资源隔离, 从而避免服务雪崩。
- 熔断开关:服务的健康状况 = 请求失败数 / 请求总数,通过阈值设定和滑动窗口控制开关。
- 命令模式:通过继承 HystrixCommand 来包装服务调用逻辑。
- 《缓存穿透,缓存击穿,缓存雪崩解决方案分析》
- 《缓存击穿、失效以及热点key问题》
- 主要策略:失效瞬间:单机使用锁;使用分布式锁;不过期;
- 热点数据:热点数据单独存储;使用本地缓存;分成多个子key;
跨机房容灾
- 《“异地多活”多机房部署经验谈》
- 通过自研中间件进行数据同步。
- 《异地多活(异地双活)实践经验》
- 注意延迟问题,多次跨机房调用会将延时放大数倍。
- 建房间专线很大概率会出现问题,做好运维和程序层面的容错。
- 不能依赖于程序端数据双写,要有自动同步方案。
- 数据永不在高延迟和较差网络质量下,考虑同步质量问题。
- 核心业务和次要业务分而治之,甚至只考虑核心业务。
- 异地多活监控部署、测试也要跟上。
- 业务允许的情况下考虑用户分区,尤其是游戏、邮箱业务。
- 控制跨机房消息体大小,越小越好。
- 考虑使用docker容器虚拟化技术,提高动态调度能力。
- 容灾技术及建设经验介绍
容灾演练流程
- 《依赖治理、灰度发布、故障演练,阿里电商故障演练系统的设计与实战经验》
- 常见故障画像
- 案例:预案有效性、预案有效性、故障复现、架构容灾测试、参数调优、参数调优、故障突袭、联合演练。
平滑启动
-
平滑重启应用思路 1.端流量(如vip层)、2. flush 数据(如果有)、3, 重启应用
- 《JVM安全退出(如何优雅的关闭java服务)》 推荐推出方式:System.exit,Kill SIGTERM;不推荐 kill-9;用 Runtime.addShutdownHook 注册钩子。
- 《常见Java应用如何优雅关闭》 Java、Spring、Dubbo 优雅关闭方式。
数据库扩展
读写分离模式
- 《Mysql主从方案的实现》
- 《搭建MySQL主从复制经典架构》
- 《DRBD+Heartbeat+Mysql高可用读写分离架构》
- DRDB 进行磁盘复制,避免单点问题。
- 《MySQL Cluster 方式》
分片模式
- 《分库分表需要考虑的问题及方案》
- 中间件: 轻量级:sharding-jdbc、TSharding;重量级:Atlas、MyCAT、Vitess等。
- 问题:事务、Join、迁移、扩容、ID、分页等。
- 事务补偿:对数据进行对帐检查;基于日志进行比对;定期同标准数据来源进行同步等。
- 分库策略:数值范围;取模;日期等。
- 分库数量:通常 MySQL 单库 5千万条、Oracle 单库一亿条需要分库。
- 《MySql分表和表分区详解》
- 分区:是MySQL内部机制,对客户端透明,数据存储在不同文件中,表面上看是同一个表。
- 分表:物理上创建不同的表、客户端需要管理分表路由。
服务治理
服务注册与发现
- 《永不失联!如何实现微服务架构中的服务发现?》
- 客户端服务发现模式:客户端直接查询注册表,同时自己负责负载均衡。Eureka 采用这种方式。
- 服务器端服务发现模式:客户端通过负载均衡查询服务实例。
- 《SpringCloud服务注册中心比较:Consul vs Zookeeper vs Etcd vs Eureka》
- CAP支持:Consul(CA)、zookeeper(cp)、etcd(cp) 、euerka(ap)
- 作者认为目前 Consul 对 Spring cloud 的支持比较好。
- 《基于Zookeeper的服务注册与发现》
- 优点:API简单、Pinterest,Airbnb 在用、多语言、通过watcher机制来实现配置PUSH,能快速响应配置变化。
服务路由控制
- 《分布式服务框架学习笔记4 服务路由》
- 原则:透明化路由
- 负载均衡策略:随机、轮询、服务调用延迟、一致性哈希、粘滞连接
- 本地路由优先策略:injvm(优先调用jvm内部的服务),innative(优先使用相同物理机的服务),原则上找距离最近的服务。
- 配置方式:统一注册表;本地配置;动态下发。
分布式一致
CAP 与 BASE 理论
- 《从分布式一致性谈到CAP理论、BASE理论》
- 一致性分类:强一致(立即一致);弱一致(可在单位时间内实现一致,比如秒级);最终一致(弱一致的一种,一定时间内最终一致)
- CAP:一致性、可用性、分区容错性(网络故障引起)
- BASE:Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)
- BASE理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
分布式锁
- 《分布式锁的几种实现方式》
- 基于数据库的分布式锁:优点:操作简单、容易理解。缺点:存在单点问题、数据库性能够开销较大、不可重入;
- 基于缓存的分布式锁:优点:非阻塞、性能好。缺点:操作不好容易造成锁无法释放的情况。
- Zookeeper 分布式锁:通过有序临时节点实现锁机制,自己对应的节点需要最小,则被认为是获得了锁。优点:集群可以透明解决单点问题,避免锁不被释放问题,同时锁可以重入。缺点:性能不如缓存方式,吞吐量会随着zk集群规模变大而下降。
- 《基于Zookeeper的分布式锁》
- 清楚的原理描述 + Java 代码示例。
- 《jedisLock—redis分布式锁实现》
- 基于 setnx(set if ont exists),有则返回false,否则返回true。并支持过期时间。
- 《Memcached 和 Redis 分布式锁方案》
- 利用 memcached 的 add(有别于set)操作,当key存在时,返回false。
分布式一致性算法
PAXOS
Zab
Raft
- 《Raft 为什么是更易理解的分布式一致性算法》
- 三种角色:Leader(领袖)、Follower(群众)、Candidate(候选人)
- 通过随机等待的方式发出投票,得票多的获胜。
Gossip
两阶段提交、多阶段提交
幂等
- 《分布式系统—幂等性设计》
- 幂等特性的作用:该资源具备幂等性,请求方无需担心重复调用会产生错误。
- 常见保证幂等的手段:MVCC(类似于乐观锁)、去重表(唯一索引)、悲观锁、一次性token、序列号方式。
分布式一致方案
分布式 Leader 节点选举
TCC(Try/Confirm/Cancel) 柔性事务
- 《传统事务与柔性事务》
- 基于BASE理论:基本可用、柔性状态、最终一致。
- 解决方案:记录日志+补偿(正向补充或者回滚)、消息重试(要求程序要幂等);“无锁设计”、采用乐观锁机制。
分布式文件系统
- 说说分布式文件存储系统-基本架构 ?
- 《各种分布式文件系统的比较》 ?
- HDFS:大批量数据读写,用于高吞吐量的场景,不适合小文件。
- FastDFS:轻量级、适合小文件。
唯一ID 生成
全局唯一ID
- 《高并发分布式系统中生成全局唯一Id汇总》
- Twitter 方案(Snowflake 算法):41位时间戳+10位机器标识(比如IP,服务器名称等)+12位序列号(本地计数器)
- Flicker 方案:MySQL自增ID + “REPLACE INTO XXX:SELECT LAST_INSERT_ID();”
- UUID:缺点,无序,字符串过长,占用空间,影响检索性能。
- MongoDB 方案:利用 ObjectId。缺点:不能自增。
- 《TDDL 在分布式下的SEQUENCE原理》
- 在数据库中创建 sequence 表,用于记录,当前已被占用的id最大值。
- 每台客户端主机取一个id区间(比如 1000~2000)缓存在本地,并更新 sequence 表中的id最大值记录。
- 客户端主机之间取不同的id区间,用完再取,使用乐观锁机制控制并发。
一致性Hash算法
设计思想 & 开发模式
DDD(Domain-driven Design - 领域驱动设计)
- 《浅谈我对DDD领域驱动设计的理解》
- 概念:DDD 主要对传统软件开发流程(分析-设计-编码)中各阶段的割裂问题而提出,避免由于一开始分析不明或在软件开发过程中的信息流转不一致而造成软件无法交付(和需求方设想不一致)的问题。DDD 强调一切以领域(Domain)为中心,强调领域专家(Domain Expert)的作用,强调先定义好领域模型之后在进行开发,并且领域模型可以指导开发(所谓的驱动)。
- 过程:理解领域、拆分领域、细化领域,模型的准确性取决于模型的理解深度。
- 设计:DDD 中提出了建模工具,比如聚合、实体、值对象、工厂、仓储、领域服务、领域事件来帮助领域建模。
- 《领域驱动设计的基础知识总结》
- 领域(Doamin)本质上就是问题域,比如一个电商系统,一个论坛系统等。
- 界限上下文(Bounded Context):阐述子域之间的关系,可以简单理解成一个子系统或组件模块。
- 领域模型(Domain Model):DDD的核心是建立(用通用描述语言、工具—领域通用语言)正确的领域模型;反应业务需求的本质,包括实体和过程;其贯穿软件分析、设计、开发 的整个过程;常用表达领域模型的方式:图、代码或文字;
- 领域通用语言:领域专家、开发设计人员都能立即的语言或工具。
- 经典分层架构:用户界面/展示层、应用层、领域层、基础设施层,是四层架构模式。
- 使用的模式:
- 关联尽量少,尽量单项,尽量降低整体复杂度。
- 实体(Entity):领域中的唯一标示,一个实体的属性尽量少,少则清晰。
- 值对象(Value Object):没有唯一标识,且属性值不可变,小二简单的对象,比如Date。
- 领域服务(Domain Service): 协调多个领域对象,只有方法没有状态(不存数据);可以分为应用层服务,领域层服务、基础层服务。
- 聚合及聚合根(Aggregate,Aggregate Root):聚合定义了一组具有内聚关系的相关对象的集合;聚合根是对聚合引用的唯一元素;当修改一个聚合时,必须在事务级别;大部分领域模型中,有70%的聚合通常只有一个实体,30%只有2~3个实体;如果一个聚合只有一个实体,那么这个实体就是聚合根;如果有多个实体,那么我们可以思考聚合内哪个对象有独立存在的意义并且可以和外部直接进行交互;
- 工厂(Factory):类似于设计模式中的工厂模式。
- 仓储(Repository):持久化到DB,管理对象,且只对聚合设计仓储。
- 《领域驱动设计(DDD)实现之路》
- 聚合:比如一辆汽车(Car)包含了引擎(Engine)、车轮(Wheel)和油箱(Tank)等组件,缺一不可。
- 《领域驱动设计系列(2)浅析VO、DTO、DO、PO的概念、区别和用处》
命令查询职责分离(CQRS)
CQRS — Command Query Responsibility Seperation
- 《领域驱动设计系列 (六):CQRS》
- 核心思想:读写分离(查询和更新在不同的方法中),不同的流程只是不同的设计方式,CQ代码分离,分布式环境中会有明显体现(有冗余数据的情况下),目的是为了高性能。
- 《DDD CQRS架构和传统架构的优缺点比较》
- 最终一致的设计理念;依赖于高可用消息中间件。
- 《CQRS架构简介》
- 一个实现 CQRS 的抽象案例。
- 《深度长文:我对CQRS/EventSourcing架构的思考》
- CQRS 模式分析 + 12306 抢票案例
贫血,充血模型
- 《贫血,充血模型的解释以及一些经验》
- 失血模型:老子和儿子分别定义,相互不知道,二者实体定义中完全没有业务逻辑,通过外部Service进行关联。
- 贫血模型:老子知道儿子,儿子也知道老子;部分业务逻辑放到实体中;优点:各层单项依赖,结构清楚,易于维护;缺点:不符合OO思想,相比于充血模式,Service层较为厚重;
- 充血模型:和贫血模型类似,区别在于如何划分业务逻辑。优点:Service层比较薄,只充当Facade的角色,不和DAO打交道、复合OO思想;缺点:非单项依赖,DO和DAO之间双向依赖、和Service层的逻辑划分容易造成混乱。
- 肿胀模式:是一种极端情况,取消Service层、全部业务逻辑放在DO中;优点:符合OO思想、简化了分层;缺点:暴露信息过多、很多非DO逻辑也会强行并入DO。这种模式应该避免。
- 作者主张使用贫血模式。
Actor 模式
TODO
响应式编程
Reactor
TODO
RxJava
TODO
Vert.x
TODO
DODAF2.0
Serverless
无需过多关系服务器的服务架构理念。
- 《什么是Serverless无服务器架构?》
- Serverless 不代表出去服务器,而是去除对服务器运行状态的关心。
- Serverless 代表一思维方式的转变,从“构建一套服务在一台服务器上,对对个事件进行响应转变为构建一个为服务器,来响应一个事件”。
- Serverless 不代表某个具体的框架。
- 《如何理解Serverless?》
- 依赖于 Baas ((Mobile) Backend as a Service) 和 Faas (Functions as a service)
Service Mesh
项目管理
架构评审
重构
代码规范
代码 Review
制度还是制度! 另外,每个公司需要根据自己的需求和目标制定自己的 check list
- 《为什么你做不好 Code Review?》
- 代码 review 做的好,在于制度建设。
- 《Code Review Checklist》
- 《如何用 gitlab 做 code review》
RUP
看板管理
SCRUM
SCRUM - 争球
- 3个角色:Product Owner(PO) 产品负责人;Scrum Master(SM),推动Scrum执行;Team 开发团队。
- 3个工件:Product Backlog 产品TODOLIST,含优先级;Sprint Backlog 功能开发 TODO LIST;燃尽图;
-
五个价值观:专注、勇气、公开、承诺、尊重。
- 《敏捷其实很简单3—敏捷方法之scrum》
敏捷开发
TODO
极限编程(XP)
XP - eXtreme Programming
- 《主流敏捷开发方法:极限编程XP》
- 是一种指导开发人员的方法论。
- 4大价值:
- 沟通:鼓励口头沟通,提高效率。
- 简单:够用就好。
- 反馈:及时反馈、通知相关人。
- 勇气:提倡拥抱变化,敢于重构。
- 5个原则:快速反馈、简单性假设、逐步修改、提倡更改(小步快跑)、优质工作(保证质量的前提下保证小步快跑)。
- 5个工作:阶段性冲刺;冲刺计划会议;每日站立会议;冲刺后review;回顾会议。
结对编程
边写码,边review。能够增强代码质量、减少bug。
PDCA 循环质量管理
P——PLAN 策划,D——DO 实施,C——CHECK 检查,A——ACT 改进
FMEA管理模式
TODO
通用业务术语
TODO
技术趋势
TODO
政策、法规
法律
- 《中华人民共和国网络安全法》
- 2016年11月7日发布,自2017年6月1日起施行
- 《个人信息保护法》
- 个人信息保护法是一部保护个人信息的法律条款,现尚在制订中,2019全国两会信息安全相关提案中,有政协委员呼吁关注大数据时代隐私保护,加速立法。
- 《最高人民法院、最高人民检察院关于办理侵犯公民个人信息刑事案件适用法律若干问题的解释》
- 《解释》共十三条,自2017年6月1日起施行
- 1、对于行踪轨迹信息、通信内容、征信信息、财产信息,非法获取、出售或者提供50条以上即算“情节严重”;
- 2、对于住宿信息、通信记录、健康生理信息、交易信息等其他可能影响人身、财产安全的公民个人信息,标准则是 500条以上;
- 3、对于其他公民个人信息,标准为 5000条以上。
- 《解释》共十三条,自2017年6月1日起施行
- 《中华人民共和国电子商务法》
- 2018年8月31日,十三届全国人大常委会第五次会议表决通过《电子商务法》,自2019年1月1日起施行
- 解读电子商务法(一)什么是电商
- 解读电子商务法(二)电商经营者
- 解读电子商务法(三)电商行为规范
- 解读电子商务法(四)电商的法律关系
- 解读电子商务法(外传)电商挣钱的秘密
- 解读电子商务法(外传)电商模式
- 程序员需要知道的法律常识
- 白话法律42讲-为程序员打造的专属法律武器
严格遵守刑法253法条
我国刑法第253条之一规定:
- 国家机关或者金融、电信、交通、教育、医疗等单位的工作人员,违反国家规定,将本单位在履行职责或者提供服务过程中获得的公民个人信息,出售或者非法提供给他人,情节严重的,处3年以下有期徒刑或者拘役,并处或者单处罚金。
- 窃取或者以其他方法非法获取上述信息,情节严重的,依照前款的规定处罚。
- 单位犯前两款罪的,对单位判处罚金,并对其直接负责的主管人员和其他直接责任人员,依照各该款的规定处罚。
最高人民法院、最高人民检察院关于执行《中华人民共和国刑法》确定罪名的补充规定(四)规定:触犯刑法第253条之一第1款之规定,构成“出售、非法提供公民个人信息罪”;触犯刑法第253条之一第2款之规定,构成“非法获取公民个人信息罪”
避风港原则
“避风港”原则是指在发生著作权侵权案件时,当ISP(网络服务提供商)只提供空间服务,并不制作网页内容,如果ISP被告知侵权,则有删除的义务,否则就被视为侵权。如果侵权内容既不在ISP的服务器上存储,又没有被告知哪些内容应该删除,则ISP不承担侵权责任。 后来避风港原则也被应用在搜索引擎、网络存储、在线图书馆等方面。
架构师素质
- 《架构师画像》
- 业务理解和抽象能力
- NB的代码能力
- 全面:1. 在面对业务问题上,架构师脑海里是否会浮现出多种技术方案;2. 在做系统设计时是否考虑到了足够多的方方面面;3. 在做系统设计时是否考虑到了足够多的方方面面;
- 全局:是否考虑到了对上下游的系统的影响。
- 权衡:权衡投入产出比;优先级和节奏控制;
- 《关于架构优化和设计,架构师必须知道的事情》
- 要去考虑的细节:模块化、轻耦合、无共享架构;减少各个组件之前的依赖、注意服务之间依赖所有造成的链式失败及影响等。
- 基础设施、配置、测试、开发、运维综合考虑。
- 考虑人、团队、和组织的影响。
- 《架构师的必备素质和成长途径》
- 素质:业务理解、技术广度、技术深度、丰富经验、沟通能力、动手能力、美学素养。
- 成长路径:2年积累知识、4年积累技能和组内影响力、7年积累部门内影响力、7年以上积累跨部门影响力。
- 《架构设计师—你在哪层楼?》
- 第一层的架构师看到的只是产品本身
- 第二层的架构师不仅看到自己的产品,还看到了整体的方案
- 第三层的架构师看到的是商业价值
团队管理
TODO
招聘
资讯
行业资讯
公众号列表
TODO
博客
团队博客
个人博客
综合门户、社区
国内:
- CSDN 老牌技术社区、不必解释。
- 51cto.com
- ITeye
- 偏 Java 方向
- 博客园
- ChinaUnix
- 偏 Linux 方向
- 开源中国社区
- InfoQ
- 深度开源
- 伯乐在线
- 涵盖 IT职场、Web前端、后端、移动端、数据库等方面内容,偏技术端。
- ITPUB
- 腾讯云— 云+社区
- 阿里云— 云栖社区
- IBM DeveloperWorks
- 开发者头条
- LinkedKeeper
国外:
问答、讨论类社区
- segmentfault
- 问答+专栏
- 知乎
- stackoverflow
行业数据分析
专项网站
- 测试:
- Java:
- ImportNew
- 专注于 Java 技术分享
- HowToDoInJava
- 英文博客
- ImportNew
- 安全
- 大数据
- 其他专题网站:
- InfoQ
- 偏重于基础架构、运维方向
- DockerInfo
- 专注于 Docker 应用及咨询、教程的网站
- Linux公社
- Linux 主题社区
- InfoQ
其他类
推荐参考书
在线电子书
纸质书
更多架构方面书籍参考: awesome-java-books
开发方面
- 《阿里巴巴Java开发手册》详情
架构方面
- 《软件架构师的12项修炼:技术技能篇》详情
- 《架构之美》详情
- 《分布式服务架构》详情
- 《聊聊架构》 详情
- 《云原生应用架构实践》详情
- 《亿级流量网站架构核心技术》详情
- 《淘宝技术这十年》详情
-
《企业IT架构转型之道-中台战略思想与架构实战》 详情
- 《高可用架构(第1卷)》详情
技术管理方面
基础理论
工具方面
TODO
大数据方面
技术资源
开源资源
手册、文档、教程
国内:
- W3Cschool
- Runoob.com
- HTML 、 CSS、XML、Java、Python、PHP、设计模式等入门手册。
- Love2.io
- 很多很多中文在线电子书,是一个全新的开源技术文档分享平台。
- gitbook.cn
- 付费电子书。
- ApacheCN
- AI、大数据方面系列中文文档。
国外:
- Quick Code
- 免费在线技术教程。
- gitbook.com
- 有部分中文电子书。
- Cheatography
- Cheat Sheets 大全,单页文档网站。
- Tutorialspoint
- 知名教程网站,提供Java、Python、JS、SQL、大数据等高质量入门教程。
在线课堂
会议、活动
活动发布平台:
常用APP
找工作
工具
- 极客搜索
- 技术文章搜索引擎。
代码托管
文件服务
- 七牛
- 又拍云
综合云服务商
VPS
- Linode
- DigitalOcean
- Vultr
������������������������������������������_posts/2020-11-03-Java-垃圾回收.md��������������������������������������������������������������0000664�0001750�0001750�00000007220�14133252221�021004� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: 垃圾回收机制
subtitle: 笔记。
date: 2020-11-03
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:-
Java
java内存分为 堆 栈 方法区
-
-
堆区:
- 存储的全部是对象 ,每个对象都包含一个与之对应的class的信息。(class的目的是得到操作指令)
- jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身
- 栈区:
- 每个线程包含一个栈区 ,栈中 只保存基础数据类型的对象和自定义对象的引用(不是对象) ,对象都存放在堆区中
- 每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问 。
- 栈分为3个部分: 基本类型变量区、执行环境上下文、操作指令区(存放操作指令) 。
- 方法区:
- 又叫 静态区 ,跟堆一样, 被所有的线程共享 。方法区 包含所有的class和static变量 。
- 方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
java引用类型
- 强引用
- 即java中不同的引用,该类型即使内存不足,也不会被释放
String str = "abc"; List<String> list = new Arraylist<String>(); list.add(str); - 软引用
- 使用SoftReference类间接的引用,在内存不足时,会将其作为可回收对象释放
A a = new A(); SoftReference<A> sr = new SoftReference<A>(a);
- 使用SoftReference类间接的引用,在内存不足时,会将其作为可回收对象释放
- 弱引用
- 使用WeakReference类间接引用,GC触发时便会被回收
Object c = new Car(); //只要c还指向car object, car object就不会被回收 WeakReference<Car> weakCar = new WeakReference(Car)(car);
- 使用WeakReference类间接引用,GC触发时便会被回收
- 虚引用
- 若对象被回收时将会把虚引用加入到于对象关联的引用队列
类加载器
- 若对象被回收时将会把虚引用加入到于对象关联的引用队列
- Bootstrap(启动引导)加载器
- EXt(扩展)加载器
- APP(系统)加载器
- 自定义加载器
类的生命周期
- 加载:获取类的二进制字节流;生成方法区的运行时存储结构;在内存中生成Class对象
- 验证:确保该Class字节流符合虚拟机要求
- 准备:初始化静态变量
- 解析:将常量池的符号引用替换成直接引用
- 初始化:执行静态代码,变量赋值
- 使用
- 卸载
判定是否为垃圾的方法
- 引用计数法
- 可达性分析法:
定义:从 GC ROOT 开始搜索,不可达的对象都是可以被回收的 - GC ROOT:
1.虚拟机栈/本地方法栈中引用的对象
2.方法区中常量/静态变量引用的对象垃圾处理机制
- 标记清除法:
直接对可回收对象删除,这样的做法会产生大量内存碎片 - 标记复制法:
将内存空间划分为两部分,永远保持一部分是空的,先将存活对象复制到一侧,然后将另一侧清空,这样做内存浪费,相当于只有一半内存可用 - 标记压缩法:
将可回收对象清理后,在将存活对象移动。使其空间连续,效率较低。 - 分代回收(jvm使用的):
- 将内存分为青年代,老年代,永久代三个区。
- 对于青年代又可分为to(s1) from(s0) eden
- 将eden区,s0,s1区相结合使用标记复制法,即eden区满了(将存活对象)移动到s0区,s0区满了移动到s1区。
- 经过多代(大约7代)后将仍然存活的s1区对象移动到老年区,老年区使用复制压缩法。老年区满后使用标记复制法移动到永久区。
- 标记清除法:
_posts/2020-11-03-设计模式-设计模式.md������������������������������������������������������0000664�0001750�0001750�00000032235�14133252221�024707� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: 设计模式学习心得
subtitle: 笔记。
date: 2020-11-03
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
- 设计模式
—
Design Pattern
- 简介
- 在 1994 年,由 Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides 四人合著出版了一本名为
Design Patterns - Elements of Reusable Object-Oriented Software(中文译名:设计模式 - 可复用的面向对象软件元素)的书,
该书首次提到了软件开发中设计模式的概念。
四位作者合称 GOF(四人帮,全拼 Gang of Four)。他们所提出的设计模式主要是基于以下的面向对象设计原则。 - 对接口编程而不是对实现编程。
- 优先使用对象组合而不是继承。
以下列举3种常见的设计模式
1. 策略模式: - 体现java面向抽象,对扩展开放,对修改封闭的原则
- 策略与问题分:策略为一类,问题为一类
- 例如,一些函数的参数(sort python,java,c++均有)会在形参处保留一个function指针,该function指定了父函数进行一些操作的策略,这便是典型的策略模式
- 在 1994 年,由 Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides 四人合著出版了一本名为
- 中介者模式
- 体现java多用组合少用继承的,低耦合的设计思想
- 将具有类似属性的若干类对象之间的关系交由中介者类去维护,免去直接修改多个类的内部,以达到更新类之间关系的目的。
- 例如,Dijkstra算法和Floyd算法中用第三方对象去维护各结点之间的距离关系,这便是典型的中介者模式
- 模板方法模式
- 体现java高内聚的设计思想
- 面向算法,在抽象类中搭建算法的骨架,该抽象类中使用内部抽象成员完成了模板方法的实现细节,
正文
- 根据GOF,设计模式总共有23种,并且他们可以分为3大类,分别为:
- 创建型模式
- 工厂模式(Factory Pattern)
- 抽象工厂模式(Abstract Factory Pattern)
- 单列模式(Singleton Pattern)
- 建造者模式(Builder Pattern)
- 模型模式(Prototype Pattern)
- 结构性模式
- 适配器模式(Adapter Pattern)
- 桥接模式(Bridge Pattern)
- 过滤模式(Filter、Criteria Pattern)
- 组合模式(Composite Pattern)
- 装饰器模式(Decorator Pattern)
- 外观模式(Facade Pattern)
- 享元模式(Flyweight Pattern)
- 代理模式(Proxy Pattern)
- 行为型模式
- 责任连模式(Chain of Responsibility Pattern)
- 命令模式(Command Pattern)
- 解释器模式(Interpreter Pattern)
- 迭代器模式(Iterator Pattern)
- 中介者模式(Mediator Pattern)
- 备忘录模式(Memento Pattern)
- 观察者模式(Observer Pattern)
- 状态模式(State Pattern)
- 空对象模式(Null Object Pattern)
- 策略模式(Strategy Pattern)
- 模板模式(Template Pattern)
- 访问者模式(Visitor Pattern)
- 创建型模式
- 另外J2EE模式(Sun提供)
- J2EE模式
- MVC模式(MVC Pattern)
- 业务代表模式(Business Delegate Pattern)
- 组合实体模式(Composite Entity Pattern)
- 数据访问对象模式(Data Access Object Pattern)
- 前端控制器模式(Front Controller Pattern)
- 拦截过滤器模式(Intercepting Filter Pattern)
- 服务定位器模式(Service Locator Pattern)
- 传输对象模式(Transfer Object Pattern)
- J2EE模式
- 设计模式的六大基本原则
- 开闭原则
- 对扩展开放,对修改关闭
- 即提倡用增加代码的方式扩展程序功能,而不是用修改代码的方式
- 里氏代换原则
- 任何基类能出现的地方,子类也一定能出现,
- 即程序应该向后兼容,或者向子代兼容
- 依赖倒转原则
- #????????依赖抽象而不依赖具体
- 接口隔离原则
- 要求程序低耦合,要求接口功能不要相互依赖(从软件架构出发)
- 迪米特法则,最少知道原则
- 要求一个实体尽量少的与其他实体发生关系,使之实现高内聚(从实体程序出发)
- 合成复原原则
- 尽量使用合成或者聚合的方法编成,而不使用继承。
工厂模式
- 尽量使用合成或者聚合的方法编成,而不使用继承。
- 开闭原则
- 比如一个画图程序中可以绘制 正方形 长方形 圆形 三角形 梯形 …等 图形,他们均实现了接口 Shape{+draw():void}
如此多,具有共性使用场景(绘制时)的类,如果直接暴露给使用者,将变得难以管理
所以这里使用一个工厂类,去创建正方形 长方形等类的实例,是一个非常便于管理的方法,如果后续需要扩充类型,只需要对工厂类进行扩充即可 - 在比如,在汽车工厂中有很多型号的汽车,他们都是汽车的子类,对于获取对象可以使用工厂类的的方法,返回给定信息的汽车对象的实例。
- 程序如下:
- Shape.java 创建绘图接口
public interface Shape { void draw(); }- Rectangle.java 创建绘图接口实现类 长方形
public class Rectangle implements Shape { @Override public void draw() { System.out.println("Inside Rectangle::draw() method."); } }
- Rectangle.java 创建绘图接口实现类 长方形
- Square.java 创建绘图接口实现类 正方向
public class Square implements Shape { @Override public void draw() { System.out.println("Inside Square::draw() method."); } } - ShapeFactory.java 创建工厂类,返回给定信息的实体类
public class ShapeFactory { //使用 getShape 方法获取形状类型的对象 public Shape getShape(String shapeType){ if(shapeType == null){ return null; } if(shapeType.equalsIgnoreCase("CIRCLE")){ return new Circle(); } else if(shapeType.equalsIgnoreCase("RECTANGLE")){ return new Rectangle(); } else if(shapeType.equalsIgnoreCase("SQUARE")){ return new Square(); } return null; } }抽象工厂模式
- Shape.java 创建绘图接口
- 抽象工厂模式是工厂模式的一种扩展,即将工厂抽象化,实现生产工厂的“超级工厂”
- 在这里可以进一步理解接口和抽象类的精髓:
- 使用接口或者抽象类可以经不同的类型进行共性化,这样作的好处是对于函数,允许其返回的对象类型不再单一。
比如将工厂模式例子中的形状使用接口的方法抽象化后,便可以使用接口类型 “Shape” 去声明函数getShape,这样,getShape
函数将允许返回多种实现于 ”Shape“ 的类的对象。
同样的好处还见于形参,如果没有类的继承或者接口实现的策略,那么对应不同类型的形参的同功能方法只能使用重载的方法去实现内部函数。
相反,使用抽象类的方法去声明形参,便可以将同一个功能聚集在一个函数里,体现高内聚的思想。 - 接口是对行为的抽象,抽象类是对事物的抽象。抽象类和普通类的区别是,普通类内部不允许有抽象方法,允许实例化。而抽象类必须由子类将其抽象大方全部实现后
才能实例化。在语法层面上,他们的区别有:- 抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
- 接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
- 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
- 这里列举一个抽象类和接口使用场景的例子
//Door.java public abstract class Door{//普通门 public void open(){//开门 System.out.println("Door open"); } public void close(){//关门 System.out.println("Door close"); } } //Alarm.java public interface Alarm{//报警方法集合 public abstract void alarm(); } //Bell.java public interface Bell{//门铃方法集合 public abstract void bell(); } //SuperDoor.java public class SuperDoor extends Door implements Alarm,Bell{//有报警功能和门铃的高档防盗门 ... } public abstract class AbstractFactory{ public abstract Door getDoor {//获取门工厂 } public abstract Door getGlass {//获取玻璃工厂 } } public class DoorFactory extends AbstractFactory{ public Door getDoor(String kind){//实现玻璃工厂 if(kind.equalsIgnoreCase("superDoor")){ return new SuperDoor(); } if...; ... } public Door getGlass {//因为这里是门工厂 所以玻璃工厂可以不实现 return null; } }- 从以上了例子可以看出,用接口修饰行为 Alarm(报警) Bell(门铃)比较合理,因为接口支持多继承,适合扩展,而对于门这类事物,用抽象类封装可以对其内部进行描述(门的开闭)。
- 反过来看,如果将Door(门)声明为接口,则给门添加报警,门铃等功能就成为了与门同代的功能,这会让关系混乱
- 抽象工厂的出现将门 玻璃等工厂进一步继承,是对工厂的进一步抽象化,对于造房子即需要门工厂又需要玻璃工厂这样的使用场景,这种超级工厂的应用使得代码进一步高内聚,低耦合。
单例模式
- 使用接口或者抽象类可以经不同的类型进行共性化,这样作的好处是对于函数,允许其返回的对象类型不再单一。
- 注意:
- 单例类只能有一个实例。
- 单例类必须自己创建自己的唯一实例。
- 单例类必须给所有其他对象提供这一实例。
- 应把构造函数私有化
- 应对一个全局使用,却需要频繁创建实列的类
- 列举四种经典解决方案:
- 懒汉式:使用时再初始化实列,节省内存,但需要在初始函数处加锁,因为多线程下有可能出现多列,但是加锁后会造成效率低下,所以仅适用于无并发不加锁使用。
public class Lazy{ private Lazy(){} private static Lazy instance; public static synchronized Lazy getInstance(){ if(instance ==null){ instance= new Lazy(); return instance; }else{ return instance; } } } - 饿汉式:直接在声明时初始化,虽然浪费内存,但是线程安全,适合并发情景下使用。
public class Hungry{ private Hungry(){} private static final Hungry instance=new Hungry(); public static Hungry getInstance(){ return instance; } } - 双检锁/双重校验锁
public class Lazy{ private Lazy(){} private volatile static Lazy instance; public static Lazy getInstance(){ if(instance ==null){ synchronized(this){ if(instance ==null){ instance= new Lazy(); return instance; }else{ return instance; } } }else{ return instance; } } } - 登记式/静态内部类 对静态域使用延迟初始化,比双检锁方式优秀
public class Register{ private static class RegisterHandle{ private static final Register instance = new Register(); } private Register(){} public static final Register getInstance{ return RegisterHandle.instance; } }建造者模式
- 懒汉式:使用时再初始化实列,节省内存,但需要在初始函数处加锁,因为多线程下有可能出现多列,但是加锁后会造成效率低下,所以仅适用于无并发不加锁使用。
- 使用多个简单的对象一步一步构建成一个完整的对象,这些简单对象需要提取公共部分。
- 比如,对于一个外卖套餐而言,构成该套餐的各个事物应该是具有不同属性值的相同类别。在建造者模式中会将各种食物分类,比如肉类和蔬菜类。然后进一步对这两种分类
做进一步细节化分类,比如肉类可分为猪肉类和鸡肉类,蔬菜类可分为有机蔬菜和非有机蔬菜。如此自上往下的分类,用接口和继承的方法抽象处新的细化类。 - 最后在建造者类中可以直接调用最底层的细化类,去建造需求对象。在上边例子中的表现是使用套餐制造者类,去直接调用猪肉和有机蔬菜这种细化类去返回食物组合对象。
- 这种模式我认为,相当于在工厂模式的基础上,创建一个建造者的角色,是的该角色能返回不同的对象组合,而这些对象来源于工厂角色。上边举例中,将细化食物封装成工厂,只差一步。
_posts/2020-12-06-Pyhton-gray2energy.md�������������������������������������������������������������0000664�0001750�0001750�00000003337�14133252221�017351� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: 灰度图转热力图 subtitle: 灰度图转热力图 date: 2020-12-06 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Python —
灰度图转热力图python
- 该方法需要依赖numpy,cv2
import cv2 import numpy as np import os dirpath="/home/wangwen/pic" outpath="/home/wangwen/picout" def getfile(path, is_path=True, type="dir"): filelist = [] filelist_ = os.listdir(path) if is_path: for i in range(len(filelist_)): filelist_[i] = os.path.join(path, filelist_[i]) if type == "dir": for p in filelist_: if "." not in os.path.splitext(p)[1]: filelist.append(p) elif type == "pic": for p in filelist_: if os.path.splitext(p)[1] in [".jpg", ".jpeg", ".png", ".gif", ".bmp", ]: filelist.append(p) return filelist if __name__ == '__main__': pic_path_list=getfile(dirpath,type="pic") for pic_path in pic_path_list: image=cv2.imread(pic_path,2) #下边注释的两步为16位深度图转8位深度图的两种方法,如果输入本身为8位深度,则注释状态无需更改 #image=image/(image.max()-image.min())*256 # image=image/256 image8=image.astype(np.uint8) imagejet=cv2.applyColorMap(image8,cv2.COLORMAP_JET) picn=os.path.splitext(os.path.split(pic_path)[1])[0] cv2.imwrite(os.path.join(outpath,picn+"-jet"+".png"),imagejet) #以下位hot模式 # imagehot=cv2.applyColorMap(image8,cv2.COLORMAP_HOT) # cv2.imwrite(os.path.join(outpath,picn+"-hot"+".png"),imagehot)_posts/2020-12-1-Java-多线程.md������������������������������������������������������������������0000664�0001750�0001750�00000034272�14133252221�017744� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: 协程 线程 进程 程序
subtitle: 协程 线程 进程 程序
date: 2020-12-01
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:-
Java
协程 线程 进程 程序
-
- 协程 - 单线程内函数函数级跳转,python 可通过yield关键字 和 next(func)方法实现 也有greenlet gevent 等模块实现协程
- 携程在函数间跳转时会保留现场上下文信息,然后跳转到另外一个函数,一般跳出跳回原函数时机由用户程序控制如 greenlet ,也
可由模块通过算法判断跳出跳回时机 如gevent
- 携程在函数间跳转时会保留现场上下文信息,然后跳转到另外一个函数,一般跳出跳回原函数时机由用户程序控制如 greenlet ,也
- 线程
- 程序最小的执行的单位,一个程序可以有多个进程,并且每个进程可以有多个线程。拥有相同父进程的多个线程间共享一片内存,所
以使用多线程时无需为资源共享设计方法,但需要考虑线程安全。 - 多个线程在多核处理器上可以并行执行。
- 程序最小的执行的单位,一个程序可以有多个进程,并且每个进程可以有多个线程。拥有相同父进程的多个线程间共享一片内存,所
- 进程
- 一个程序可以创建多个进程,不同进程间资源隔离,所以如需共享资源,可以借助pip queue shareMemery socket等方法实现。多个进程
可以在多CPU机器上并行执行。
- 一个程序可以创建多个进程,不同进程间资源隔离,所以如需共享资源,可以借助pip queue shareMemery socket等方法实现。多个进程
- 程序
- 指含有指令和数据的文件
- 使用时机
- 三种方法用于对于程序内多模块在时序上有并行执行的需求的任务场景
- 一般功能高度独立的程序推荐用多进程方法,因为使用多线程,一个没处理的错误会同进程的所有线程崩溃。
- 对于高耦合性的模块,推荐使用多线程,因为多线程之间资源共享相对多进程较为简单,并且高耦合意味着要CPU频繁切换
于多个线程,相比于多进程,多线程之间的切换开销要低。 - 对于协程,一般用于单线程内,IO操作,网络请求操作等耗时,并且不需要CPU守护的程序操作的的切换,用此来提高速度。
- 总之,一个程序可以有多个进程,一个进程可以有多个线程,一个线程可以在多个协程之间切换。
java syncronized
- 该关键字可以修饰 方法名 代码块
- 如下,sFunc1的写法等加sFunc2的写法,func1的写法等价func2的写法。可见不论syncronized关键字放在什么位置,
均可用syncronized(lock){代码块;}来等价描述,为了方便讨论,后边均以该种方式进行讨论。值的注意的是this 作为lock指的是
当前实例作为临界资源,意思是类型相同的两个实例拥有不同临界资源。L1.class作为lock指的是将L1类作为临界资源,意思是
L1的所有实例共享同一个临界资源。package com.wangwen; public class L1 { public static synchronized void sFunc1(){ System.out.println("im sFunc1"); } public static void sFunc2(){ synchronized (L1.class){ System.out.println("im sFunc2"); } } public synchronized void func1(){ System.out.println("im func1"); } public void func2() { synchronized (this) { System.out.println("im func2"); } } } - 使用syncronized关键字目的是锁定临界资源,使得多个线程在并发运行时,对于拥有临界资源的线程运行,没有临界资源的线程阻塞。而对于线程而言,lock便是临界资源。
- 如果一段程序没有syncronized修饰,则该线程判定其没有临界资源(即使程序内部使用了其他线程中修饰过的临界资源)。如下,虽然在s1方法和s2方法中均有使用成员lockResource,且s1方法将lockResource声明为
临界资源,但是由于s2方法并没有用synchronized声明lockResource,所以线程b运行时判定lockResource为非临界资源,即不会阻塞s2方法的运行,造成不安全访问lockResource。OUTPUT为运行结果。问题出在s2为线程
不安全的方法,修改方法为在s2中使用synchronized声明lockResource 为临界资源。package com.wangwen; public class L2 { byte[] lockResource = new byte[1]; public void s1() throws InterruptedException { synchronized(lockResource) { for (int i = 0; i < 10; i++) { lockResource[0]=(byte) 1; System.out.println(Thread.currentThread()+" im s1 lockResource:"+lockResource[0]); Thread.sleep(200); L1.class.getClass(); } } } public void s2() throws InterruptedException { for (int i = 0; i < 10; i++) { lockResource[0]=(byte) 2; System.out.println(Thread.currentThread()+" im s2 lockResource:"+lockResource[0]); Thread.sleep(200); } } public static void main(String[] args) throws InterruptedException { final L2 l = new L2(); Thread a=new Thread(()->{ try { l.s1(); } catch (InterruptedException e) { e.printStackTrace(); } },"Thread a"); Thread b=new Thread(()->{ try { l.s2(); } catch (InterruptedException e) { e.printStackTrace(); } },"Thread b"); a.start(); b.start(); a.join(); b.join(); } } /*OUTPUT Thread[Thread a,5,main] im s1 lockResource:2 Thread[Thread b,5,main] im s2 lockResource:2 Thread[Thread a,5,main] im s1 lockResource:1 Thread[Thread b,5,main] im s2 lockResource:2 Thread[Thread a,5,main] im s1 lockResource:1 Thread[Thread b,5,main] im s2 lockResource:2 Thread[Thread b,5,main] im s2 lockResource:1 Thread[Thread a,5,main] im s1 lockResource:1 Thread[Thread b,5,main] im s2 lockResource:1 Thread[Thread a,5,main] im s1 lockResource:1 Thread[Thread b,5,main] im s2 lockResource:1 Thread[Thread a,5,main] im s1 lockResource:1 Thread[Thread a,5,main] im s1 lockResource:2 Thread[Thread b,5,main] im s2 lockResource:2 Thread[Thread b,5,main] im s2 lockResource:1 Thread[Thread a,5,main] im s1 lockResource:1 Thread[Thread b,5,main] im s2 lockResource:2 Thread[Thread a,5,main] im s1 lockResource:2 Thread[Thread b,5,main] im s2 lockResource:2 Thread[Thread a,5,main] im s1 lockResource:1 */ - 只要临界资源的地址不同,线程便会认为其是不同的临界资源,不论这些临界资源是不是包含关系。
- 如下,逻辑上ss锁定的是类的所有实例,s1锁定的是当前实例,s2锁定的是当前实例,他们具有包含关系。上面这句话汉让人难以理解,并且
有明显的错误。实际上ss方法是将L.class作为临界资源,所有实例共用同一个锁,即L.class。s1将当前实例作为临界资源,并且线程a,b,c使用的是
同一个实例l。s2将L实例中的lockResource属性作为临界资源,线程a,b,c使用的是同一个l,lockResource属性在内存上自然也是相同的。所以严格的说只有临界资源l和lockResource是包含关系。
但是对于线程,将判定l和b是完全不同的两个临界资源,所以线程a,b,c可以并行。package com.wangwen; public class L { byte[] lockResource = new byte[1]; public static synchronized void ss() throws InterruptedException { for (int i = 0; i < 5; i++) { System.out.println(Thread.currentThread() + " im ss"); Thread.sleep(200); } } public synchronized void s1() throws InterruptedException { for (int i = 0; i < 5; i++) { System.out.println(Thread.currentThread() + " im s1"); Thread.sleep(200); } } public void s2() throws InterruptedException { synchronized (lockResource) { for (int i = 0; i < 5; i++) { System.out.println(Thread.currentThread() + " im s2"); Thread.sleep(200); } } } public static void main(String[] args) throws InterruptedException { final L l = new L(); Thread a = new Thread(() -> { try { l.s1(); } catch (InterruptedException e) { e.printStackTrace(); } }, "Thread a"); Thread b = new Thread(() -> { try { l.s2(); } catch (InterruptedException e) { e.printStackTrace(); } }, "Thread b"); Thread c = new Thread(() -> { try { L.ss(); } catch (InterruptedException e) { e.printStackTrace(); } }, "Thread c"); a.start(); b.start(); c.start(); a.join(); b.join(); c.join(); } } /*OUTPUT Thread[Thread b,5,main] im s2 Thread[Thread c,5,main] im ss Thread[Thread a,5,main] im s1 Thread[Thread b,5,main] im s2 Thread[Thread c,5,main] im ss Thread[Thread a,5,main] im s1 Thread[Thread b,5,main] im s2 Thread[Thread c,5,main] im ss Thread[Thread a,5,main] im s1 Thread[Thread b,5,main] im s2 Thread[Thread c,5,main] im ss Thread[Thread a,5,main] im s1 Thread[Thread b,5,main] im s2 Thread[Thread a,5,main] im s1 Thread[Thread c,5,main] im ss */ - 上边列举了3个反列,他们足以说明:线程是否会阻塞,由并行的多个线程是否声明的是同一个临界资源,下边写一个正例:
- 正例中s1,s2,ss声明的是同一个临界资源,所以会阻塞运行。
package com.wangwen; public class L3 { static byte[] lockResource = new byte[1]; public static void ss() throws InterruptedException { synchronized(lockResource) { lockResource[0]=(byte) 1; for (int i = 0; i < 5; i++) { System.out.println(Thread.currentThread() + " im ss lockResource:"+lockResource[0]); Thread.sleep(200); } } } public void s1() throws InterruptedException { synchronized(lockResource) { lockResource[0]=(byte) 2; for (int i = 0; i < 5; i++) { System.out.println(Thread.currentThread() + " im s1 lockResource:"+lockResource[0]); Thread.sleep(200); } } } public void s2() throws InterruptedException { synchronized (lockResource) { lockResource[0]=(byte) 3; for (int i = 0; i < 5; i++) { System.out.println(Thread.currentThread() + " im s2 lockResource:"+lockResource[0]); Thread.sleep(200); } } } public static void main(String[] args) throws InterruptedException { final L3 l = new L3(); Thread a = new Thread(() -> { try { l.s1(); } catch (InterruptedException e) { e.printStackTrace(); } }, "Thread a"); Thread b = new Thread(() -> { try { l.s2(); } catch (InterruptedException e) { e.printStackTrace(); } }, "Thread b"); Thread c = new Thread(() -> { try { L3.ss(); } catch (InterruptedException e) { e.printStackTrace(); } }, "Thread c"); a.start(); b.start(); c.start(); a.join(); b.join(); c.join(); } } /*OUTPUT Thread[Thread a,5,main] im s1 lockResource:2 Thread[Thread a,5,main] im s1 lockResource:2 Thread[Thread a,5,main] im s1 lockResource:2 Thread[Thread a,5,main] im s1 lockResource:2 Thread[Thread a,5,main] im s1 lockResource:2 Thread[Thread c,5,main] im ss lockResource:1 Thread[Thread c,5,main] im ss lockResource:1 Thread[Thread c,5,main] im ss lockResource:1 Thread[Thread c,5,main] im ss lockResource:1 Thread[Thread c,5,main] im ss lockResource:1 Thread[Thread b,5,main] im s2 lockResource:3 Thread[Thread b,5,main] im s2 lockResource:3 Thread[Thread b,5,main] im s2 lockResource:3 Thread[Thread b,5,main] im s2 lockResource:3 Thread[Thread b,5,main] im s2 lockResource:3 */
python 协程模块greenlet example
from greenlet import greenlet
import time
def task_1():
while True:
print("--This is task 1!--")
g2.switch() # 切换到g2中运行
time.sleep(0.5)
def task_2():
while True:
print("--This is task 2!--")
g1.switch() # 切换到g1中运行
time.sleep(0.5)
if __name__ == "__main__":
g1 = greenlet(task_1) # 定义greenlet对象
g2 = greenlet(task_2)
g1.switch() # 切换到g1中运行
- python 协程模块gevent example
```python
import gevent
def task_1(num):
for i in range(num):
print(gevent.getcurrent(), i)
gevent.sleep(1) # 模拟一个耗时操作,注意不能使用time模块的sleep
def task_2(num):
for i in range(num):
print(gevent.getcurrent(), i)
gevent.sleep(3)
def task_3(num):
for i in range(num):
print(gevent.getcurrent(), i)
gevent.sleep(6)
if name == “main”:
g1 = gevent.spawn(task_1, 5) # 创建协程
g2 = gevent.spawn(task_2, 5)
g3 = gevent.spawn(task_3, 5)
g1.join() # 等待协程运行完毕
g2.join()
g3.join() ```
_posts/2020-12-20-Linux-Linux学习笔记.md��������������������������������������������������������0000664�0001750�0001750�00000061333�14133773003�022374� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: Linux学习笔记
subtitle: Ubuntu学习笔记
date: 2020-12-02
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
- Linux
—
目录
环境变量
- /etc/profile
- 此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行.并从/etc/profile.d目录的配置文件中搜集shell的设置.
所以如果你有对/etc/profile有修改的话必须得重启你的修改才会生效,此修改对每个用户都生效。
- 此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行.并从/etc/profile.d目录的配置文件中搜集shell的设置.
- /etc/bashrc或/etc/bash.bashrc
- :为每一个运行bash shell的用户执行此文件.当bash shell被打开时,该文件被读取.如果你想对所有的使用bash的用户修改某个配置并
在以后打开的bash都生效的话可以修改这个文件,修改这个文件不用重启,重新打开一个bash即可生效。
- :为每一个运行bash shell的用户执行此文件.当bash shell被打开时,该文件被读取.如果你想对所有的使用bash的用户修改某个配置并
- ~/.bash_profile或~/.profile
- 每个用户都可使用该文件输入专用于当前用户使用的shell信息,当用户登录时,该文件仅仅执行一次!默认情况下,他设置一些环境变量,执行用户的.bashrc文件.
- ~/.bashrc
- 该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell时,该文件被读取.
-
set,env,export
命令 说明 set 用来显示本地变量, 环境变量 env 用来显示环境变量 export 用来显示和设置环境变量,声明的变量可以被子shell继承,直接声明的变量则不行
标准输出和错误输出
- command 1 > fielname 把把标准输出重定向到一个文件中
- command > filename 2>&1 把把标准输出和标准错误一起重定向到一个文件中
常用命令
- ctrl-c: ( kill foreground process ) 发送 SIGINT 信号给前台进程组中的所有进程,强制终止程序的执行;
- ctrl-z: ( suspend foreground process ) 发送 SIGTSTP 信号给前台进程组中的所有进程,常用于挂起一个进程
- ctrl-d: 一个特殊的二进制值,表示 EOF,作用相当于在终端中输入exit后回车;
- ctrl-l:清屏幕
- clear:清除屏幕(与ctrl-l 效果不同)
- ctrl-s 中断控制台输出
- ctrl-q 恢复控制台输出
- jobs:列出后台运行序列号 (ctrl-z 挂起 bg)
- nohub:不挂断地运行命令
- &: 后台运行命令
- fg %num:将挂起的任务放在前台执行
- bg %num:将挂起的任务放在后台执行
定时运行-crontab
- crontab [-u username] //省略用户表表示操作当前用户的crontab
-e (编辑工作表)
-l (列出工作表里的命令)
-r (删除工作作) -
格式:
minute hour day month week command
# For details see man 4 crontabs
# Example of job definition:
.———————————- minute (0 - 59) 表示分钟
| .——————————- hour (0 - 23) 表示小时
| | .—————————- day of month (1 - 31) 表示日期
| | | .————————- month (1 - 12) OR jan,feb,mar,apr … 表示月份
| | | | .———————- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat 表示星期(0 或 7 表示星期天)
| | | | | .——————- username 以哪个用户来执行
| | | | | | .—— command 要执行的命令,可以是系统命令,也可以是自己编写的脚本文件
| | | | | | |
* * * * * user-name command to be executed -
格式实例:
命令 说明 */1 * * * * service httpd restart 每一分钟 重启httpd服务 每一分钟 重启httpd服务 */1 * * * * service httpd restart 每一分钟 重启httpd服务 0 */1 * * * service httpd restart 每一小时 重启httpd服务 30 21 * * * service httpd restart 每天 21:30 分 重启httpd服务 26 4 1,5,23,28 * * service httpd restart 每月的1号,5号 23 号 28 号 的4点26分,重启httpd服务 26 4 1-21 * * service httpd restart 每月的1号到21号 的4点26分,重启httpd服务 */2 * * * * service httpd restart 每隔两分钟 执行,偶数分钟 重启httpd服务 1-59/2 * * * * service httpd restart 每隔两分钟 执行,奇数 重启httpd服务 0 23-7/1 * * * service httpd restart 每天的晚上11点到早上7点 每隔一个小时 重启httpd服务 0,30 18-23 * * * service httpd restart 每天18点到23点 每隔30分钟 重启httpd服务 0-59/30 18-23 * * * service httpd restart 每天18点到23点 每隔30分钟 重启httpd服务 59 1 1-7 4 * test ‘date +\%w’ -eq 0 && /root/a.sh 四月的第一个星期日 01:59 分运行脚本 /root/a.sh ,命令中的 test是判断,%w是数字的星期几
系统服务工具systemd
- 说明
- Systemd并不是一个命令,而是一组命令,涉及到系统管理的方方面面。systemctl是Systemd 的主命令,用于管理系统。
传统命令init、poweroff、halt、reboot都成为systemctl的软链接
切换至紧急救援模式:
systemctl rescue
切换至emergency(紧急)模式:
systemctl emergency
CPU停止工作:
systemctl halt
挂起系统:睡眠模式(也叫挂起suspend),把信息保存到内存中,断电数据丢失,但是恢复时较快
systemctl suspend
CentOS 7 引导顺序
UEFI或BIOS初始化,运行POST开机自检
选择启动设备
引导装载程序,centos7是grub2
加载装载程序的配置文件:/etc/grub.d/ /etc/default/grub /boot/grub2/grub.cfg
加载initramfs驱动模块
加载内核选项
内核初始化,Centos7使用systemd代替init
执行initrd.target所有单元,包括挂载/etc/fstab
从initramfs根文件系统切换到磁盘根目录
systemd执行默认target配置,配置文件/etc/systemd/default.target /etc/systemd/system/
systemd执行sysinit.target初始化系统及basic.target准备操作系统
systemd启动multi-user.target下的本机与服务器服务
systemd执行multi-user.target下的/etc/rc.d/rc.local
systemd执行multi-user.target下的getty.target及登入服务
systemd执行graphical需要的服务 - 支持systemd的软件配置文件路径一般为“/usr/lib/systemd/system/”
- 开机启动时,systemd只执行/etc/systemd/system/下的配置文件
- Systemd并不是一个命令,而是一组命令,涉及到系统管理的方方面面。systemctl是Systemd 的主命令,用于管理系统。
- 管理命令
- sudo systemctl start name.service//启动服务
- sudo systemctl stop name.service//停止服务
- sudo systemctl restart name.service//重启服务
- sudo systemctl status name.service//列出服务状态
- sudo systemctl kill name.service//向服务进程发送kill信号
- sudo systemctl enable name.service//设置服务开机自启动
实质是在”/usr/lib/systemd/system/“和“/etc/systemd/system/”两个目录之间建立符号链接关系 - sudo systemctl disable name.service//设置服务取消开机自启动
- sudo systemctl reload name.service//重载服务配置
- sudo systemctl mask name.service//禁止设定为开机自启
- sudo systemctl unmask name.service//取消禁止设定为开机自启
- sudo systemctl daemon-reload //通知systemd更新(扫描)service配置文件
- 状态命令
- systemctl is-active name.service
- systemctl is-failed name.service
- systemctl is-enabled name.service
- systemctl list-units -t service//查看已经激活的服务
- systemctl list-units -t service -a//查看所有服务
- systemctl list-units -t service –failed//查看失败的所有服务
- 服务列表
laowng@laowng-ThinkCentre-M8600t-N000:~$ sudo systemctl list-units -t service --all UNIT LOAD ACTIVE SUB DESCRIPTION accounts-daemon.service loaded active running Accounts Service acpid.service loaded active running ACPI event daemon alsa-restore.service loaded active exited Save/Restore Sound Card S alsa-state.service loaded inactive dead Manage Sound Card State ( anacron.service loaded inactive dead Run anacron jobs apache2.service loaded active running The Apache HTTP Server- service类型的unit状态:
- loaded:Unit配置文件已处理
- active(running):一次或多次持续处理的运行
- active(exited):成功完成一次性的配置
- active(waiting):运行中,等待一个事件
- inactive(dead):不运行
- 服务状态
laowng@laowng-ThinkCentre-M8600t-N000:~$ sudo service mysql status ● mysql.service - MySQL Community Server Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: en Active: active (running) since Tue 2021-10-12 22:23:37 CST; 3 days ago Process: 2046 ExecStart=/usr/sbin/mysqld --daemonize --pid-file=/run/mysqld/my Process: 1600 ExecStartPre=/usr/share/mysql/mysql-systemd-start pre (code=exit Main PID: 2048 (mysqld) Tasks: 28 (limit: 4915) CGroup: /system.slice/mysql.service └─2048 /usr/sbin/mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid 10月 12 22:23:17 laowng-ThinkCentre-M8600t-N000 systemd[1]: Starting MySQL Comm 10月 12 22:23:37 laowng-ThinkCentre-M8600t-N000 systemd[1]: Started MySQL Commu- Loaded行:配置文件的位置,是否设为开机启动
- Active行:表示正在运行
- Main PID行:主进程ID
- Tasks行:由应用本身(这里是 mysql )提供的软件当前状态
- CGroup块:应用的所有子进程
- 日志块:应用的日志
- 类型
- service:
文件扩展名为.service, 用于定义系统服务
代表一个后台服务进程,比如mysqld。这是最常用的一类。 -
socket:
文件扩展名为.socket, 用于标识进程间通信用的socket文件,也可在系统启动时,延迟启动服务,实现按需启动
此类配置单元封装系统和互联网中的一个套接字 。当下,systemd支持流式、数据报和连续包的AF_INET、AF_INET6、AF_UNIX socket。每一个套接字配置单元都有一个相应的服务配置单元。相应的服务在第一个”连接”进入套接字时就会启动(例如:nscd.socket 在有新连接后便启动 nscd.service)。 -
device:
文件扩展名为.device, 用于定义内核识别的设备
此类配置单元封装一个存在于 Linux 设备树中的设备。每一个使用 udev 规则标记的设备都将会在 systemd 中作为一个设备配置单元出现。 -
mount:
文件扩展名为.mount, 定义文件系统挂载点
此类配置单元封装文件系统结构层次中的一个挂载点。Systemd 将对这个挂载点进行监控和管理。比如可以在启动时自动将其挂载;可以在某些条件下自动卸载。Systemd 会将/etc/fstab 中的条目都转换为挂载点,并在开机时处理。 -
automount:
文件扩展名为.automount,文件系统的自动挂载点
此类配置单元封装系统结构层次中的一个自挂载点。每一个自挂载配置单元对应一个挂载配置单元 ,当该自动挂载点被访问时,systemd 执行挂载点中定义的挂载行为。 -
swap:
文件扩展名为.swap, 用于标识swap设备
和挂载配置单元类似,交换配置单元用来管理交换分区。用户可以用交换配置单元来定义系统中的交换分区,可以让这些交换分区在启动时被激活。 -
target :
文件扩展名为.target,用于模拟实现“运行级别”
此类配置单元为其他配置单元进行逻辑分组。它们本身实际上并不做什么,只是引用其他配置单元而已。这样便可以对配置单元做一个统一的控制。这样就可以实现大家都已经非常熟悉的运行级别概念。比如想让系统进入图形化模式,需要运行许多服务和配置命令,这些操作都由一个个配置单元表示,将所有这些配置单元组合为一个目标(target),就表示需要将这些配置单元全部执行一遍以便进入目标所代表的系统运行状态。 (例如:multi-user.target 相当于在传统使用 SysV 的系统中运行级别 5) -
timer:
文件扩展名为.timer
定时器配置单元用来定时触发用户定义的操作,这类配置单元取代了 atd、crond 等传统的定时服务。 -
snapshot:
文件扩展名为.snapshot, 管理系统快照
与 target 配置单元相似,快照是一组配置单元。它保存了系统当前的运行状态。 -
path:
文件扩展名为.path,用于定义文件系统中的一个文件或目录使用,常用于当文件系统变化时,延迟激活服务,如:spool 目录
定义了可以被基于路径的触发激活所使用的路径。默认情况下,当路径到了指定的状态(切换到了指定的路径),一个同名的.service文件将会启用。这里是采用inotify去监控路径的改变 -
slice:
文件扩展名为.slice:与Linux的CGroup相关。其名称反应了其在cgroup树的层次。默认情况下,单元依据其类型的不同被放置在一定的slice里面。 - scope:
文件扩展名为.scope:Scope单元由systemd接收到总线接口的信息而自动生成。这些Scope单元用于管理由外部创建的系统进程(非Systemd 启动的外部进程)。
- service:
- service-unit
- 这里列举sshd服务的配置文件
laowng@laowng-ThinkCentre-M8600t-N000:~$ sudo systemctl cat sshd # /lib/systemd/system/ssh.service [Unit] Description=OpenBSD Secure Shell server After=network.target auditd.service ConditionPathExists=!/etc/ssh/sshd_not_to_be_run [Service] EnvironmentFile=-/etc/default/ssh ExecStartPre=/usr/sbin/sshd -t ExecStart=/usr/sbin/sshd -D $SSHD_OPTS ExecReload=/usr/sbin/sshd -t ExecReload=/bin/kill -HUP $MAINPID KillMode=process Restart=on-failure RestartPreventExitStatus=255 Type=notify RuntimeDirectory=sshd RuntimeDirectoryMode=0755 [Install] WantedBy=multi-user.target Alias=sshd.service - Unit(定义与Unit类型无关的通用选项;用于提供unit的描述信息、unit行为及依赖关系等)
- Description:描述信息
- Documentation:文档地址
- After:表示当前Unit应该在network.target auditd.service服务之后启动
- Before: 表示当前Unit应该在那些Unit之前启动(上述文件无)
- Wants:若依赖关系,如果指定Unit没有运行,不应影响当前Unit继续执行
- Requires:强依赖关系,如果指定Unit没有运行本Unit会启动失败
- BindsTo:与Requires类似,它指定的Unit如果退出,会导致当前Unit停止运行
- Conflicts:这里指定的Unit不能与当前Unit同时运行
- Condition:当前Unit运行必须满足的条件,否则不会运行
- Assert:当前Unit运行必须满足的条件,否则会报启动失败
- ConditionPathExists:必须存在指定路径才运行(路径前加!表示不存在)
- Before 和 After只涉及启动顺序,不涉及依赖关系;Wants字段与Requires字段只涉及依赖关系,与启动顺序无关,默认情况下是同时启动的
- Service(与特定类型相关的专用选项;只有Service类型的Unit才有这个区块)
- Type:定义启动时的进程行为。它有以下几种值。
- Type=simple:默认值,ExecStart字段启动的进程为主进程
- Type=forking:ExecStart字段将以fork()方式启动(从父进程创建子进程),此时父进程将会退出,子进程成为主进程
- Type=oneshot:类似于simple,但只执行一次,Systemd 会等它执行完,才启动其他服务
- Type=dbus:类似于simple,但会等待 D-Bus信号后启动(通过D-Bus启动)
- Type=notify:类似于simple,当前服务启动完毕后会发通知信号给Systemd,然后Systemd再启动其他服务
- Type=idle:类似于simple,但是要等到其他任务都执行完,才会启动该服务。一种使用场合是为让该服务的输出,不与其他服务的输出相混合
- RemainAfterExit:字段设为yes,表示进程退出以后,服务仍然保持执行(配合Type=oneshot使用)
- ExecStart:启动当前服务的命令
- ExecStartPre:启动当前服务之前执行的命令
- ExecStartPost:启动当前服务之后执行的命令
- ExecReload:重启当前服务时执行的命令
- ExecStop:停止当前服务时执行的命令
- ExecStopPost:停止当其服务之后执行的命令
- RestartSec:自动重启当前服务间隔的秒数
- Restart:定义何种情况Systemd会自动重启当前服务,可能的值包括always(总是重启)、on-success、on-failure、on-abnormal、on-abort、on-watchdog
- no(默认值):退出后不会重启
- on-success:只有正常退出时(退出状态码为0),才会重启
- on-failure:非正常退出时(退出状态码非0),包括被信号终止和超时,才会重启
- on-abnormal:只有被信号终止和超时,才会重启
- on-abort:只有在收到没有捕捉到的信号终止时,才会重启
- on-watchdog:超时退出,才会重启
- always:不管是什么退出原因,总是重启
- RestartPreventExitStatus:当符合某些退出状态时不要进行重启
- TimeoutSec:定义Systemd停止当前服务之前等待的秒数
- KillMode:systemctl kill时执行的操作:
- control-group(默认值):当前控制组里面的所有子进程,都会被杀掉
- process:只杀主进程
- mixed:主进程将收到 SIGTERM 信号,子进程收到 SIGKILL 信号
- none:没有进程会被杀掉,只是执行服务的 stop 命令
- Environment:指定环境变量
- EnvironmentFile:指定当前服务的环境参数文件。该文件内部的key=value键值对,可以用$key的形式,在当前配置文件中获取
- 所有的启动设置之前,都可以加上一个连词号(-),表示”抑制错误”,即发生错误的时候,不影响其他命令的执行
- Type:定义启动时的进程行为。它有以下几种值。
- Install(定义如何启动,以及是否开机启动)
- WantedBy:它的值是一个或多个Target,当前Unit激活时(enable)符号链接会放入/etc/systemd/system目录下面以Target名+.wants后缀构成的子目录中
Target的含义是服务组,表示一组服务。WantedBy=multi-user.target指的是,sshd 所在的 Target 是multi-user.target。
这个设置非常重要,因为执行systemctl enable sshd.service命令时,sshd.service的一个符号链接,就会放在/etc/systemd/system目录下面的multi-user.target.wants子目录之中。 - RequiredBy:它的值是一个或多个Target,当前Unit激活时,符号链接会放入/etc/systemd/system目录下面以Target名+.required后缀构成的子目录中
- Alias:当前Unit可用于启动的别名
- Also:当前Unit激活(enable)时,会被同时激活的其它Unit
- WantedBy:它的值是一个或多个Target,当前Unit激活时(enable)符号链接会放入/etc/systemd/system目录下面以Target名+.wants后缀构成的子目录中
- 这里列举sshd服务的配置文件
- 这里展示一个测试的laowng.serice
- /lib/systemd/system/laowng.service(ubuntu18.04 服务位置在/lib)
[Unit] Description=laowng de test service After=network.target [Service] ExecStart=/home/laowng/bin/test.sh ExecReload=/bin/kill -HUP $MAINPID KillMode=control-group Restart=on-failure Type=forking [Install] WantedBy=multi-user.target Alias=laowng.service - test.sh
#/home/laowng/bin/test.sh #!/bin/bash nohup /home/laowng/bin/test.service >>test.log & - test.service
#!/bin/bash date >>/home/wangwen/bin/test.log sleep 5s date >>/home/wangwen/bin/test.log sleep 60s date >>/home/wangwen/bin/test.log sleep 120s date >>/home/wangwen/bin/test.log
- /lib/systemd/system/laowng.service(ubuntu18.04 服务位置在/lib)
-
target-unit
启动计算机的时候,需要启动大量的Unit。如果每一次启动,都要一一写明本次启动需要哪些Unit,显然非常不方便。Systemd的解决方案就是 Target。简单说,Target就是一个Unit 组,包含许多相关的Unit。启动某个Target的时候,Systemd就会启动里面所有的 Unit。从这个意义上说,Target 这个概念类似于”状态点”,启动某个 Target 就好比启动到某种状态。
传统的init启动模式里面,有RunLevel的概念,跟Target的作用很类似。不同的是RunLevel 是互斥的,不可能多个 RunLevel 同时启动,但是多个 Target可以同时启动。
-
target类型unit配置文件:/usr/lib/systemd/system/*.target
-
Target与传统RunLevel 的对应关系如下:
Traditional runlevel New target name Symbolically linked to… Runlevel 0 runlevel0.target -> poweroff.target 关机 Runlevel 1 runlevel1.target -> rescue.target 单用户模式或者救援模式 Runlevel 2 runlevel2.target -> multi-user.target Runlevel 3 runlevel3.target -> multi-user.target 正常多用户命令行模式 Runlevel 4 runlevel4.target -> multi-user.target Runlevel 5 runlevel5.target -> graphical.target 正常多用户图形模式 Runlevel 6 runlevel6.target -> reboot.target 重启 -
配置文件
wangwen@wangwen-ThinkCentre-M8600t-N000:~$ sudo systemctl cat multi-user.target # /lib/systemd/system/multi-user.target # SPDX-License-Identifier: LGPL-2.1+ # # This file is part of systemd. # # systemd is free software; you can redistribute it and/or modify it # under the terms of the GNU Lesser General Public License as published by # the Free Software Foundation; either version 2.1 of the License, or # (at your option) any later version. [Unit] Description=Multi-User System Documentation=man:systemd.special(7) Requires=basic.target Conflicts=rescue.service rescue.target After=basic.target rescue.service rescue.target AllowIsolate=yes
-
-
后记
有些程序不建议使用root权限执行,在脚本中可以使用“sudo -u username 命令”的方式执行
代理
用tsocks和proxychains代理Linux下所有软件
_posts/2020-12-2-Java-引用传递.md���������������������������������������������������������������0000664�0001750�0001750�00000013715�14133252221�020733� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: 引用传递和值传递
subtitle: 引用,值
date: 2020-12-02
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
- Java
—
引用传递和值传递
- 概述
- 引用传递和值传递是程序在函数的入口处或者对于参数传递的两种方式
- 引用传递
- 引用传递指的是传递给函数入口的是参数的指针(内存地址),所以对于函数对于参数的操作效果会在函数结束后仍然保留。
- 对于java python 这些没有指针概念的语言,对于指针的操作对程序员是透明的。而对于C++或者C,对于指针的操作是透明的
- 值传递
- 值传递指的是传递给函数入口的是参数的一个副本,或者说至少在效果上是这样的(python实现机制不同)。
- python java c++ 差异
- 对于java,所有的形参的传递均是新建一个引用(指针),然后将这个引用指向形参的指。这造成对于基本类型(boolean char byte short int long float double )这些基本类型,形式上是值传递,对于非基本类型
表现为引用传递。但是这种引用传递无法影响到外部指针的指向,C++是可以改变这种指向的。如下,changeValue1改变var外部指向失败,changeValue2改变var内部属性成功。
//Var.java package com.wangwen; public class Var { public int value; } //Test.java package com.wangwen; public class Test { public void changeValue1(Var var){ Var var1 = new Var(); var1.value=20; var=var1; } public void changeValue2(Var var){ var.value=20; } @org.junit.Test public void test() throws InterruptedException { Var var = new Var(); var.value=10; System.out.println(var.value); changeValue1(var);//更改外部引用指向 System.out.println(var.value); changeValue2(var);//更改实列内部属性 System.out.println(var.value); } } /*OUTPUT 10 10 20 */- 对于C++,其所有的数据类型,传递方式由程序员是否使用 & *决定
- 对于python,其效果于java相同,解释上存在差异。其数据分可变(自定义类 list dict )和不可变类型(bool int float char str tuble)。对于不可变类型,python解释器采用值传递,对于可变类型,反之。
数据的引用传递,python解释器会对原参数取一个别名,对于该别名的操作会影响到原参数。
对于值传递,效果上与java相同,但是python解释器不会去拷贝参数,而是新建一个引用,并让该引用和原参数指向同一个值,所以,对参数的操作实际是让新建的变量名指向新的操作结果。
这样对于新变量名的操作不会影响到原参数,起到与java值传递相同的效果。
之所以要与java区分解释,是因为python不存在基本类型的概念,java中的节本类型外暴露任何方法,这种类型与被编译后类型一一对应。仍然而python,其不可变类型仍然对外暴露一些方法(如hex,real),可见这种类型解释运行时会被拆分成其他类型,
但是不可变类型的内部值是不可被写的(比如 a=1; a.real=2; 会报 AttributeError: attribute ‘real’ of ‘int’ objects is not writable)。所以只能说效果上一致,原理上不同。
- 对于java,所有的形参的传递均是新建一个引用(指针),然后将这个引用指向形参的指。这造成对于基本类型(boolean char byte short int long float double )这些基本类型,形式上是值传递,对于非基本类型
java中“==”与”equals”
- ==用于判定两个对象内存地址是否相等 euqals用于判定两个相同对象值是否相等
- 对于java,基本类型 long int short byte char boolean 这6中类型 外加 不使用new String类型均实现了常量池技术,即相同值的引用指向相同地址,float和double没有实现常量池技术。
所以多个声明的double或者float内存地址永远不相等,但是对于这两两种类型的==,jvm默认比较的是值,而不是内存地址,所以有如下OUTPUT输出,在a,b两个变量内存地址不同的情况下a==b输出true - 对于Long Integer Short Byte Char Boolean的运算操作(+,-,*,/,//,%)默认会使用拆箱操作,将他们转换为基本类型,然后运算。
@Test public void test() throws InterruptedException { double a= 1.; double b= 1.; System.out.println(a==b); System.out.println(System.identityHashCode(a)); System.out.println(System.identityHashCode(b)); } /*OUTPUT true 729864207 984849465 */ - 如下,虽然equals看起来仍然调用的是“==”,但是在调用”==“调用之前,程序段先将装饰类型通过intValue(),floatToIntBits(value)等方法
将比较对象转换成了基本类型,由于常量池技术的的存在(float类除外,folat类和double类==在底层比较的便是值,jvm1.8验证),这些变量实际的内存地址也相同。//复制于Integer类 public boolean equals(Object obj) { if (obj instanceof Integer) { return value == ((Integer)obj).intValue(); } return false; } //复制于Float类 public boolean equals(Object obj) { return (obj instanceof Float) && (floatToIntBits(((Float)obj).value) == floatToIntBits(value)); } //复制于String类 public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String aString = (String)anObject; if (!COMPACT_STRINGS || this.coder == aString.coder) { return StringLatin1.equals(value, aString.value); } } return false; }_posts/2020-12-2-Linux-Docker.md��������������������������������������������������������������������0000664�0001750�0001750�00000011106�14133252221�016045� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: Docker笔记 subtitle: Docker笔记 date: 2020-12-02 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags:
-
Linux
##目录
-
- Docker载入载出
- Docker网络模式
Docker载入载出
镜像导入导出
- 导出
shell script docker save -o 路径/目标名.tar 镜像名[如 nginx:latest] - 导入
shell script docker load -i 路径/目标名.tar容器导入导出
- 导出
shell script docker export -o 路径/目标名.tar 容器名[如 abc123] - 导入
```shell script
docker import 路径/目标名.tar [nginx:imp]
<a name="id003"></a> #### 容器提交为镜像 ```shell script docker commit [OPTITIONS] CONTAINER [REPOSITORY[:TAG]]] -a:提交作者 -c:使用DockerFile指令创建新的镜像 -m:提交时的文字说明 -p:提交时把容器暂停 #example: docker commit -a "laowng" -m "for example" 容器ID myimage:v1容器或镜像加载
- 上述import或者load方法载入后都会以镜像的形式展示在Docker中,使用时需要重新实例化。 区别是export方法存储的图像没有layer层,即只有第一层FROM层和系统包含的用户文件。而save会将所有的layer 保存,并保留用户文件,所以后者对于程序更友好,程序运行一般也不会出错,但是保存的文件也更大。
- 例如Dockerfile文件如下,export命令将会丢失让所有RUN命令。
FROM centos RUN yum install wget RUN wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz" RUN tar -xvf redis.tar.gz
Docker网络模式
4种网络模式
-
docker使用 –net=“mode” 的方式进行指定容器的网络模式。
-
需要明确的是 docker—daemon(docker守护进程,可理解为Docker服务)和container的网络模式是相互独立的,一般 docker-daemon与主机共享同一个网卡(host模式),即也共享同一个ip地址。
-
也有例外情况,比如在宿主机为windows系统非hyper-v模式下,那么Docker将依赖于Virtualbox(oracle虚拟机), 该虚拟机默认的网络模式为新建一块虚拟网卡,并于主机网卡桥接。此时可以认为Docker-daemon采用了桥接的网络模式(bridge模式)。
-
docker-container的四种网络模式
- bridge 该模式为缺省网络模式(也可以新建一个,在这种模式下 容器会虚拟一个新网卡,并与docker—daemon的网卡建立桥接。 使用这种模式不同的容器之间可以直接使用容器内部ip 进行通信。
- host 该模式,container和docker-daemon共享一个网卡,也即共享一个ip地址。所以这种情况下不同容器具有相同的ip, 只能相同的ip,不同的端口(使用端口映射)进行通信。
- None 该模式,Docker会关闭容器的网络,适用于不需要网络的容器
- container 使用 “ –net=container:container_id(容器名也可以) “进行设置,该模式下新容器与已存在容器共享一个网卡,共享一个ip。
-
创建一个新的网桥
sudo docker network create --subnet=172.18.0.0/16 fixbridge
将容器运行在新的网桥上
sudo docker run --name redis_101 -itd --net fixbridge --ip 172.18.0.101 --restart always
--volume /volume1/docker/redis/data:/var/lib/redis
--volume /volume1/docker/redis/log:/var/log/redis
--env 'PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin'
--env 'REDIS_VERSION=4.0.9'
--env 'REDIS_USER=redis'
--env 'REDIS_DATA_DIR=/var/lib/redis'
--env 'REDIS_LOG_DIR=/var/log/redis'
sameersbn/redis:latest
--name 容器的名称, 我起的名字里面带ip,方便查看
--net 我们创建的网络名称,写你的网络名字哦
--ip 指定的ip。除了该参数界面无法配置外,其他参数界面均可配置。
--restart always 不当关机时,会尝试重启
--volume 指定路径映射, :前面是宿主的路径,该路径你需要在群辉里面创建的。 :后面是映射到容器内部的路径。
--env 环境变量
_posts/2020-12-2-Linux-远程桌面xrdp.md����������������������������������������������������������0000664�0001750�0001750�00000004042�14133252221�022044� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: ubuntu实现远程桌面 subtitle: ubuntu实现远程桌面 date: 2020-12-02 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Linux —
使用XRDP
- 转自Griffon’s IT Library
- 可以使用xorg或者直接连通
- 同一用户多点同时登陆存在问题,教程中的方法可以在一定程度上缓解
使用vnc-any
- 截图工具flameshot挺好用
- 环境
- ubuntu=18.04,支持ubuntu16.xx 1. 在设置中找到“共享”
- 安装xrdp vnc4server xbase-clients dconf-editor
sudo apt-get install xrdp vnc4server xbase-clients sudo apt-get install dconf-editor - 使用dconf-editor 取消加密
- 使用RDP软件进行与远程连接,默认端口号位3389,进入界面后选择vnc-any
使用xorg/xface4实现远程桌面
- 概述
- ubuntu实现远程桌面
- 环境
- ubuntu=16.04 xrdr=0.6.01
- 安装xfce4卓面
sudo apt-get install xfce4 #安装xfce4卓面 echo xfce4-session >~.xsession #指定xfce4为远程桌面 - 安装xrdp服务
sudo apt-get install xrdp #安装xrdp服务 sudo systemctl enable xrdp #将xrdp服务设为开机启动 - 端口号
- xrdp服务的端口默认认为3389 在/etc/xrdp/seeman.ini中修改
- 备注
- 对于ubuntu16需要在/etc/xrdp/startwm.sh中 /etc/X11/Xsession 前加xfce4-session(ubuntu18.04不需要),登陆时选择xvnc
- 对于ubuntu18.04 需要使用dconf-editor工具将 org/gnome/desktop/remote-access/ 下的require-encryption关闭,登陆时选择xorg
- 对于ubuntu18.04 远程时终端无法打开,需要用 sudo update-alternatives –config x-terminal-emulator 命令切换一个默认终端
_posts/2020-12-2-Python-conda和pip.md��������������������������������������������������������������0000664�0001750�0001750�00000003554�14133506060�017633� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: conda subtitle: conda pip 一些常用命令 date: 2020-12-02 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Python —
conda
- 环境输出
conda env export > envName.yaml - 环境安装
conda env create -f envName.yaml - conda更改清华源或者其他源
- conda config –set show_channel_urls yes #使用该命令生成.condarc文件 一般位于”/home/username/”文件夹下
- 将以下清华源索引复制到.condarc文件内,覆盖即可 ```yaml channels:
- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
```
pip
- 环境输出
pip freeze > requirements.txt - 环境安装
pip install -r requirements.txt - pip更换清华源
- 临时使用
pip install PakageName-i https://pypi.tuna.tsinghua.edu.cn/simple some-package - 永久使用
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
- 临时使用
_posts/2021-01-04-Java-Java汇编指令.md����������������������������������������������������������0000664�0001750�0001750�00000024570�14137201421�021616� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: java汇编指令含义 subtitle: java汇编指令含义 date: 2021-1-04 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - 汇编指令 - JAVA — 命令:javap -c xxx.class
- 如果提示:“错误: 找不到类: xxx.class”
- 首先得把java文件编译成class文件
常量压入栈操作- iconst_1 将int类型常量 1压入栈
- iconst_m1 将int类型常量-1压入栈
- lconst_1 将long类型常量1压入栈
- fconst_1 将float类型常量1压入栈
- dconst_1 将double类型常量压入栈
- bipush 将一个8位带符号整数压入栈中
- sipush 将一个16位带符号整数压入栈中
- idc 把常量池中的项压入栈
- idc_w 把常量池中的项压入栈(使用宽索引)
- idc2_w 把常量池中long类型或者double类型的项压入栈(使用款索引)
从栈中局部变量中装载值的命令- iload 从局部变量中装载int类型值
- lload 从局部变量中装载long类型值
- fload 从局部变量中装载float类型值
- dload 从局部变量中装载double类型值
- aload 从局部变量中装载引用类型的值(refernce)
- iload_0 从局部变量0中装载int类型值
- lload_0 从局部变量0中装载long类型值
- fload_0 从局部变量0中装载float类型值
- dload_0 从局部变量0中装载double类型值
- aload_0 从局部变量0中装载引用类型值
- iaload 从数组中装载int类型值
- laload 从数组中装载long类型值
- faload 从数组中装载float类型值
- daload 从数组中装载double类型值
- aaload 从数组中装载引用类型值
- baload 从数组中装载byte类型或boolean类型值
- caload 从数组中装载char类型值
- saload 从数组中装载short类型值
将栈中的值存入局部变量的指令
- istore 将int类型值存入局部变量
- lstore 将long类型值存入局部变量
- fstore 将float类型值存入局部变量
- dstore 将double类型值存入局部变量
- astore 将将引用类型或returnAddress类型值存入局部变量
- istore_0 将int类型值存入局部变量0
- lstore_1 将long类型值存入局部变量1
- fstore_0 将float类型值存入局部变量0
- dstore_0 将double类型值存入局部变量0
- astore_3 将引用类型或returnAddress类型值存入局部变量3
- astore 将int类型值存入数组中
- lastore 将long类型值存入数组中
- fastore 将float类型值存入数组中
- dastore 将double类型值存入数组中
- aastore 将引用类型值存入数组中
- bastore 将byte类型或者boolean类型值存入数组中
- castore 将char类型值存入数组中
- sastore 将short类型值存入数组中
- wide指令
- wide 使用附加字节扩展局部变量索引
通用(无类型)栈操作- nop 不做任何操作
- pop 弹出栈顶端一个字长的内容
- pop2 弹出栈顶端两个字长的内容
- dup 复制栈顶部一个字长内容
- dup_x1 复制栈顶部一个字长的内容,然后将复制内容及原来弹出的两个字长的内容压入栈
- dup_x2 复制栈顶部一个字长的内容,然后将复制内容及原来弹出的三个字长的内容压入栈
- dup2 复制栈顶部两个字长内容
- dup2_x1 复制栈顶部两个字长的内容,然后将复制内容及原来弹出的三个字长的内容压入栈
- dup2_x2 复制栈顶部两个字长的内容,然后将复制内容及原来弹出的四个字长的内容压入栈
- swap 交换栈顶部两个字长内容类型转换
- i2l 把int类型的数据转化为long类型
- i2f 把int类型的数据转化为float类型
- i2d 把int类型的数据转化为double类型
- l2i 把long类型的数据转化为int类型
- l2f 把long类型的数据转化为float类型
- l2d 把long类型的数据转化为double类型
- f2i 把float类型的数据转化为int类型
- f2l 把float类型的数据转化为long类型
- f2d 把float类型的数据转化为double类型
- d2i 把double类型的数据转化为int类型
- d2l 把double类型的数据转化为long类型
- d2f 把double类型的数据转化为float类型
- i2b 把int类型的数据转化为byte类型
- i2c 把int类型的数据转化为char类型
- i2s 把int类型的数据转化为short类型
整数运算
- iadd 执行int类型的加法
- ladd 执行long类型的加法
- isub 执行int类型的减法
- lsub 执行long类型的减法
- imul 执行int类型的乘法
- lmul 执行long类型的乘法
- idiv 执行int类型的除法
- ldiv 执行long类型的除法
- irem 计算int类型除法的余数
- lrem 计算long类型除法的余数
- ineg 对一个int类型值进行取反操作
- lneg 对一个long类型值进行取反操作
- iinc 把一个常量值加到一个int类型的局部变量上
位移操作
- ishl 执行int类型的向左移位操作
- lshl 执行long类型的向左移位操作
- ishr 执行int类型的向右移位操作
- lshr 执行long类型的向右移位操作
- iushr 执行int类型的向右逻辑移位操作
- lushr 执行long类型的向右逻辑移位操作
按位布尔运算
- iand 对int类型值进行“逻辑与”操作
- land 对long类型值进行“逻辑与”操作
- ior 对int类型值进行“逻辑或”操作
- lor 对long类型值进行“逻辑或”操作
- ixor 对int类型值进行“逻辑异或”操作
- lxor 对long类型值进行“逻辑异或”操作
浮点运算
- fadd 执行float类型的加法
- dadd 执行double类型的加法
- fsub 执行float类型的减法
- dsub 执行double类型的减法
- fmul 执行float类型的乘法
- dmul 执行double类型的乘法
- fdiv 执行float类型的除法
- ddiv 执行double类型的除法
- frem 计算float类型除法的余数
- drem 计算double类型除法的余数
- fneg 将一个float类型的数值取反
- dneg 将一个double类型的数值取反
对象操作指令
- new 创建一个新对象
- checkcast 确定对象为所给定的类型
- getfield 从对象中获取字段
- putfield 设置对象中字段的值
- getstatic 从类中获取静态字段
- putstatic 设置类中静态字段的值
- instanceof 判断对象是否为给定的类型
数组操作指令
- newarray 分配数据成员类型为基本上数据类型的新数组
- anewarray 分配数据成员类型为引用类型的新数组
- arraylength 获取数组长度
- multianewarray 分配新的多维数组
条件分支指令
- ifeq 如果等于0,则跳转
- ifne 如果不等于0,则跳转
- iflt 如果小于0,则跳转
- ifge 如果大于等于0,则跳转
- ifgt 如果大于0,则跳转
- ifle 如果小于等于0,则跳转
- if_icmpcq 如果两个int值相等,则跳转
- if_icmpne 如果两个int类型值不相等,则跳转
- if_icmplt 如果一个int类型值小于另外一个int类型值,则跳转
- if_icmpge 如果一个int类型值大于或者等于另外一个int类型值,则跳转
- if_icmpgt 如果一个int类型值大于另外一个int类型值,则跳转
- if_icmple 如果一个int类型值小于或者等于另外一个int类型值,则跳转
- ifnull 如果等于null,则跳转
- ifnonnull 如果不等于null,则跳转
- if_acmpeq 如果两个对象引用相等,则跳转
- if_acmpnc 如果两个对象引用不相等,则跳转
比较指令
- lcmp 比较long类型值
- fcmpl 比较float类型值(当遇到NaN时,返回-1)
- fcmpg 比较float类型值(当遇到NaN时,返回1)
- dcmpl 比较double类型值(当遇到NaN时,返回-1)
- dcmpg 比较double类型值(当遇到NaN时,返回1)
无条件转移指令
- goto 无条件跳转
- goto_w 无条件跳转(宽索引)
- –表跳转指令
- tableswitch 通过索引访问跳转表,并跳转
- lookupswitch 通过键值匹配访问跳转表,并执行跳转操作
- –异常
- athrow 抛出异常或错误
- –finally子句
- jsr 跳转到子例程
- jsr_w 跳转到子例程(宽索引)
- rct 从子例程返回
方法调用指令
- invokcvirtual 运行时按照对象的类来调用实例方法
- invokespecial 根据编译时类型来调用实例方法 ==>调用超类构造方法、实例初始化方法、私有方法
- invokestatic 调用类(静态)方法
- invokcinterface 调用接口方法
方法返回指令
- ireturn 从方法中返回int类型的数据
- lreturn 从方法中返回long类型的数据
- freturn 从方法中返回float类型的数据
- dreturn 从方法中返回double类型的数据
- areturn 从方法中返回引用类型的数据
- return 从方法中返回,返回值为void
线程同步
- monitorenter 进入并获取对象监视器 (获取对象锁)
- monitorexit 释放并退出对象监视器 (释放对象锁)
- JVM指令助记符
变量到操作数栈: iload,iload_
,lload,lload_ ,fload,fload_ ,dload,dload_ ,aload,aload_ - 操作数栈到变量: istore,istore_
,lstore,lstore_ ,fstore,fstore_ ,dstore,dstor_ ,astore,astore_ - 常数到操作数栈: bipush,sipush,ldc,ldc_w,ldc2w,aconst_null,iconst_ml,iconst,lconst_
,fconst_ ,dconst_ - 加: iadd,ladd,fadd,dadd
- 减: isub,lsub,fsub,dsub
- 乘: imul,lmul,fmul,dmul
- 除: idiv,ldiv,fdiv,ddiv
- 余数: irem,lrem,frem,drem
- 取负: ineg,lneg,fneg,dneg
- 移位: ishl,lshr,iushr,lshl,lshr,lushr
- 按位或: ior,lor
- 按位与: iand,land
- 按位异或: ixor,lxor
- 类型转换: i2l,i2f,i2d,l2f,l2d,f2d(放宽数值转换)
- i2b,i2c,i2s,l2i,f2i,f2l,d2i,d2l,d2f(缩窄数值转换)
- 创建类实便: new
- 创建新数组: newarray,anewarray,multianwarray
- 访问类的域和类实例域: getfield,putfield,getstatic,putstatic
- 把数据装载到操作数栈: baload,caload,saload,iaload,laload,faload,daload,aaload
- 从操作数栈存存储到数组: bastore,castore,sastore,iastore,lastore,fastore,dastore,aastore
- 获取数组长度: arraylength
- 检相类实例或数组属性: instanceof,checkcast
- 操作数栈管理: pop,pop2,dup,dup2,dup_xl,dup2_xl,dup_x2,dup2_x2,swap
- 有条件转移: ifeq,iflt,ifle,ifne,ifgt,ifge,ifnull,ifnonnull,if_icmpeq,if_icmpene,
- if_icmplt,if_icmpgt,if_icmple,if_icmpge,if_acmpeq,if_acmpne,lcmp,fcmpl
- fcmpg,dcmpl,dcmpg
- 复合条件转移: tableswitch,lookupswitch
- 无条件转移: goto,goto_w,jsr,jsr_w,ret
- 调度对象的实便方法: invokevirtual
- 调用由接口实现的方法: invokeinterface
- 调用需要特殊处理的实例方法:invokespecial
- 调用命名类中的静态方法: invokestatic
- 方法返回: ireturn,lreturn,freturn,dreturn,areturn,return
- 异常: athrow
- finally关键字的实现使用: jsr,jsr_w,ret����������������������������������������������������������������������������������������������������������������������������������������_posts/2021-04-10-CMD-批处理CMD.md���������������������������������������������������������������0000664�0001750�0001750�00000002070�14137201421�017710� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: cmd笔记
subtitle: cmd笔记
date: 2020-12-02
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:
-
CMD
-
attrib 查看文件文件夹的其它属性
R 只读属性 A 存档属性 S 系统属性 H 隐藏属性
/s /d 可以对该目录下所有匹配的文件和文件夹执行属性
dir /a 列出所用存在的文件或文件夹
git@gitee.com:gitlaowng/gitlaowng.git
端口
-
添加端口转发 netsh interface portproxy add v4tov4 listenport=445 listenaddress=127.0.0.1 connectport=服务器端口 connectaddress=服务器IP
netsh interface portproxy add v4tov4 listenport=445 listenaddress=111.111.111.111 connectport=20445 connectaddress=3312.funcube.top -
查看全部端口转发: netsh interface portproxy show all
-
删除端口转发: netsh interface portproxy delete v4tov4 listenaddress=欲删除项目的监听IP listenport=欲删除项目的监听端口
netsh interface portproxy delete v4tov4 listenaddress=111.111.111.111 listenport=445 1111������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2021-08-10-Mysql-mysql优化.md��������������������������������������������������������������0000664�0001750�0001750�00000062673�14133252221�020214� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: MySQL优化 subtitle: 全方面讲解MySQL优化 date: 2021-08-10 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags:
-
MySQL
-
MySQL 优化
Mysql 找不到my.ini文件
- 在安装mysql时如果没有配置my.ini文件 可以使用mysqld重新绑定,命令为:
mysqld --defaults-file='my.ini 路径' - 安装时配置my.ini文件
mysqld --install "MySql80" --defaults-file="my.ini 路径"
下面说的优化基于 MySQL 5.6,理论上 5.5 之后的都算适用,具体还是要看官网
优秀材料
服务状态查询
- 查看当前数据库的状态,常用的有:
- 查看系统状态:
SHOW STATUS; - 查看刚刚执行 SQL 是否有警告信息:
SHOW WARNINGS; - 查看刚刚执行 SQL 是否有错误信息:
SHOW ERRORS; - 查看已经连接的所有线程状况:
SHOW FULL PROCESSLIST;- 输出参数说明:http://www.ibloger.net/article/2519.html
- 可以结束某些连接:
kill id值
- 查看当前连接数量:
SHOW STATUS LIKE 'max_used_connections'; - 查看变量,在 my.cnf 中配置的变量会在这里显示:
SHOW VARIABLES; - 查询慢 SQL 配置:
show variables like 'slow%';- 开启慢 SQL:
set global slow_query_log='ON'
- 开启慢 SQL:
- 查询慢 SQL 秒数值:
show variables like 'long%';- 调整秒速值:
set long_query_time=1;
- 调整秒速值:
- 查看当前MySQL 中已经记录了多少条慢查询,前提是配置文件中开启慢查询记录了.
SHOW STATUS LIKE '%slow_queries%';
- 查询当前MySQL中查询、更新、删除执行多少条了,可以通过这个来判断系统是侧重于读还是侧重于写,如果是写要考虑使用读写分离。
SHOW STATUS LIKE '%Com_select%';SHOW STATUS LIKE '%Com_insert%';SHOW STATUS LIKE '%Com_update%';SHOW STATUS LIKE '%Com_delete%';
- 如果 rollback 过多,说明程序肯定哪里存在问题
SHOW STATUS LIKE '%Com_rollback%';
- 显示MySQL服务启动运行了多少时间,如果MySQL服务重启,该时间重新计算,单位秒
SHOW STATUS LIKE 'uptime';
- 显示查询缓存的状态情况
SHOW STATUS LIKE 'qcache%';- PS.下面的解释,我目前不肯定是对,还要再找下资料:
- http://dba.stackexchange.com/questions/33811/qcache-free-memory-not-full-yet-i-get-alot-of-qcache-lowmem-prunes
- https://dev.mysql.com/doc/refman/5.7/en/query-cache-status-and-maintenance.html
- https://dev.mysql.com/doc/refman/5.7/en/server-status-variables.html
- http://www.111cn.net/database/110/c0c88da67b9e0c6c8fabfbcd6c733523.htm
-
- Qcache_free_blocks,缓存中相邻内存块的个数。数目大说明可能有碎片。如果数目比较大,可以执行:
flush query cache;对缓存中的碎片进行整理,从而得到一个空闲块。
- Qcache_free_blocks,缓存中相邻内存块的个数。数目大说明可能有碎片。如果数目比较大,可以执行:
-
- Qcache_free_memory,缓存中的空闲内存大小。如果 Qcache_free_blocks 比较大,说明碎片严重。 如果 Qcache_free_memory 很小,说明缓存不够用了。
-
- Qcache_hits,每次查询在缓存中命中时就增大该值。
-
- Qcache_inserts,每次查询,如果没有从缓存中找到数据,这里会增大该值
-
- Qcache_lowmem_prunes,因内存不足删除缓存次数,缓存出现内存不足并且必须要进行清理, 以便为更多查询提供空间的次数。返个数字最好长时间来看;如果返个数字在不断增长,就表示可能碎片非常严重,或者缓存内存很少。
-
- Qcache_not_cached # 没有进行缓存的查询的数量,通常是这些查询未被缓存或其类型不允许被缓存
-
- Qcache_queries_in_cache # 在当前缓存的查询(和响应)的数量。
-
- Qcache_total_blocks #缓存中块的数量。
- 查看系统状态:
- 查询哪些表在被使用,是否有锁表:
SHOW OPEN TABLES WHERE In_use > 0; - 查询 innodb 状态(输出内容很多):
SHOW ENGINE INNODB STATUS; - 锁性能状态:
SHOW STATUS LIKE 'innodb_row_lock_%';- Innodb_row_lock_current_waits:当前等待锁的数量
- Innodb_row_lock_time:系统启动到现在、锁定的总时间长度
- Innodb_row_lock_time_avg:每次平均锁定的时间
- Innodb_row_lock_time_max:最长一次锁定时间
- Innodb_row_lock_waits:系统启动到现在、总共锁定次数
- 帮我们分析表,并提出建议:
select * from my_table procedure analyse();
系统表
- 当前运行的所有事务:
select * from information_schema.INNODB_TRX; - 当前事务出现的锁:
select * from information_schema.INNODB_LOCKS; - 锁等待的对应关系:
select * from information_schema.INNODB_LOCK_WAITS;
otpimizer trace
- 作用:输入我们想要查看优化过程的查询语句,当该查询语句执行完成后,就可以到 information_schema 数据库下的OPTIMIZER_TRACE表中查看 mysql 自己帮我们的完整优化过程
- 是否打开(默认都是关闭):
SHOW VARIABLES LIKE 'optimizer_trace';- one_line的值是控制输出格式的,如果为on那么所有输出都将在一行中展示,不适合人阅读,所以我们就保持其默认值为off吧。
- 打开配置:
SET optimizer_trace="enabled=on"; - 关闭配置:
SET optimizer_trace="enabled=off"; - 查询优化结果:
SELECT * FROM information_schema.OPTIMIZER_TRACE;
我们所说的基于成本的优化主要集中在optimize阶段,对于单表查询来说,我们主要关注optimize阶段的"rows_estimation"这个过程,这个过程深入分析了对单表查询的各种执行方案的成本;
对于多表连接查询来说,我们更多需要关注"considered_execution_plans"这个过程,这个过程里会写明各种不同的连接方式所对应的成本。
反正优化器最终会选择成本最低的那种方案来作为最终的执行计划,也就是我们使用EXPLAIN语句所展现出的那种方案。
如果有小伙伴对使用EXPLAIN语句展示出的对某个查询的执行计划很不理解,大家可以尝试使用optimizer trace功能来详细了解每一种执行方案对应的成本,相信这个功能能让大家更深入的了解MySQL查询优化器。
查询优化(EXPLAIN 查看执行计划)
- 使用 EXPLAIN 进行 SQL 语句分析:
EXPLAIN SELECT * FROM sys_user;,效果如下:
id|select_type|table |partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra|
--|-----------|--------|----------|----|-------------|---|-------|---|----|--------|-----|
1|SIMPLE |sys_user| |ALL | | | | | 2| 100| |
- 简单描述
id:在一个大的查询语句中每个 SELECT 关键字都对应一个唯一的idselect_type:SELECT 关键字对应的那个查询的类型table:表名partitions:匹配的分区信息type:针对单表的访问方法possible_keys:可能用到的索引key:实际上使用的索引key_len:实际使用到的索引长度ref:当使用索引列等值查询时,与索引列进行等值匹配的对象信息rows:预估的需要读取的记录条数filtered:某个表经过搜索条件过滤后剩余记录条数的百分比Extra:一些额外的信息
- 有多个结果的场景分析
- 有子查询的一般都会有多个结果,id 是递增值。但是,有些场景查询优化器可能对子查询进行重写,转换为连接查询。所以有时候 id 就不是自增值。
- 对于连接查询一般也会有多个接口,id 可能是相同值,相同值情况下,排在前面的记录表示驱动表,后面的表示被驱动表
- UNION 场景会有 id 为 NULL 的情况,这是一个去重后临时表,合并多个结果集的临时表。但是,UNION ALL 不会有这种情况,因为这个不需要去重。
- 根据具体的描述:
- id,该列表示当前结果序号
- select_type,表示 SELECT 语句的类型,有下面几种
SIMPLE:表示简单查询,其中不包括 UNION 查询和子查询PRIMARY:对于包含UNION、UNION ALL或者子查询的大查询来说,它是由几个小查询组成的,其中最左边的那个查询的select_type值就是PRIMARYUNION:对于包含UNION或者UNION ALL的大查询来说,它是由几个小查询组成的,其中除了最左边的那个小查询以外,其余的小查询的select_type值就是UNIONUNION RESULT:MySQL选择使用临时表来完成UNION查询的去重工作,针对该临时表的查询的select_type就是UNION RESULTSUBQUERY:如果包含子查询的查询语句不能够转为对应的semi-join的形式,并且该子查询是不相关子查询,并且查询优化器决定采用将该子查询物化的方案来执行该子查询时,该子查询的第一个SELECT关键字代表的那个查询的select_type就是SUBQUERYDEPENDENT SUBQUERY:如果包含子查询的查询语句不能够转为对应的semi-join的形式,并且该子查询是相关子查询,则该子查询的第一个SELECT关键字代表的那个查询的select_type就是DEPENDENT SUBQUERYDEPENDENT UNION:在包含UNION或者UNION ALL的大查询中,如果各个小查询都依赖于外层查询的话,那除了最左边的那个小查询之外,其余的小查询的select_type的值就是DEPENDENT UNIONDERIVED:对于采用物化的方式执行的包含派生表的查询,该派生表对应的子查询的select_type就是DERIVEDMATERIALIZED:当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询时,该子查询对应的select_type属性就是MATERIALIZED- 还有其他一些
- table,表名或者是子查询的一个结果集
- type,表示表的链接类型,分别有(以下的连接类型的顺序是从最佳类型到最差类型)(这个属性重要):
- 性能好:
system:当表中只有一条记录并且该表使用的存储引擎的统计数据是精确的,比如MyISAM、Memory,那么对该表的访问方法就是system,平时不会出现,这个也可以忽略不计。const:当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是const,常用于 PRIMARY KEY 或者 UNIQUE 索引的查询,可理解为 const 是最优化的。eq_ref:在连接查询时,如果被驱动表是通过主键或者唯一二级索引列等值匹配的方式进行访问的(如果该主键或者唯一二级索引是联合索引的话,所有的索引列都必须进行等值比较),则对该被驱动表的访问方法就是eq_refref:当通过普通的二级索引列与常量进行等值匹配时来查询某个表,那么对该表的访问方法就可能是ref。ref 可用于 = 或 < 或 > 操作符的带索引的列。ref_or_null:当对普通二级索引进行等值匹配查询,该索引列的值也可以是NULL值时,那么对该表的访问方法就可能是ref_or_null
- 性能较差:
index_merge:该联接类型表示使用了索引合并优化方法。在这种情况下,key 列包含了使用的索引的清单,key_len 包含了使用的索引的最长的关键元素。unique_subquery:类似于两表连接中被驱动表的eq_ref访问方法,unique_subquery是针对在一些包含IN子查询的查询语句中,如果查询优化器决定将IN子查询转换为EXISTS子查询,而且子查询可以使用到主键进行等值匹配的话,那么该子查询执行计划的type列的值就是unique_subqueryindex_subquery:index_subquery与unique_subquery类似,只不过访问子查询中的表时使用的是普通的索引range:只检索给定范围的行, 使用一个索引来选择行。index:该联接类型与 ALL 相同, 除了只有索引树被扫描。这通常比 ALL 快, 因为索引文件通常比数据文件小。- 再一次强调,对于使用InnoDB存储引擎的表来说,二级索引的记录只包含索引列和主键列的值,而聚簇索引中包含用户定义的全部列以及一些隐藏列,所以扫描二级索引的代价比直接全表扫描,也就是扫描聚簇索引的代价更低一些
- 性能最差:
ALL:对于每个来自于先前的表的行组合, 进行完整的表扫描。(性能最差)
- 性能好:
possible_keys,指出 MySQL 能使用哪个索引在该表中找到行。如果该列为 NULL,说明没有使用索引,可以对该列创建索引来提供性能。(这个属性重要)- possible_keys列中的值并不是越多越好,可能使用的索引越多,查询优化器计算查询成本时就得花费更长时间,所以如果可以的话,尽量删除那些用不到的索引。
key,显示 MySQL 实际决定使用的键 (索引)。如果没有选择索引, 键是 NULL。(这个属性重要)- 不过有一点比较特别,就是在使用index访问方法来查询某个表时,possible_keys列是空的,而key列展示的是实际使用到的索引
key_len,表示当优化器决定使用某个索引执行查询时,该索引记录的最大长度。如果键是可以为 NULL, 则长度多 1。ref,显示使用哪个列或常数与 key 一起从表中选择行。rows,显示 MySQL 认为它执行查询时必须检查的行数。(这个属性重要)Extra,该列包含 MySQL 解决查询的详细信息:DistinctMySQL 发现第 1 个匹配行后, 停止为当前的行组合搜索更多的行。Not exists当我们使用左(外)连接时,如果WHERE子句中包含要求被驱动表的某个列等于NULL值的搜索条件,而且那个列又是不允许存储NULL值的,那么在该表的执行计划的Extra列就会提示Not exists额外信息range checked for each record (index map: #)MySQL 没有发现好的可以使用的索引, 但发现如果来自前面的表的列值已知, 可能部分索引可以使用。Using filesort有一些情况下对结果集中的记录进行排序是可以使用到索引的- 需要注意的是,如果查询中需要使用filesort的方式进行排序的记录非常多,那么这个过程是很耗费性能的,我们最好想办法将使用文件排序的执行方式改为使用索引进行排序。
Using temporary在许多查询的执行过程中,MySQL可能会借助临时表来完成一些功能,比如去重、排序之类的,比如我们在执行许多包含DISTINCT、GROUP BY、UNION等子句的查询过程中,如果不能有效利用索引来完成查询,MySQL很有可能寻求通过建立内部的临时表来执行查询。如果查询中使用到了内部的临时表,在执行计划的Extra列将会显示Using temporary提示- 如果我们并不想为包含GROUP BY子句的查询进行排序,需要我们显式的写上:ORDER BY NULL
- 执行计划中出现Using temporary并不是一个好的征兆,因为建立与维护临时表要付出很大成本的,所以我们最好能使用索引来替代掉使用临时表
Using join buffer (Block Nested Loop)在连接查询执行过程过,当被驱动表不能有效的利用索引加快访问速度,MySQL一般会为其分配一块名叫join buffer的内存块来加快查询速度,也就是我们所讲的基于块的嵌套循环算法Using where- 当我们使用全表扫描来执行对某个表的查询,并且该语句的WHERE子句中有针对该表的搜索条件时,在Extra列中会提示上述额外信息
- 当使用索引访问来执行对某个表的查询,并且该语句的WHERE子句中有除了该索引包含的列之外的其他搜索条件时,在Extra列中也会提示上述额外信息
Using sort_union(...), Using union(...), Using intersect(...)如果执行计划的Extra列出现了Using intersect(…)提示,说明准备使用Intersect索引合并的方式执行查询,括号中的…表示需要进行索引合并的索引名称;如果出现了Using union(…)提示,说明准备使用Union索引合并的方式执行查询;出现了Using sort_union(…)提示,说明准备使用Sort-Union索引合并的方式执行查询。Using index condition有些搜索条件中虽然出现了索引列,但却不能使用到索引Using index当我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用索引覆盖的情况下,在Extra列将会提示该额外信息Using index for group-by类似于访问表的 Using index 方式,Using index for group-by 表示 MySQL 发现了一个索引, 可以用来查 询 GROUP BY 或 DISTINCT 查询的所有列, 而不要额外搜索硬盘访问实际的表。
查询不走索引优化
- WHERE字句的查询条件里有不等于号(WHERE column!=…),MYSQL将无法使用索引
- 类似地,如果WHERE字句的查询条件里使用了函数(如:WHERE DAY(column)=…),MYSQL将无法使用索引
- 在JOIN操作中(需要从多个数据表提取数据时),MYSQL只有在主键和外键的数据类型相同时才能使用索引,否则即使建立了索引也不会使用
- 如果WHERE子句的查询条件里使用了比较操作符LIKE和REGEXP,MYSQL只有在搜索模板的第一个字符不是通配符的情况下才能使用索引。比如说,如果查询条件是LIKE ‘abc%’,MYSQL将使用索引;如果条件是LIKE ‘%abc’,MYSQL将不使用索引。
- 在ORDER BY操作中,MYSQL只有在排序条件不是一个查询条件表达式的情况下才使用索引。尽管如此,在涉及多个数据表的查询里,即使有索引可用,那些索引在加快ORDER BY操作方面也没什么作用。
- 如果某个数据列里包含着许多重复的值,就算为它建立了索引也不会有很好的效果。比如说,如果某个数据列里包含了净是些诸如“0/1”或“Y/N”等值,就没有必要为它创建一个索引。
- 索引有用的情况下就太多了。基本只要建立了索引,除了上面提到的索引不会使用的情况下之外,其他情况只要是使用在WHERE条件里,ORDER BY 字段,联表字段,一般都是有效的。 建立索引要的就是有效果。 不然还用它干吗? 如果不能确定在某个字段上建立的索引是否有效果,只要实际进行测试下比较下执行时间就知道。
- 如果条件中有or(并且其中有or的条件是不带索引的),即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)。注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引
子查询优化
- MySQL 从 4.1 版本开始支持子查询,使用子查询进行 SELECT 语句嵌套查询,可以一次完成很多逻辑上需要多个步骤才能完成的 SQL 操作。
- 子查询虽然很灵活,但是执行效率并不高。
- 执行子查询时,MYSQL 需要创建临时表,查询完毕后再删除这些临时表,所以,子查询的速度会受到一定的影响。
- 优化:
- 可以使用连接查询(JOIN)代替子查询,连接查询时不需要建立临时表,其速度比子查询快。
其他查询优化
- 关联查询过程
- 确保 ON 或者 using子句中的列上有索引
- 确保任何的 groupby 和 orderby 中的表达式只涉及到一个表中的列。
- count()函数优化
- count()函数有一点需要特别注意:它是不统计值为NULL的字段的!所以:不能指定查询结果的某一列,来统计结果行数。即 count(xx column) 不太好。
- 如果想要统计结果集,就使用 count(*),性能也会很好。
- 分页查询(数据偏移量大的场景)
- 不允许跳页,只能上一页或者下一页
- 使用 where 加上上一页 ID 作为条件(具体要看 explain 分析效果):
select xxx,xxx from test_table where id < '上页id分界值' order by id desc limit 20;
创表原则
- 所有字段均定义为 NOT NULL ,除非你真的想存 Null。因为表内默认值 Null 过多会影响优化器选择执行计划
建立索引原则
- 使用区分度高的列作为索引,字段不重复的比例,区分度越高,索引树的分叉也就越多,一次性找到的概率也就越高。
- 尽量使用字段长度小的列作为索引
- 使用数据类型简单的列(int 型,固定长度)
- 选用 NOT NULL 的列。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值。
- 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。这样也可避免索引重复。
数据库结构优化
- 将字段很多的表分解成多个表
- 对于字段较多的表,如果有些字段的使用频率很低,可以将这些字段分离出来形成新表。
- 因为当一个表的数据量很大时,会由于使用频率低的字段的存在而变慢。
- 增加中间表
- 对于需要经常联合查询的表,可以建立中间表以提高查询效率。
- 通过建立中间表,将需要通过联合查询的数据插入到中间表中,然后将原来的联合查询改为对中间表的查询。
- 增加冗余字段
- 设计数据表时应尽量遵循范式理论的规约,尽可能的减少冗余字段,让数据库设计看起来精致、优雅。但是,合理的加入冗余字段可以提高查询速度。
插入数据的优化(适用于 InnoDB)
- 插入数据时,影响插入速度的主要是索引、唯一性校验、一次插入的数据条数等。
- 开发环境情况下的考虑:
- 开发场景中,如果需要初始化数据,导入数据等一些操作,而且是开发人员进行处理的,可以考虑在插入数据之前,先禁用整张表的索引,
- 禁用索引使用 SQL:
ALTER TABLE table_name DISABLE KEYS; - 当导入完数据之后,重新让MySQL创建索引,并开启索引:
ALTER TABLE table_name ENABLE KEYS;
- 禁用索引使用 SQL:
- 如果表中有字段是有唯一性约束的,可以先禁用,然后在开启:
- 禁用唯一性检查的语句:
SET UNIQUE_CHECKS = 0; - 开启唯一性检查的语句:
SET UNIQUE_CHECKS = 1;
- 禁用唯一性检查的语句:
- 禁用外键检查(建议还是少量用外键,而是采用代码逻辑来处理)
- 插入数据之前执行禁止对外键的检查,数据插入完成后再恢复,可以提供插入速度。
- 禁用:
SET foreign_key_checks = 0; - 开启:
SET foreign_key_checks = 1;
- 使用批量插入数据
- 禁止自动提交
- 插入数据之前执行禁止事务的自动提交,数据插入完成后再恢复,可以提供插入速度。
- 禁用:
SET autocommit = 0; - 开启:
SET autocommit = 1; - 插入数据之前执行禁止对外键的检查,数据插入完成后再恢复
- 禁用:
SET foreign_key_checks = 0; - 开启:
SET foreign_key_checks = 1;
- 开发场景中,如果需要初始化数据,导入数据等一些操作,而且是开发人员进行处理的,可以考虑在插入数据之前,先禁用整张表的索引,
服务器优化
- 好硬件大家都知道,这里没啥好说,如果是 MySQL 单独一台机子,那机子内存可以考虑分配 60%~70% 给 MySQL
- 通过优化 MySQL 的参数可以提高资源利用率,从而达到提高 MySQL 服务器性能的目的。
- 由于 binlog 日志的读写频繁,可以考虑在 my.cnf 中配置,指定这个 binlog 日志到一个 SSD 硬盘上。
锁相关
InnoDB支持事务;InnoDB 采用了行级锁。也就是你需要修改哪行,就可以只锁定哪行。 在 Mysql 中,行级锁并不是直接锁记录,而是锁索引。索引分为主键索引和非主键索引两种,如果一条sql 语句操作了主键索引,Mysql 就会锁定这条主键索引;如果一条语句操作了非主键索引,MySQL会先锁定该非主键索引,再锁定相关的主键索引。 InnoDB 行锁是通过给索引项加锁实现的,如果没有索引,InnoDB 会通过隐藏的聚簇索引来对记录加锁。也就是说:如果不通过索引条件检索数据,那么InnoDB将对表中所有数据加锁,实际效果跟表锁一样。因为没有了索引,找到某一条记录就得扫描全表,要扫描全表,就得锁定表。
数据库的增删改操作默认都会加排他锁,而查询不会加任何锁。
排他锁:对某一资源加排他锁,自身可以进行增删改查,其他人无法进行任何操作。语法为: select * from table for update;
共享锁:对某一资源加共享锁,自身可以读该资源,其他人也可以读该资源(也可以再继续加共享锁,即 共享锁可多个共存),但无法修改。 要想修改就必须等所有共享锁都释放完之后。语法为: select * from table lock in share mode;
资料
- https://my.oschina.net/jsan/blog/653697
- https://blog.imdst.com/mysql-5-6-pei-zhi-you-hua/
- https://mp.weixin.qq.com/s/qCRfxIr1RoHd9i8-Hk8iuQ
- https://yancg.cn/detail?id=3
- https://www.jianshu.com/p/1ab3cd5551b9
- http://blog.brucefeng.info/post/mysql-index-query?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
- https://juejin.im/book/5bffcbc9f265da614b11b731���������������������������������������������������������������������_posts/2021-09-29-分布式-hadoop环境搭建.md���������������������������������������������������0000664�0001750�0001750�00000015454�14141446123�024565� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: Hadoop环境搭建
subtitle: 使用Docker
date: 2021-09-29
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:-
分布式
介绍
使用群晖Docker 搭建hadoop分布式服务
使用了4个jdk1.8的容器分别作1个nameNode 和3个dataNode
命名分别为:hdfs-master hdfs-slave1 hdfs-slave2 hdfs-slave3
-
目录
常见问题
- 启动问题 可以如下命令查看具体错误
hdfs dfsadmin -report - hdfs种的主机名中不要出现下划线(_),可以使用“-”代替。
环境配置
拉取JDK1.8镜象
- 本例使用的镜像地址为:dustheart/jdk1.8_8u261:v8u261 ,镜像为精简版centos系统
docker pull dustheart/jdk1.8_8u261:v8u261
配置ssh server
- 下载安装ssh server 和 ssh client
yum install openssh-server -y yum install openssh-clients -y
配置ssh server自启动
- 拉取的centos镜像没有systemd工具,这里使用修改/etc/bashrc的方式来自启动,实验发现修改/etc/profile无法自动执行启动脚本
- 启动脚本如下,文件路径为/usr/bin/sshd_autorun.sh
#!/bin/bash sshd_flag=`ps -ef|grep sshd |grep -v grep` if [ ${#sshd_flag} == 0 ] then /usr/sbin/sshd -D fi - 将 “/usr/bin/sshd_autorun.sh”添加到/etc/bashrc文件末尾
- ssh server 启动应该会报错,需要修复以下
ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key ssh-keygen -t rsa -f /etc/ssh/ssh_host_ecdsa_key ssh-keygen -t rsa -f /etc/ssh/ssh_host_ed25519_key
ssh免密登陆
- 4个容器需要启动ssh-server
ssh-kengen -t rsa #一路下一步 ssh-copy-id hdfs-master #自己需要给自己拷贝一份 ssh-copy-id hdfs-slave1 #docker可以自动将dockerName映射为ip ssh-copy-id hdfs-slave2 ssh-copy-id hdfs-slave3
添加环境变量
- /etc/bashrc中添加如下,/hadoop/hadoop-3.3.1/为haddop解压路径
export PATH=/hadoop/hadoop-3.3.1/bin:/hadoop/hadoop-3.3.1/sbin:$PATH
hadoop配置
core-site.xml配置
- 配置
<configuration> <property> <name>fs.defaultFS</name> #默认 <value>hdfs://hdfs-master:9000</value> #hdfs的api接口 </property> <property> <name>hadoop.tmp.dir</name> #hadoop运行时产生临时数据的存储目录 <value>/home/hadoop/apps/tmp</value> #该目录的地址 </property> </configuration>
hdfs-site.xml配置
- vi /hadoop/hadoop-3.3.1/etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>hdfs-master:50090</value> </property> <property> <name>dfs.replication</name> #设置副本个数 <value>3</value> </property> <property> <name>dfs.namenode.name.dir</name> #设置namende数据存放点 <value>/home/hadoop/apps/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> #设置datanode数据存放点 <value>/home/hadoop/apps/dfs/data</value> </property> </configuration>
mapred-site.xml配置
- vi /hadoop/hadoop-3.3.1/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framwork.name</name> #设置mapreduce的运行平台的名称 <value>yarn</value> #设置mapreduce的运行平台为yarn </property> </configuration>
yarn-site.xml配置
- vi /hadoop/hadoop-3.3.1/etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> #指定yarn的老大的地址 <value>hdfs-master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> #reducer获取数据的方式 <value>mapreduce_shuffle</value> </property> </configuration>
workers配置
- vi /hadoop/hadoop-3.3.1/etc/hadoop/workers
- 添加
hdfs-slave1 hdfs-slave2 hdfs-slave3
hadoop-env.xml配置
- vi /hadoop/hadoop-3.3.1/etc/hadoop/hadoop-env.sh
- 添加root启动,配置JAVA_HOME
export HDFS_DATANODE_USER=root export HDFS_DATABODE_SECURE_USER=root export HDFS_NAMENODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export JAVA_HOME=/usr/local/jdk/jdk1.8.0_261
从节点配置
- 如下为全量复制,比较慢,可以采用解压缩包,然后值复制哦诶值文件的方法
scp -r /hadoop/hadoop3.3.1 hdfs-slave1:/hadoop/ scp -r /hadoop/hadoop3.3.1 hdfs-slave2:/hadoop/ scp -r /hadoop/hadoop3.3.1 hdfs-slave3:/hadoop/
hdfs的运行
- 格式化hdfs
hdfs namenode -format - 启动hdfs
s - 停止hdfs
stop-dfs.sh - 在线监控
sh http://hdfs-master:9870 #可以使用docker配置端口映射,直接用宿主机地址访问��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2021-10-10-分布式-Hbase笔记.md����������������������������������������������������������0000664�0001750�0001750�00000015051�14133252221�022201� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: Hbase笔记 subtitle: Hbase笔记 date: 2021-10-10 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags:- Hbase
-
Hadoop
介绍
以下学习笔记来自于尚硅谷的Hbase课程
目录
前言
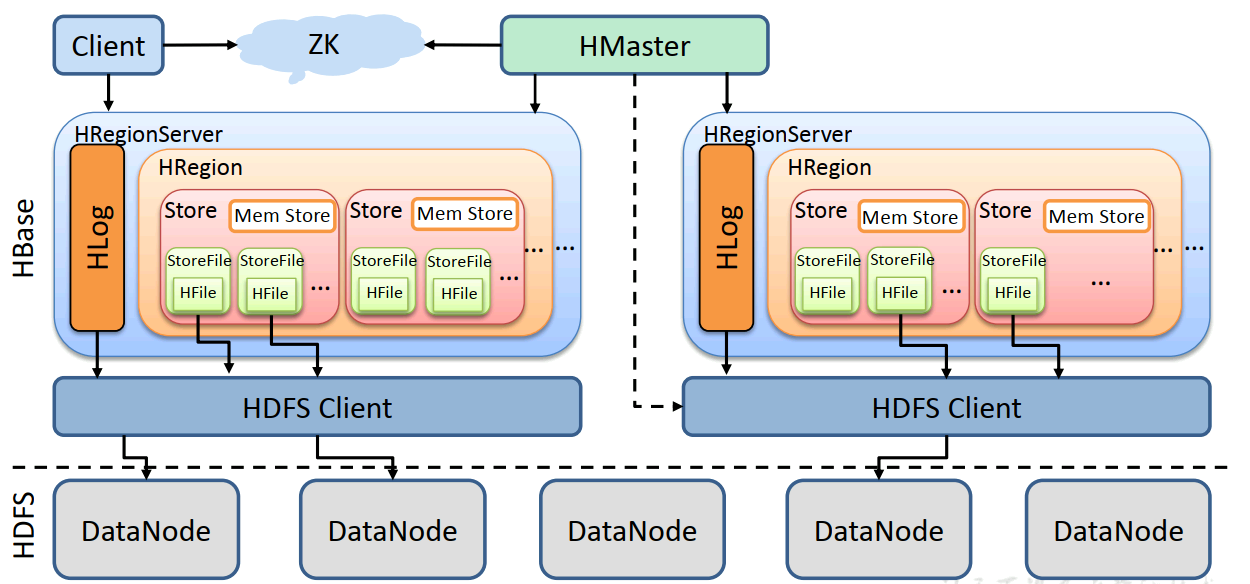
- HMaster 记录元数据,管理表(DDL),DML任务分发给RegionServer
- HRegionServer 处理增删改查(DML)
- HRegion 一张表占用一个或多个HRegion,一个HRegion只从属于一张表
- Store对应一个列族,在同一个Region中不会有同名的Store(列族)
- StoreFile 保存实际数据的物理文件, StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有 一个或多个 StoreFile(HFile),数据在每个 StoreFile 中都是有序的。
- MemStore 写缓存, 由于 HFile 中的数据要求是有序的, 所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile。
- WAL(Hlog 预写入日志,文件对应写入预写入缓存MemStore) 由于数据要经 MemStore 排序后才能刷写到 HFile, 但把数据保存在内存中会有很高的 概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件 中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重 建。
- Hbase客户端在读写数据时直接与ZK和RegionServer交互
- Hbase是一个读比写慢的框架
habse写数据
- put NSP:Stu,rowkey:0001,name:张三
- 向ZK请求hbase:meta表的位置(一个HregionServer,代号HR1)
- 在HR1查找维护NSP:Stu表的HregionServer位置,代号HR2
- 在HR2中存储数据,HR2存储成功后返回ACK
MemStore刷写时机
- 当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M) , 其所在 region 的所有 memstore 都会刷写。 当 memstore 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M),hbase.hregion.memstore.block.multiplier(默认值 4) 时,会阻止继续往该 memstore 写数据。
- region server 中 memstore 的总大小达到 java_heapsize hbase.regionserver.global.memstore.size(默认值 0.4) *hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95) , region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server 中所有 memstore 的总大小减小到上述值以下。 当 region server 中 memstore 的总大小达到 java_heapsizehbase.regionserver.global.memstore.size(默认值 0.4) 时,会阻止继续往所有的 memstore 写数据。
- 到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性进行 配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时) 。尚硅谷大数据技术之 Hbase
- 当 WAL 文件的数量超过 hbase.regionserver.max.logs, region 会按照时间顺序依次进 行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属性名已经废弃, 现无需手动设置, 最大值为 32)
hbase读数据
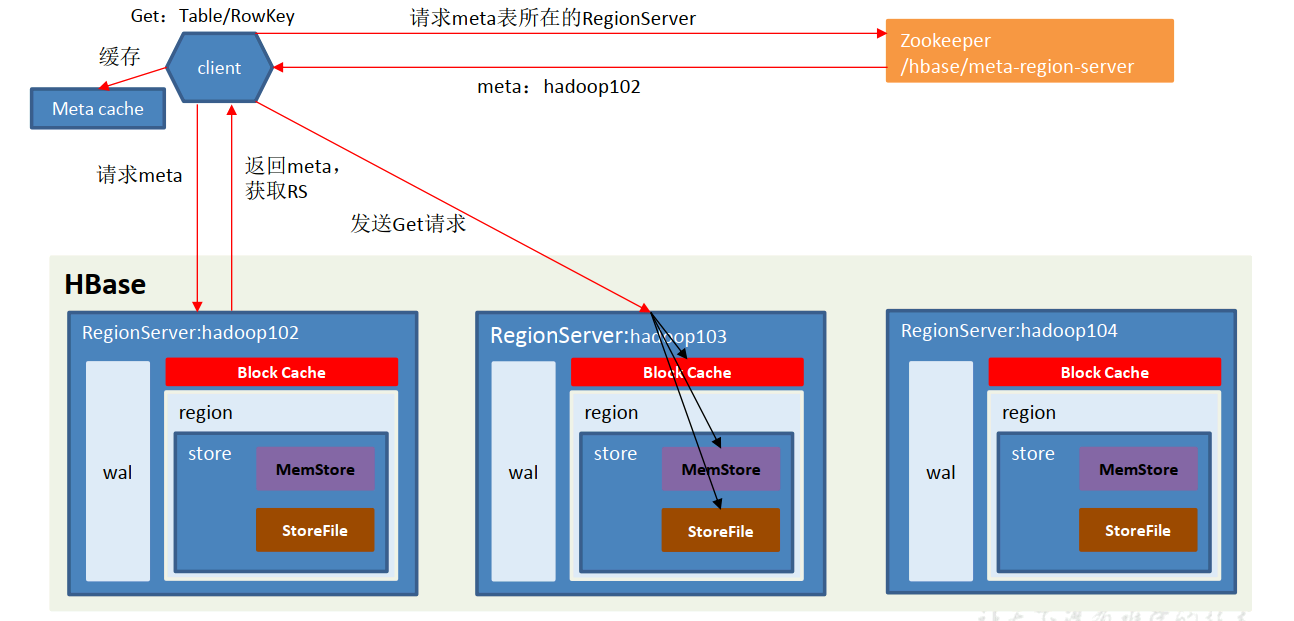
- Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
- 访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey, 查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以 及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
- 与目标 Region Server 进行通讯;
- 分别在 Block Cache(读缓存), MemStore 和 Store File(HFile)中查询目标数据,并将 查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不 同的类型(Put/Delete)。
- 将从文件中查询到的数据块(Block, HFile 数据存储单元,默认大小为 64KB)缓存到 Block Cache。
- 将合并后的最终结果返回给客户端。 7 Block Cache用于缓存读取的磁盘的数据,如果Block Cache 种存在命中数据,则只需要合并Memstore和Block Cache中的数据
hbase和并数据(SotreFile Compaction) 和 拆分表(Region Split)
- 合并
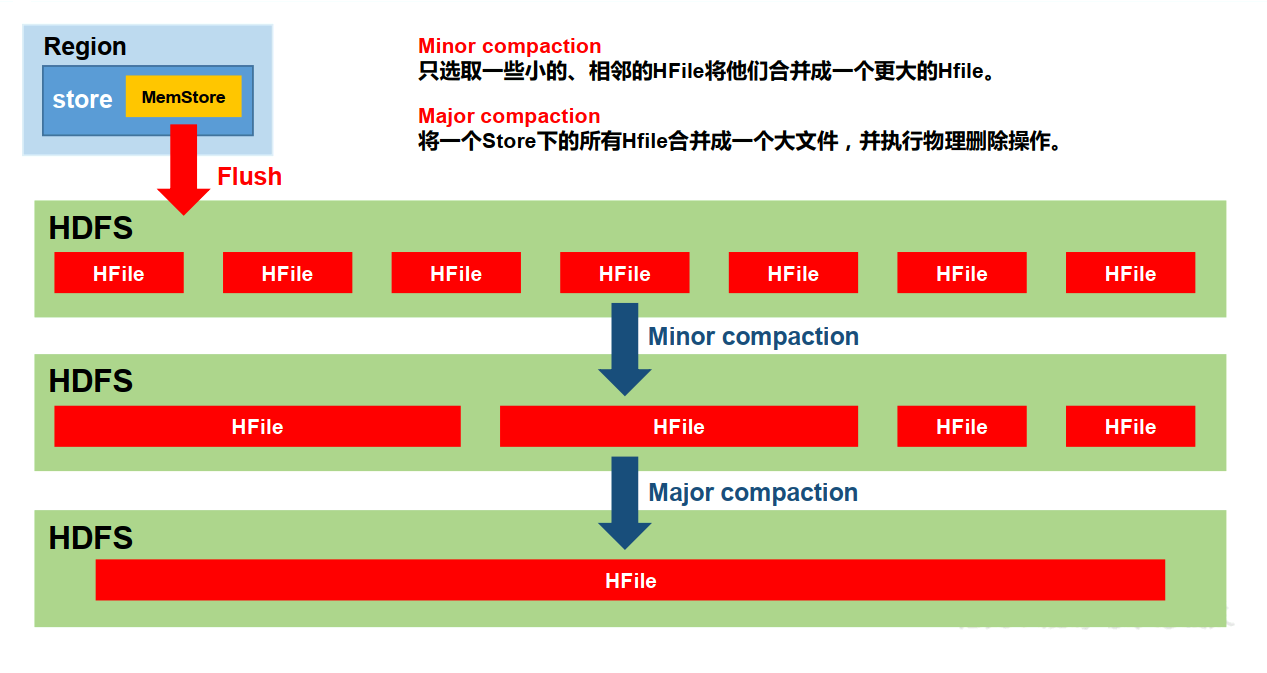
- habeshell 1.minor compact:compact(简单合并) 2.major compact : major_compact(会删除过期版本数据)
- 自动触发条件:
- habse.hregion.majorcompaction,默认值为7天,每隔7天来一次大合并,生产环境建议关闭
- habse.hstore.compactionThreshould 一个store中允许hfile的个数,达到时触发
- 拆分

- 默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入, Region 会自动进 行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑, HMaster 有可能会将某个 Region 转移给其他的 Region Server。
- Region Split 时机:
- 当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize, 该 Region 就会进行拆分(0.94 版本之前)。
- 当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过 Min(R^2 * “hbase.hregion.memstore.flush.size”,hbase.hregion.max.filesize”), 该 Region 就会进行拆分,其 中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。
- 总结
- habse和并的是族内数据,同一个store(列族)合并为一个hfile,合并可以提高数据的访问速度,保证数据整体的有序性。
- hbase拆分拆分是将一个Region分裂成两个Region(同一个Region中的多个Store同步拆分),后期再将region分离到别的机器上(RegionServer) ,先合并再拆分可以保证了两个SotreFile数据的有序性,同时也兼顾了性能(小文件读取和写入更快),最终目的是实现负载均衡。
- 生产中建议只使用一个列族,因为列族不均匀,数据量少的列族会形成大量小文件。���������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2021-10-11-Markdown-飞行指南.md����������������������������������������������������������0000664�0001750�0001750�00000014052�14133252221�021563� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: Markdown飞行指南
subtitle: Markdown飞行指南
date: 2021-10-11 author: AnAn
header-img: /img/post-bg-article.jpg
catalog: false
tags:-
Markdown
-
前言
- 使用typora作markdown编辑器,相当不错;不过Markdown本身以语法简单出名,多掌握一种语言在工作中也会事半功倍。 下边是总结的Markdown的以下常用语法
目录
标签
- 标题标识符为#,标题级别用#数量表示,注意#与内容之间有一个空格,语法如下:
# 一级标题 ## 二级标题 ### 三级标题 #### 四级标题 -
效果如下:
-—————————————————————-
一级标题
二级标题
三级标题
四级标题
-—————————————————————-
段落
- 段落的换行是使用两个以上空格加上回车
- 在段落后面使用一个空行也可以表示重新开始一个段落
字体
- 标题标识符为#,标题级别用#数量表示,注意#与内容之间有一个空格,语法如下:
*斜体文本* _斜体文本_ **粗体文本** __粗体文本__ ***粗斜体文本*** ___粗斜体文本___ -
效果如下:
-—————————————————————-
斜体文本
斜体文本
粗体文本
粗体文本
粗斜体文本
粗斜体文本
-—————————————————————- - 公式
- 使用两个美元符 $$ 包裹 TeX 或 LaTeX 格式的数学公式来实现
- 服务端需要 Mathjax渲染
- 图例
- 使用mermaid
列表
- 无须列表
- 无须列表标识符号有*,-,+显示效果没啥区别,语法如下:
```markdown- 列表1
- 列表2
```
-
效果如下:
-—————————————————————-
- 列表1
- 列表2
-—————————————————————-
- 内容层次之间用tab分割,如下:
```markdown- 列表1
- 列表1.1
- 列表2
- 列表2.2
```
- 列表2.2
- 列表1
-
效果如下:
-—————————————————————-
- 列表1
- 列表1.1
- 列表2
- 列表2.2
-—————————————————————-
- 列表2.2
- 列表1
- 无须列表标识符号有*,-,+显示效果没啥区别,语法如下:
- 有序列表:
- 有序列表标识符为num.,num为阿拉伯数字,语法如下:
```markdown- 列表1
- 列表1.1
- 列表2
- 列表2.1
```
-
效果如下:
-—————————————————————-
- 列表1
- 列表1.1
- 列表2
- 列表2.1
-—————————————————————-
- 列表2.1
- 列表1
- 有序列表标识符为num.,num为阿拉伯数字,语法如下:
表格
- 语法如下:
| 表头 | 表头 | | ---- | ---- | | 单元格 | 单元格 | | 单元格 | 单元格 | -
效果如下:
-—————————————————————-
表头 表头 单元格 单元格 单元格 单元格 -—————————————————————-
- 对齐方式:
- -: 设置内容和标题栏居右对齐。
- :- 设置内容和标题栏居左对齐。
- :-: 设置内容和标题栏居中对齐。
超链接
- 链接可以是页内锚点或者超链接,锚点时需要配合使用标签,语法如下:
链接 [链接名称](链接地址) 或者 <链接地址> 这个链接用 1 作为网址变量 [Google][1] 这个链接用 runoob 作为网址变量 [Runoob][runoob] 然后在文档的结尾为变量赋值(网址) [1]: http://www.google.com/ [runoob]: http://www.runoob.com/ 锚点 <a name="标题"></a> [本节标题章节的锚点](#标题) -
效果如下:
-—————————————————————-
本节标题章节的锚点
-—————————————————————-
图片
- 标题标识符为#,标题级别用#数量表示,注意#与内容之间有一个空格,语法如下:
  -
效果如下:
-—————————————————————-

-—————————————————————-
代码
- 代码区块使用 4 个空格或者一个制表符(Tab 键); 也可以用 ``` 包裹一段代码,并指定一种语言,语法如下:
```python def say(): print("i am laowng") ``` -
效果如下:
-—————————————————————-
def say(): print("i am laowng")-—————————————————————-
区块
- 区块使用>作标识符号,语法如下:
> 区块1 > 区块2 >> 区块2.1 >>> 区块2.1.1 -
效果如下:
-—————————————————————-
区块1
区块2
区块2.1
区块2.1.1
-—————————————————————-��������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2021-10-12-分布式-Hbase部署.md����������������������������������������������������������0000664�0001750�0001750�00000043163�14133256135�022215� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post
title: Hbase分布式部署
subtitle: Haddoop+Zookeeper+Hbase
date: 2021-10-12
author: AnAn
header-img: /img/post-bg-article.jpg
catalog: true
tags:- Linux
- Hbase
- Zookeeper
-
Hadoop
介绍
使用群晖Docker 搭建Hbase分布式服务
命名分别为:
hdfs-master
hdfs-slave1
hdfs-slave2
hdfs-slave3
目录
前言
- rsync是个好东西,分布式同步太好用了,在网上Copy了一份xsync脚本,如下:
#!/bin/sh # 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount!=4)); then echo Usage: $0 filename servername startno endno exit; fi # 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname # 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir # 获取当前用户名称 user=`whoami` # 获取hostname及起止号 slave=$2 startline=$3 endline=$4 # 循环 for((host=$startline; host<=$endline; host++)); do echo $pdir/$fname $user@$slave$host:$pdir echo ==================$slave$host================== rsync -rvl $pdir/$fname $user@$slave$host:$pdir done
- 使用方式:
xsync filename servername startno endno | | | | |.-----终止主机号 | | | | | | | .--------------起始主机号 | | | | | .----------------------主机名前缀,需要提前认证公钥(ssh-copy-id serverName) | | | .----------------------------------可以是目录或者文件名 | .----------------------------------------命令,最好将xsync脚本加入环境变量 #主机命名规则为 servername+no 如hdfs-slave1 hdfs-slave2 - 使用xsync前需要安装rsync
- xcall用于分布式命令执行,脚本如下:
#!/bin/bash #获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount<4)); then echo Usage: $0 servername startno endno command exit; fi slave=$1 startline=$2 endline=$3 tmp=($@) params=${tmp[@]:3} echo $params user=`whoami` for((host=$startline; host<=$endline; host++)); do echo ==================$slave$host================== ssh $user@$slave$host "source /etc/profile;$params" done - 使用方式:
xcall servername startno endno command | | | | |.-----远程调用命令 | | | | | | | .--------------终止主机号 | | | | | .----------------------起始主机号 | | | .----------------------------------主机名前缀,需要提前认证公钥(ssh-copy-id serverName) | .----------------------------------------命令,最好将xsync脚本加入环境变量 #主机命名规则为 servername+no 如hdfs-slave1 hdfs-slave2
zookeeper分布式部署
- 解压zookeeper安装包
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /opt/software - 修改配置,配置文件路径为 apache-zookeeper-3.7.0-bin/conf/
cp conf/zoo_sample.cfg zoo.cfg vi conf/zoo.cfg ###以下为zoo.cfg中修改的内容 dataDir=/zookeeper/data #dataDir属性设置zookeeper的数据文件存放的目录 server.1=hdfs-master:2888:3888#增加 server.2=hdfs-slave1:2888:3888#增加 server.3=hdfs-slave2:2888:3888增加 server.4=hdfs-slave3:2888:3888增加 ###端口说明 #1、2181:对client端提供服务 #2、3888:选举leader使用 #3、2888:集群内机器通讯使用(Leader监听此端口) - 内容分发到其他机器
xsync hdfs-slave 1 3 /zookeeper/ - 设定各个机器的id
echo 1 > /zookeeper/data/myid ssh hdfs-slave1 "echo 2 > /zookeeper/data/myid" ssh hdfs-slave2 "echo 3 > /zookeeper/data/myid" ssh hdfs-slave3 "echo 4 > /zookeeper/data/myid" - 启动zookeeper
xcall hdfs-slave 1 3 /zookeeper/apache-zookeeper-3.7.0-bin/bin/zkServer.sh start - zookeeper客户端测试
/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkCli.sh
Hbase部署
- 解压Habse到/hadoop/hbase
tar -zxvf hbase-3.0.0-alpha-1.tar.gz -C /hadoop/hbase/ - 配置conf/hbase-env.sh
###一般ssh登陆只会加载~/.bashrc和~/.profile 而JAVA环境变量一般在/etc/profile或者/etc/bashrc中, ###所以要修改以下配置 export JAVA_HOME=/usr/local/jdk/jdk1.8.0_261#修改JAVA_HOME目录为有效目录 - 配置conf/habse-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://hdfs-master:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.tmp.dir</name> <value>${env.HBASE_HOME:-.}/tmp</value> </property> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.master.info.port</name> <value>16010</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hdfs-master,hdfs-slave1,hdfs-slave2,hdfs-slave3</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/zookeeper/apache-zookeeper-3.7.0-bin/conf</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> </configuration> - 修改regionservers内容如下
hdfs-master hdfs-slave1 hdfs-slave2 hdfs-slave3 - 启动hbase-master
/hadoop/hbase/hbase-3.0.0-alpha-1/bin/hbase-daemon.sh start master - 启动hbase-regionserver
#启动hdfs前需要先启动hdfs start-dfs.sh xcall hdfs-slave 1 3 /hadoop/hbase/hbase-3.0.0-alpha-1/bin/hbase-daemon.sh start regionserver - 启动后的效果如下:
[root@hdfs-master jdk]# xcall hdfs-slave 1 3 jps jps ==================hdfs-slave1================== 1714 Jps 738 QuorumPeerMain 1530 HRegionServer 78 DataNode ==================hdfs-slave2================== 1446 Jps 716 QuorumPeerMain 76 DataNode 1262 HRegionServer ==================hdfs-slave3================== 182 QuorumPeerMain 649 HRegionServer 828 Jps 415 DataNode - 备注
- 群关闭
- bin/stop-hbase.sh
- 群启动 - bin/start-hbase.sh
- 进入Hbase客户端,没反应的话多等一会儿,本来就比较慢bin/hbase shell
- Hbase-shell
- 创建表
hbase(main):002:0> create ‘student’,’info’ - 插入数据到表
hbase(main):003:0> put ‘student’,’1001’,’info:sex’,’male’
hbase(main):004:0> put ‘student’,’1001’,’info:age’,’18’
hbase(main):005:0> put ‘student’,’1002’,’info:name’,’Janna’
hbase(main):006:0> put ‘student’,’1002’,’info:sex’,’female’
hbase(main):007:0> put ‘student’,’1002’,’info:age’,’20’ - 扫描查看表数据
hbase(main):008:0> scan ‘student’
hbase(main):009:0> scan ‘student’,{STARTROW => ‘1001’, STOPROW =>
‘1001’}
hbase(main):010:0> scan ‘student’,{STARTROW => ‘1001’} - 查看表结构
hbase(main):011:0> describe ‘student’ - 更新指定字段的数据
hbase(main):012:0> put ‘student’,’1001’,’info:name’,’Nick’
hbase(main):013:0> put ‘student’,’1001’,’info:age’,’100’ - 查看“指定行”或“指定列族:列”的数据
hbase(main):014:0> get ‘student’,’1001’
hbase(main):015:0> get ‘student’,’1001’,’info:name’ - 统计表数据行数
hbase(main):021:0> count ‘student’ - 删除数据
删除某 rowkey 的全部数据:
hbase(main):016:0> deleteall ‘student’,’1001’
删除某 rowkey 的某一列数据:
hbase(main):017:0> delete ‘student’,’1002’,’info:sex’ - 清空表数据
hbase(main):018:0> truncate ‘student’
提示: 清空表的操作顺序为先 disable,然后再 truncate。 - 删除表
首先需要先让该表为 disable 状态:
hbase(main):019:0> disable ‘student’
然后才能 drop 这个表:
hbase(main):020:0> drop ‘student’
提示: 如果直接 drop 表,会报错: ERROR: Table student is enabled. Disable it first. - 变更表信息
将 info 列族中的数据存放 3 个版本:
hbase(main):022:0> alter ‘student’,{NAME=>’info’,VERSIONS=>3}
hbase(main):022:0> get
‘student’,’1001’,{COLUMN=>’info:name’,VERSIONS=>3} - 查看put的帮助信息
hbase:031:0> help “put”
Put a cell ‘value’ at specified table/row/column and optionally
timestamp coordinates. To put a cell value into table ‘ns1:t1’ or ‘t1’
at row ‘r1’ under column ‘c1’ marked with the time ‘ts1’, do:
hbase> put ‘ns1:t1’, ‘r1’, ‘c1’, ‘value’
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’, ts1
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’, {ATTRIBUTES=>{‘mykey’=>’myvalue’}}
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’, ts1, {ATTRIBUTES=>{‘mykey’=>’myvalue’}}
hbase> put ‘t1’, ‘r1’, ‘c1’, ‘value’, ts1, {VISIBILITY=>’PRIVATE|SECRET’}
The same commands also can be run on a table reference. Suppose you had a reference
t to table ‘t1’, the corresponding command would be:
hbase> t.put ‘r1’, ‘c1’, ‘value’, ts1, {ATTRIBUTES=>{‘mykey’=>’myvalue’}} �������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������_posts/2021-10-13-生活-护眼壁纸.md������������������������������������������������������������0000664�0001750�0001750�00000002051�14133252221�022421� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post
title: 分享一张护眼壁纸
subtitle: 也叫近距离远眺图
date: 2021-10-13
author: AnAn
header-img: /img/life-bg/nature1.jpeg
catalog: true
tags:
- Life
—
介绍
-
有专家研究证明,近视主要是因为长期近距离用眼,导致近视不断增重
-
科学用眼的一项就是不要长时间盯着近距离物体,比如电脑屏幕,最好能够半小时进行一次远眺
-
本次分享下边的近距离远眺壁纸,让你不需要远离电脑就可以放松眼睛
-
使用时仔细看中心的E,由于大脑的视觉欺骗,会自然而然的放松眼睛
-
使用时用作桌面全屏壁纸或者直接全屏效果更好
-
高分辨率版本可在百度网盘获取
链接:https://pan.baidu.com/s/1KcweGxMUbYVTA10VtaQTWw 提取码:1y3i

_posts/2021-10-15-JAVA-进程间的通信.md��������������������������������������������������������0000664�0001750�0001750�00000071535�14137201421�022772� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: Java进程间的通信
subtitle: 进程通信
date: 2021-10-15
author: AnAn
header-img: /img/background.jpg
catalog: true
tags:
- Java
- 操作系统
—
介绍
- 进程间的通信在许多科技论坛的帖子上都已经说的很详细,主要有:共享内存,管道,信号量,信号,socket等通信方式
- 但题主又觉得他们说的不够详细,在什么场景下使用,如何使用,这是许多帖子没有说清楚的
目录
共享内存
- 说明
- java中没有专门的共享内存方法。 MappedByteBuffer 是为了文件映射,加快大文件读写速度。 共享内存,有许多种实现方法,在java中可以使用文件映射来实现共享内存,缺点是文件映射必须有文件, 同时有其他开销。 文件映射的方式读写文件其实是对内存的操作,所以速度与读写内存是一致的, 多余的开销在内存数据还是会同步到硬盘的,这个开销是异步的,影响不大。
- MappedByteBuffer其实是利用了操作系统底层的虚拟内存技术,将需要的磁盘文件(空间),映射到内存中, 内存与磁盘的同步由操作系统负责,所以这种技术下,数据在多个进程之间有一定的同步延迟。
- 特点
- 可被多个进程打开访问;
- 读写操作的进程在执行读写操作时,其他进程不能进行写操作,这个需要在管理程序中自己实现;
- 多个进程可以交替对某一共享内存执行写操作;
- 一个进程执行内存写操作后,不影响其他进程对该内存的访问,同时其他进程对更新后的内存具有可见性;
- 说明 的言外之意是MappedByteBuffer并不能保证多个进程共享内存的强一致性
- 不要经常调用MappedByteBuffer.force()方法,这个方法强制操作系统将内存中的内容写入硬盘, 所以如果你在每次写内存映射文件后都调用force()(同步刷磁盘)方法,你就不能真正从内存映射文件中获益, 而是跟disk IO差不多
- 共享内存管理类MemShared.class
import java.io.File; import java.io.IOException; import java.io.RandomAccessFile; import java.nio.ByteBuffer; import java.nio.MappedByteBuffer; import java.nio.channels.FileChannel; import java.nio.channels.FileLock; public class MemShared { //第0-3个字节控制版本 // 4-7个字节为size,表示内存可写大小 // 第8-11个字节为position 当前读取内存获取写内存的位置 // 第12-15个字节为limit 当前内存最大可读取位置 // 以后为数据控制 //createMem(File file,int size)用于初始化共享内存,对应主要方法为initSharedMem() //getMem(File file)用于加载已经初始化共享内存,对应主要方法为setSharedMem() private MemShared(){ } private File file; private RandomAccessFile randomAccessFile; private FileChannel fc; private int off=16;//数据偏移量 private MappedByteBuffer map;//实际的操作内存 public File getFile() { return file; } public static int byteArrayToInt(byte[] bytes) {//字节转int int value=0; //由高位到低位 for (int i = 0; i < bytes.length; i++) { value |= bytes[i]; if(i<bytes.length-1) value <<= 8;//往高位游 } return value; } public int getSize() { byte[] bytes = new byte[4]; for (int i = 4; i <= 7; i++) { bytes[i-4]=this.map.get(i); } return byteArrayToInt(bytes); } public void setSize(int size) { for (int i = 7; i >= 4; i--) { int val = size & 0xFF; this.map.put(i,(byte)val); size>>=8; } } public int getLimit(){ byte[] bytes = new byte[4]; for (int i = 12; i <= 15; i++) { bytes[i-12]=this.map.get(i); } return byteArrayToInt(bytes); } public void setLimit(int limit){ for (int i = 15; i >= 12; i--) { int val = limit & 0xFF; this.map.put(i,(byte)val); limit>>=8; } } public int getVersion() { byte[] bytes = new byte[4]; for (int i = 0; i <= 3; i++) { bytes[i]=this.map.get(i); } return byteArrayToInt(bytes); } private void setVersion(int version){ for (int i = 3; i >= 0; i--) { int val = version & 0xFF; this.map.put(i,(byte)val); version>>=8; } } public int getPosition(){ byte[] bytes = new byte[4]; for (int i = 8; i <=11; i++) { bytes[i-8]=this.map.get(i); } return byteArrayToInt(bytes); } public void setPosition(int position){ for (int i = 11; i >= 8; i--) { int val = position & 0xFF; this.map.put(i,(byte)val); position>>=8; } } static MemShared createMem(File file,int size,int version) throws IOException { MemShared memShared = new MemShared(); memShared.file=file; memShared.initSharedMem(size,version); return memShared; } static MemShared createMem(File file,int size) throws IOException { return createMem(file,size,0); } static MemShared getMem(File file) throws IOException { MemShared memShared = new MemShared(); memShared.file=file; memShared.setSharedMem(); return memShared; } private void setSharedMem() throws IOException { //获取随机存取文件对象,建立文件和内存的映射,即时双向同步 this.randomAccessFile=new RandomAccessFile(file,"rw"); this.fc = this.randomAccessFile.getChannel(); byte[] bytes = new byte[4]; this.fc.read(ByteBuffer.wrap(bytes),4); int size=byteArrayToInt(bytes); this.map = fc.map(FileChannel.MapMode.READ_WRITE, 0, size); } private void initSharedMem(int size,int version) throws IOException { //获取随机存取文件对象,建立文件和内存的映射,即时双向同步 this.randomAccessFile=new RandomAccessFile(file,"rw"); this.fc = this.randomAccessFile.getChannel(); this.map = this.fc.map(FileChannel.MapMode.READ_WRITE, 0, this.off+size); this.map.put((byte) 0); this.setVersion(version); this.setPosition(0); this.setSize(size); } public void flip(){ this.setPosition(0); } public void write(byte[] bytes) throws Exception { FileLock lock = fc.lock(); if (bytes.length>getSize()) throw new Exception("bytes.length>getSize()"); this.map.put(bytes); this.setLimit(bytes.length); lock.release(); } public void write(byte b) throws Exception { FileLock lock = fc.lock(); int position = getPosition(); if (position>=getSize()-1) throw new Exception("positoin超出内存大小"); this.map.put(++position+this.off,b); this.setPosition(position); lock.release(); } public byte get(int position) throws Exception { if (position>=getLimit())throw new Exception("position>=getLimit()"); return this.map.get(position+this.off); } public byte get(){ return this.map.get(getPosition()+this.off); } public void getBytes(byte[] bytes){ this.map.get(bytes); } } - 共享内存创建NIOWrite.class
import java.io.File; public class NIOWrite { public static void main(String[] args) throws Exception { File file = new File("/home/wangwen/Memshared"); MemShared mem = MemShared.createMem(file, 2048); int cur=0; for (int i = 0; i < 10; i++) { mem.write((byte) cur); int position = mem.getPosition(); byte b = mem.get(position); System.out.println("index:"+position+" "+b); cur=b+1; Thread.sleep(1000); } } } /*结果 index:1 0 index:2 1 index:3 2 index:4 3 index:5 4 index:7 5 index:9 6 index:11 7 index:13 8 index:15 9*/ - 共享内存读取NIORead.class
import java.io.File; public class NIORead { public static void main(String[] args) throws Exception { File file = new File("/home/wangwen/Memshared"); MemShared mem = MemShared.getMem(file); int cur; for (int i = 0; i < 10; i++) { int position = mem.getPosition(); byte b = mem.get(position); System.out.println("index:"+position+" "+b); cur=b+1; mem.write((byte) cur); Thread.sleep(1000); } } } /*结果 index:5 4 index:7 5 index:9 6 index:11 7 index:13 8 index:15 9 index:16 10 index:17 11 index:18 12 index:19 13 */ - 备注 先运行NIOWrite.class,再运行NIORead.class
管道
- 说明
管道是进程间通信的一种重要方式,linux的bash shell中“|”就是管道的意思, 管道分为无名管道和有名管道,前者只能用于具有亲缘关系的进程之间使用 从管道读数据是一次性操作,数据一旦被读,它就从管道中被抛 弃,释放空间以便写更多的数据 - Linux管道的实现机制
- 本质上说,管道也是一种虚拟的文件,在程序中表现为文件句柄。它是一个固定大小的缓冲区 在写管道时可能变满,当这种情况发生时,随后对管道的write()调用将默认地被阻塞,等待 某些数据被读取,以便腾出足够的空间供write()调用写;读取进程也可能工作得比写进程快。当所有当前进程数据已被读取时, 管道变空。当这种情况发生时,一个随后的read()调用将默认地被阻塞。
- 无名管道:主要用于父进程与子进程之间,或者两个兄弟进程之间。在linux系统中可以通过系统调用建立起一个单向的通信管道,且这种关系只能由父进程来建立。
- 命名管道:命名管道是建立在实际的磁盘介质或文件系统(而不是只存在于内存中)上有自己名字的文件,任何进程可以在任何时间通过文件名或路径名与该文件建立联系。 为了实现命名管道,引入了一种新的文件类型——FIFO文件(遵循先进先出的原则)。实现一个命名管道实际上就是实现一个FIFO文件。 命名管道一旦建立,之后它的读、写以及关闭操作都与普通管道完全相同。虽然FIFO文件的inode节点在磁盘上,但是仅是一个节点而已,文件的数据还是存在于内存缓冲页面中,和普通管道相同。
- 管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。 管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大一般为4K大小,它被设计成为环形的数据结构,以便管道可以被循环利用。 当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。 当两个进程都终结的时候,管道也自动消失。
- Java使用管道通讯
- 很不幸Java没有提供管道通信API。。。。。
- 使用FileInputStream和FileOutStream可以模拟实现有名管道,配合MapedByteBuffer和队列结构, 可以实现管道的功能,但是该功能借助真实磁盘文件同步信息,信息的同步会有延迟
- 下边使用Runtime,ProcessBuilder模拟实现匿名管道
Runtime rt = Runtime.getRuntime(); Process process = rt.exec("cmd"); ProcessBuilder pb = new ProcessBuilder("exeProcess", "param"); Process p = pb.start(); - 以Main.java作为父进程
package com.laowng.msg.pipe; import java.io.*; public class Pipe { public static void main(String[] args) throws IOException, InterruptedException { Runtime rt = Runtime.getRuntime(); Process a = rt.exec(new String[]{"java","-classpath","/home/laowng/IdeaProjects/algrithm/out/production/algrithm","com.laowng.msg.pipe.A"}); //ProcessBuilder A = new ProcessBuilder("java", "com.laowng.msg.pipe.A"); //Process a = A.start(); System.out.println("启动主类"); InputStream aPipInStream = a.getInputStream(); OutputStream aPipOutStream = a.getOutputStream(); InputStream aerrorStream = a.getErrorStream(); BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(aPipOutStream)); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(aPipInStream)); //检查错误流 StringBuilder res= new StringBuilder(); byte[] bytes = new byte[1024]; int read; Thread.sleep(100); int available = aerrorStream.available(); if(available>0) { while ((read = aerrorStream.read(bytes)) != -1) res.append(new String(bytes, 0, read)); System.out.println(res); }else {//脚本正常运行 System.out.println("[a]接受消息<------:"+bufferedReader.readLine()); for (int i = 0; i < 10; i++) { String msg=""+i; System.out.println("[a]发送消息------>:"+msg); bufferedWriter.write(msg); bufferedWriter.newLine(); bufferedWriter.flush(); String s = bufferedReader.readLine(); System.out.println("[a]接受消息<------:"+s); } } } }- A.class作为子进程
package com.laowng.msg.pipe; import java.io.*; public class A { public static void main(String[] args) throws IOException { System.out.println("[a]被调用成功!"); BufferedReader fatherPipInStream = new BufferedReader(new InputStreamReader(System.in)); BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(System.out)); //fatherPipOutStream使用sout实现 for (int i = 0; i < 10; i++) { String s = fatherPipInStream.readLine(); bufferedWriter.write("[a]收到了"+s); bufferedWriter.newLine(); bufferedWriter.flush(); } } } - Main的执行结果
启动主类 [a]接受消息<------:[a]被调用成功! [a]发送消息------>:0 [a]接受消息<------:[a]收到了0 [a]发送消息------>:1 [a]接受消息<------:[a]收到了1 [a]发送消息------>:2 [a]接受消息<------:[a]收到了2 [a]发送消息------>:3 [a]接受消息<------:[a]收到了3 [a]发送消息------>:4 [a]接受消息<------:[a]收到了4 [a]发送消息------>:5 [a]接受消息<------:[a]收到了5 [a]发送消息------>:6 [a]接受消息<------:[a]收到了6 [a]发送消息------>:7 [a]接受消息<------:[a]收到了7 [a]发送消息------>:8 [a]接受消息<------:[a]收到了8 [a]发送消息------>:9 [a]接受消息<------:[a]收到了9 - 这种捕获子进程输入输出流的方式可以模拟实现匿名管道,并且如果把父进程作为管道管理进程(种转输入输出流), 可以实现兄弟进程间的管道流传输。
- A.class作为子进程
信号量
- 信号量(英语:semaphore)又称为信号标,是一个同步对象,用于保持在0至指定最大值之间的一个计数值。 当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一;当线程完成一次对semaphore对象的释放(release)时, 计数值加一。当计数值为0,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态。 semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态。
-
信号量的概念是由荷兰计算机科学家艾兹赫尔·戴克斯特拉(Edsger W. Dijkstra)发明的, 广泛的应用于不同的操作系统中。在系统中,给予每一个进程一个信号量,代表每个进程目前的状态, 未得到控制权的进程会在特定地方被强迫停下来,等待可以继续进行的信号到来。如果信号量是一个任意的整数, 通常被称为计数信号量(Counting semaphore),或一般信号量(general semaphore);如果信号量只有二进制的0或1, 称为二进制信号量(binary semaphore)。
-
java线程的状态
状态 说明 初始(NEW) 新创建了一个线程对象,但还没有调用start()方法。 运行(RUNNABLE) Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。 阻塞(BLOCKED) 表示线程阻塞于锁。 等待(WAITING) 进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。 超时等待(TIMED_WAITING) 该状态不同于WAITING,它可以在指定的时间后自行返回。 终止(TERMINATED) 表示该线程已经执行完毕。 - Thread.sleep(long millis),一定是当前线程调用此方法,当前线程进入TIMED_WAITING状态,但不释放对象锁,millis后线程自动苏醒进入就绪状态。作用:给其它线程执行机会的最佳方式。
- Thread.yield(),一定是当前线程调用此方法,当前线程放弃获取的CPU时间片,但不释放锁资源,由运行状态变为就绪状态,让OS再次选择线程。作用:让相同优先级的线程轮流执行,但并不保证一定会轮流执行。实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。Thread.yield()不会导致阻塞。该方法与sleep()类似,只是不能由用户指定暂停多长时间。
- t.join()/t.join(long millis),当前线程里调用其它线程t的join方法,当前线程进入WAITING/TIMED_WAITING状态,当前线程不会释放已经持有的对象锁。线程t执行完毕或者millis时间到,当前线程进入就绪状态。
- obj.wait(),当前线程调用对象的wait()方法,当前线程释放对象锁,进入等待队列。依靠notify()/notifyAll()唤醒或者wait(long timeout) timeout时间到自动唤醒。
- obj.notify()唤醒在此对象监视器上等待的单个线程,选择是任意性的。notifyAll()唤醒在此对象监视器上等待的所有线程。
- java进程的状态 与操作系统相关,但一般与线程状态一致,区别是信号量由操作系统管理,线程的信号量由JVM进程管理。
信号
- 对于 Linux来说,实际信号是软中断,许多重要的程序都需要处理信号。信号,为 Linux 提供了一种处理异步事件的方法。比如,终端用户输入了 ctrl+c 来中断程序,会通过信号机制停止一个程序。
- 每个信号都有一个名字和编号,这些名字都以“SIG”开头
laowng@laowng-ThinkCentre-M8600t-N000:~$ kill -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAX3.信号的处理: 信号的处理有三种方法,分别是:忽略、捕捉和默认动作
- 忽略信号,大多数信号可以使用这个方式来处理,但是有两种信号不能被忽略(分别是 SIGKILL和SIGSTOP)。因为他们向内核和超级用户提供了进程终止和停止的可靠方法,如果忽略了,那么这个进程就变成了没人能管理的的进程,显然是内核设计者不希望看到的场景
- 捕捉信号,需要告诉内核,用户希望如何处理某一种信号,说白了就是写一个信号处理函数,然后将这个函数告诉内核。当该信号产生时,由内核来调用用户自定义的函数,以此来实现某种信号的处理。
- 系统默认动作,对于每个信号来说,系统都对应由默认的处理动作,当发生了该信号,系统会自动执行。
First the signals described in the original POSIX.1-1990 standard. Signal Value Action Comment ────────────────────────────────────────────────────────────────────── SIGHUP 1 Term Hangup detected on controlling terminal or death of controlling process SIGINT 2 Term Interrupt from keyboard SIGQUIT 3 Core Quit from keyboard SIGILL 4 Core Illegal Instruction SIGABRT 6 Core Abort signal from abort(3) SIGFPE 8 Core Floating-point exception SIGKILL 9 Term Kill signal SIGSEGV 11 Core Invalid memory reference SIGPIPE 13 Term Broken pipe: write to pipe with no readers; see pipe(7) SIGALRM 14 Term Timer signal from alarm(2) SIGTERM 15 Term Termination signal SIGUSR1 30,10,16 Term User-defined signal 1 SIGUSR2 31,12,17 Term User-defined signal 2 SIGCHLD 20,17,18 Ign Child stopped or terminated SIGCONT 19,18,25 Cont Continue if stopped SIGSTOP 17,19,23 Stop Stop process SIGTSTP 18,20,24 Stop Stop typed at terminal SIGTTIN 21,21,26 Stop Terminal input for background process SIGTTOU 22,22,27 Stop Terminal output for background process The signals SIGKILL and SIGSTOP cannot be caught, blocked, or ignored.
socket通信
- Socket可以看成在两个程序进行通讯连接中的一个端点(endpoint),一个程序将一段信息写入Socket中,该Socket将这段信息发送给另外一个Socket中,使这段信息能传送到其他程序中。一般一个server服务器对应很多客户端client连接,服务器必须维护一张客户连接列表,每增加一个客户端连接服务器端都要新建一个套接字负责与新增客户端进行对话通信。
- 传输套接字主要有两类:流式套接字(SOCK_STREAM)和数据报套接字(SOCK_DGRAM)。流类型的套接字是为需要可靠连接的应用程序设计的。这些程序通常使用连续的数据流。用于这种类型套接字的协议是TCP,适合FTP这类实现。流套接字是最常用的,一些众所周知的协议如HTTP、TCP、SMTP、POP3等都是基于面向流的协议。
-
数据报套接字使用UDP做为下层协议,是无连接的,有一个最大缓冲区大小(数据包大小的最大值)。它是为那些需要发送小数据包,并且对可靠性要求不高的应用程序设计的。与流式套接字不同,数据报套接字并不保证数据会到达终端,也不保证它是以正确的顺序到来的。数据报套接字的传输效率相当高,它经常用于音频或视频应用程序。对这些程序来说,速度比可靠性更加重要。
- 下边的案例是copy的,写的挺好
- IP地址使用InetAddress类来表示,获取InetAddress实例的两个方法为:
- getByName(String host) 根据主机获取对应的InetAddress对象
- getByAddress(byte[] addr)根据IP地址获取InetAddress对象
- InetAddress提供了三个方法来获取InetAddress实例对应的IP地址和主机名
- String getCanonicalHostName()获取此IP地址的权限定域名
- String getHostAddress()获取InetAddress实例对应的IP地址
- String getHostName()获取此IP地址的主机名
- 服务端代码
import java.net.*; import java.io.*; /** 手机端代码 手机端作为服务器,获取自己的ip地址,并显示以供客户端连接 */ public class phone_Server { public static void main(String[] args) throws IOException { //打印本机的IP地址 InetAddress address=InetAddress.getLocalHost(); System.out.println("本机的IP地址是"+address.getHostAddress()); // 创建一个ServerSocket,用于监听客户端Socket的连接请求 ServerSocket ss = new ServerSocket(30000); // 采用循环不断接受来自客户端的请求 while (true) { // 每当接受到客户端Socket的请求,服务器端也对应产生一个Socket Socket s = ss.accept(); // 将Socket对应的输出流包装成PrintStream PrintStream ps = new PrintStream(s.getOutputStream()); // 进行普通IO操作 ps.println("您好,您收到了服务器的新年祝福!"); // 关闭输出流,关闭Socket ps.close(); s.close(); } } } - 客户端代码
/** PC端代码 PC作为客户端,根据服务器的IP地址和端口号连接服务器 */ import java.net.*; import java.io.*; public class PC_Client { public static void main(String[] args) throws IOException { //Socket socket = new Socket("127.0.0.1" , 30000); Socket socket = new Socket("192.168.47.1" , 30000);//这里的IP地址填写手机端服务器的IP地址 // 将Socket对应的输入流包装成BufferedReader BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream())); // 进行普通IO操作 String line = br.readLine(); System.out.println("来自服务器的数据:" + line); // 关闭输入流、socket br.close(); socket.close(); } } - socket大数据发送
//发送 DataOutputStream out = new DataOutputStream(socket.getOutputStream()); int start=0; while((start+1024)<data.length) { out.write(data, start,1024); start=start+1024; } if(start<data.length) { out.write(data, start,(data.length-start+1)); } //String str = new String(data); //out.writeUTF(str); }catch (Exception e) { Log.d(TAG, "文件传输异常"); } - socket大数据接受
//接收 DataInputStream input = new DataInputStream(socket.getInputStream()); byte []buf=new byte[1024]; int readnum=0; while(true) { readnum=input.read(buf); if(readnum>0) { System.out.println(Arrays.toString(buf)); while((readnum=input.read(buf))>0) { System.out.println(Arrays.toString(buf)); } } }
- IP地址使用InetAddress类来表示,获取InetAddress实例的两个方法为:
_posts/2021-10-16-Springboot-Springboot可视化监控.md�������������������������������������������0000664�0001750�0001750�00000001002�14132174546�025262� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: Springboot可视化监控
subtitle: Springboot可视化监控
date: 2021-10-16
author: AnAn
header-img: /img/life-bg/nature1.jpeg
catalog: true
tags:
- Java
- Springboot
- Spring
—
介绍
- 工作中,生产环境往往不止一条,在本地频繁切换或者搭建环境往往效率底下
- JDWP提供了一种远程调试java的方案
目录
_posts/2021-10-20-Python-JupyterNoteBook.md���������������������������������������������������������0000664�0001750�0001750�00000007620�14134217014�020212� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������—
layout: post
title: JupyterNotebook
subtitle: Python JupyterNotebook
date: 2021-10-20
author: AnAn
header-img: /img/life-bg/nature1.jpeg
catalog: true
tags:
- Python
—
介绍
- Jupyter(聆听i/ˈdʒuːpɪtər/)是一个非营利组织,旨在“为数十种编程语言的交互式计算开发开源软件, 开放标准和服务”。2014年由Fernando Pérez从IPython中衍生出来,Jupyter支持几十种语言的执行环境。 Jupyter Project的名称是对Jupyter支持的三种内核编程语言的引用,这三种语言是Julia、Python和R, 也是对伽利略记录发现木星的卫星的笔记本的致敬。Jupyter项目开发并支持交互式计算产品Jupyter Notebook、JupyterHub和JupyterLab, 这是Jupyter Notebook的下一代版本。
- Jupyter Notebook(前身是IPython Notebook)是一个基于Web的交互式计算环境,用于创建Jupyter Notebook文档。 Notebook一词可以通俗地引用许多不同的实体,主要是Jupyter Web应用程序、Jupyter Python Web服务器或Jupyter文档格式 (取决于上下文)。Jupyter Notebook文档是一个JSON文档,遵循版本化模式,包含一个有序的输入/输出单元格列表, 这些单元格可以包含代码、文本(使用Markdown语言)、数学、图表和富媒体 (Rich media),通常以“.ipynb”结尾扩展。 Jupyter Notebook文档可以通过Web界面中的“Download As”,通过nbconvert库或shell中的“jupyter nbconvert”命令行界面, 转换为许多的开源标准输出格式(HTML、演示幻灯片、LaTeX、PDF、reStructuredText、Markdown、Python)。 为了简化Jupyter Notebook文档在Web上的可视化,nbconvert库是通过nbviewer提供的一项服务,它可以获取任何公开可用的Notebook文档的URL, 将其动态转换为 HTML 并显示给用户。
目录
jupyerNotebook安装,及升级服务
- jupyter notebook 是一个交互式的python编辑器,一般用于程序远程执行,调试。多用于服务器
- 如果使用conda环境安装jupyter 建议使用
conda install nb_conda - 使用这个命令会自动安装jupyter notebook等依赖,并且在web端可灵活切换管理conda环境(直接使用pip安装jupyter 还需要安装ipykernel 才能管理环境)
- 对于jupyer notebook 修改密码,网上教程较为复杂,以下为笔记:
jupyter notebook --generate-config #生成jupyter notebook 配置文件 #配置文件的位置会显示在终端,一般位于/home/uesername/.jupyter/jupyter_notebook_config.py jupyter notebook password #该命令将生成用户输入密码的sha256密钥 #密钥一般存放于 /home/uesername/.jupyter/jupyter_notebook_config.json 文件 #文件内p="密钥" #将密钥复制,粘贴于jupyter_notebook_config.py,使c.NotebookApp.password='密钥' #如果需要监听全局ip,需要使c.NotebookApp.ip='0.0.0.0' c.NotebookApp.allow_remote_access = True #记得将修改处变量前的“#”删去,使更改生效 - 将jupyter升级为系统服务(ubuntu systemd)
- jupyter-start.sh
#!/bin/bash ### su snnu -c "" 不能这样写,systemd会跟踪不到子进程 sudo -u snnu nohup /home/snnu/anaconda3/bin/python -m jupyter notebook --port 8888 --no-browser --notebook-dir '~/' 1>>/dev/null 2>> /home/snnu/jupyter.service/error.log & - /lib/systemd/system/autojupyter.service
[Unit] Description=jupyter notebook service After=network.target [Service] ExecStart=/home/snnu/jupyter.service/jupyter-start.sh ExecReload=/bin/kill -HUP $MAINPID KillMode=control-group Restart=on-failure Type=forking [Install] WantedBy=multi-user.target Alias=jupyter.service
_posts/2021-11-10-分布式-Nginx笔记.md����������������������������������������������������������0000664�0001750�0001750�00000037246�14144351170�022262� 0����������������������������������������������������������������������������������������������������ustar �wangwen�������������������������wangwen����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������— layout: post title: Nginx笔记 subtitle: Nginx笔记 date: 2021-11-10 author: AnAn header-img: /img/post-bg-article.jpg catalog: true tags: - Nginx —
介绍
以下学习笔记来自于尚硅谷的Nginx课程
目录
前言
-
说明 Nginx(发音同“engine X”)是异步框架的网页服务器,也可以用作反向代理、负载平衡器和HTTP缓存。 该软件由伊戈尔·赛索耶夫(Игорь Сысоев)创建并于2004年首次公开发布。2011年成立同名公司以提供支持。 2019年3月11日,Nginx公司被F5 Networks以6.7亿美元收购。
- 常用命令
nginx -v #查看版本号 nginx #启动 nginx -s stop #关闭 nginx -s reload #重新加载 - 默认配置文件
-
nginx.conf
user nginx; worker_processes auto;#工作进程数 error_log /var/log/nginx/error.log notice; pid /var/run/nginx.pid; events { worker_connections 1024;#最大连接数 } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; sendfile on; #tcp_nopush on; keepalive_timeout 65; #gzip on; include /etc/nginx/conf.d/*.conf; } -
conf.d/default.conf
server { listen 80; listen [::]:80; server_name localhost; #access_log /var/log/nginx/host.access.log main; location / { root /usr/share/nginx/html; index index.html index.htm; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # #location ~ \.php$ { # proxy_pass http://127.0.0.1; #} # pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000 # #location ~ \.php$ { # root html; # fastcgi_pass 127.0.0.1:9000; # fastcgi_index index.php; # fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; # include fastcgi_params; #} # deny access to .htaccess files, if Apache's document root # concurs with nginx's one # #location ~ /\.ht { # deny all; #} }
-
反向代理
- 正向代理:代理服务的配置内容在客户端,比如http代理 socks5 vemss,代理端后置于客户端
- 反向代理:代理的配置在服务端,对用户透明,代理端前置于真实服务器


{kind=link}